[論文レビュー] Automatic acoustic detection of birds through deep learning: the first Bird Audio Detection challenge
公的データチャレンジが、深層学習で未知の音響条件下でも高い汎用的鳥検出を達成できることを示しており、トップのAUCは約88%で、多様なデータセットにわたる強い汎化を示した。
Assessing the presence and abundance of birds is important for monitoring specific species as well as overall ecosystem health. Many birds are most readily detected by their sounds, and thus passive acoustic monitoring is highly appropriate. Yet acoustic monitoring is often held back by practical limitations such as the need for manual configuration, reliance on example sound libraries, low accuracy, low robustness, and limited ability to generalise to novel acoustic conditions. Here we report outcomes from a collaborative data challenge showing that with modern machine learning including deep learning, general-purpose acoustic bird detection can achieve very high retrieval rates in remote monitoring data --- with no manual recalibration, and no pre-training of the detector for the target species or the acoustic conditions in the target environment. Multiple methods were able to attain performance of around 88% AUC (area under the ROC curve), much higher performance than previous general-purpose methods. We present new acoustic monitoring datasets, summarise the machine learning techniques proposed by challenge teams, conduct detailed performance evaluation, and discuss how such approaches to detection can be integrated into remote monitoring projects.
研究の動機と目的
- 遠隔音響モニタリングにおいて、種特有の調整や環境特有の較正なしで、堅牢で汎用的な鳥検出を動機づける。
- 遠隔モニタリングとクラウドソースの情報源から多様な注釈付きデータセットを作成し、汎化を評価する。
- 一般的で曖昧な検出タスクをAUCで評価して、ベースラインとディープラーニング手法をベンチマークする。
- 実世界のモニタリンググリッドでの展開を促進するため、検出器の較正と誤分類のタイプを分析する。
提案手法
- 複数ソースのデータセットを組み立て(チェルノブイリCEZ、Warblrクラウドソース、freefield1010、PolandNFC)、鳥あり/なしラベルを付けた10秒クリップを注釈する。
- 一般的な検出タスクを定義する:各10秒クリップを鳥の有無としてラベル付けし、±10秒の正確な時間的局在化を可能にする。
- 参加者に開発データを提供し、過学習を防ぐためのプライベートテストデータと、汎化テスト用の別データセットを提供する。
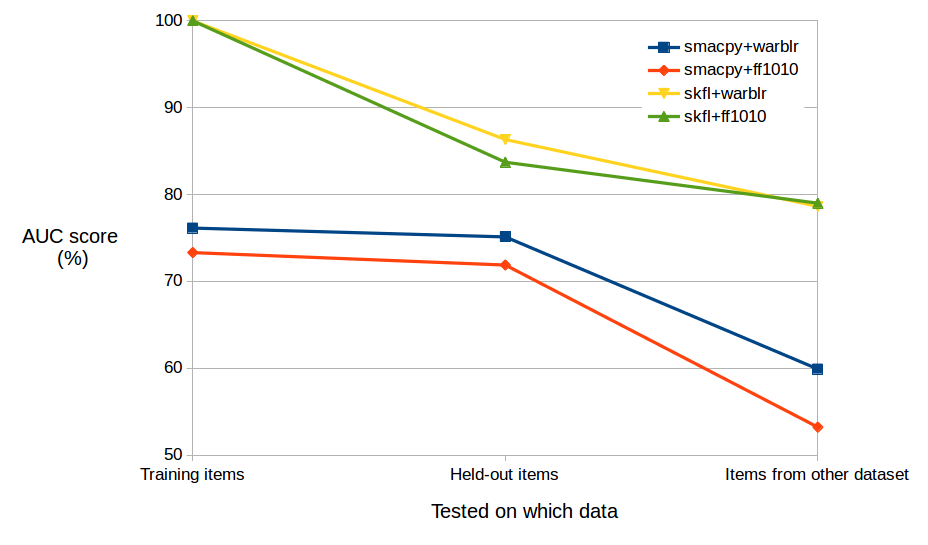
- ベースライン分類器:smacpy(MFCCとガウス混合モデル)とskfl(メルスペクトログラムの教師なし特徴学習とランダムフォレスト)。
- 参加者は、スペクトログラム(メル)入力とデータ拡張を用いた深層学習手法(しばしばCNN)を採用し、出力はAUCを算出する確率スコアであった。
- 未知条件とサイト間の汎化、ならびに較正プロットによる較正分析に焦点を当てた評価。
実験結果
リサーチクエスチョン
- RQ1一般的で汎用的な種に依存しない検出器が、環境特有の調整なしに高い鳥検出性能を達成できるか?
- RQ2検出手法は、未知の音響環境やデータ源へどの程度汎化するか?
- RQ3深層学習ベースの検出器の較正特性は何か、サイト間でどう異なるか(例:Warblr対チェルノブイリ)。
- RQ4難所記録(低SNR、風、昆虫ノイズ、人間の活動)で検出を制限する一般的な誤り源は何か?
主な発見
- 深層学習手法は高い性能を達成し、ほとんどのチームが80%以上のAUCを超え、最高得点は88.7%のAUCに達した。
- 再検証済みテストセットでの評定者間信頼性は高く(AUC 96.7%)、再検証プロトコル下で人間と機械の判断の実質的な一致を示した。
- サイトごとに性能が異なり、Warblrデータは容易に検出(AUC > 95%)、一部CEZ地点はより難しく、主要手法で約80%のAUCまで低下。
- 検出の較正はデータセットによって異なり、上位の手法の中には見られたデータで良い較正を示す一方、未見のCEZデータでの較正が悪いものもあり、展開時には別個の考慮事項として較正が重要であることを示した。
- ほとんどの提出はスペクトログラム/メル表現とデータ拡張を用い、CNNベースの深層学習手法が上位を占めた。
- 最も強力な検出器はサイト別分析でも堅牢な汎化傾向を示し続けたが、サイトごとに評価すると正確な順位は異なる場合があった。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。