[論文レビュー] Automated, LLM enabled extraction of synthesis details for reticular materials from scientific literature
この論文は、prompt-engineered、in-context learningを用いたopen-source LLMsを活用して、PDFから網状材料の合成プロトコルを自動抽出するKnowledge Extraction Pipeline(KEP)を提案し、ファインチューニングなしで、段落分類と情報抽出タスクを対象に5つのLLMファミリを比較します。
Automated knowledge extraction from scientific literature can potentially accelerate materials discovery. We have investigated an approach for extracting synthesis protocols for reticular materials from scientific literature using large language models (LLMs). To that end, we introduce a Knowledge Extraction Pipeline (KEP) that automatizes LLM-assisted paragraph classification and information extraction. By applying prompt engineering with in-context learning (ICL) to a set of open-source LLMs, we demonstrate that LLMs can retrieve chemical information from PDF documents, without the need for fine-tuning or training and at a reduced risk of hallucination. By comparing the performance of five open-source families of LLMs in both paragraph classification and information extraction tasks, we observe excellent model performance even if only few example paragraphs are included in the ICL prompts. The results show the potential of the KEP approach for reducing human annotations and data curation efforts in automated scientific knowledge extraction.
研究の動機と目的
- 文献からのリティカル材料(MOFs、ZIFs、COFs、zeolites)の合成プロトコルデータベースを迅速に構築する動機づけ。
- ファインチューニングやトレーニングを要しないドメイン非依存のKEPを開発する。
- ICLを用いたプロンプト設計が、PDFから化学合成の詳細を取得し、幻覚リスクを低減できることを実証する。
- 複数のオープンソースLLMファミリにおける段落分類と情報抽出の両方での性能を評価する。
- プロンプトにおける例の選択がモデルの成功に与える影響と、注釈作業の負担を低減することを強調する。
提案手法
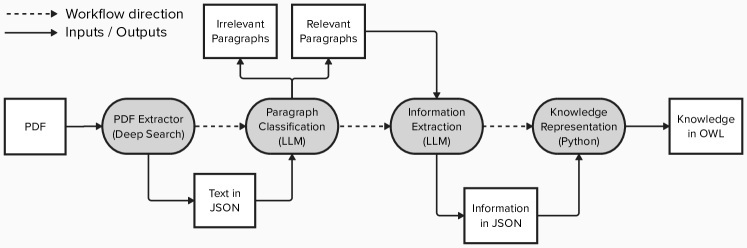
- 4モジュールからなるKnowledge Extraction Pipeline (KEP)を導入する:PDF抽出器、段落分類、情報抽出、知識表現。
- DS4SDを用いてPDFをJSON様の文書要素に変換する(OCRによる画像PDFも含む)。
- 少数ショットの例を用いた prompting- engineered ICL を適用し、段落を合成関連かどうか(S vs I)に分類する。
- プロンプト駆動のJSON注釈を適用して、合成の詳細(生成物、条件、反応物、溶媒)を抽出し、構造化された知識表現にマッピングする。
- 各モデルとタスクのパフォーマンスを最大化するために、最適なプロンプト例を選択するExample選択フェーズを実施する。
実験結果
リサーチクエスチョン
- RQ1ファインチューニングなしのオープンソースLLMは、PDFからリティカル材料の合成について高精度な段落分類と情報抽出を実現できるか?
- RQ2さまざまなLLMファミリにおけるプロンプト例の選択がモデルの性能にどのように影響するか?
- RQ3科学文献からの合成プロトコルの自動知識抽出を最も支援するのはどのLLMとプロンプト戦略か?
主な発見
- Five LLM families (Flan, Granite, LLaMA, Mistral, Mixtral) は、タスク特化のファインチューニングなしで高い性能を達成した。
- 段落分類では、多くのモデルが最良のプロンプトでF1スコア0.84を超え、いくつかは0.98に達した(例:llama-3-70b-instruct、mistral-large)。
- 情報抽出では、トップモデルが最大0.96の精度を達成(例:llama-3-1 405b-instruct)、プロンプトには2つの例段落のみを使用。
- 結果は、プロンプト例の選択が性能に大きく影響し、より大きなモデルが必ずしも優れた結果を保証しないことを示している。
- 提案されたKEPは、 SMEの注釈作業とデータキュレーションを削減しつつ、非構造化PDFからの合成プロトコルの自動抽出を可能にする。

より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。