[論文レビュー] AutoProteinEngine: A Large Language Model Driven Agent Framework for Multimodal AutoML in Protein Engineering
AutoProteinEngineは、LLM駆動のエージェントフレームワークを用いてタンパク質設計のマルチモーダルAutoMLを実行し、分類および回帰タスクでゼロショットおよび手動で調整されたベースラインを上回します。
Protein engineering is important for biomedical applications, but conventional approaches are often inefficient and resource-intensive. While deep learning (DL) models have shown promise, their training or implementation into protein engineering remains challenging for biologists without specialized computational expertise. To address this gap, we propose AutoProteinEngine (AutoPE), an agent framework that leverages large language models (LLMs) for multimodal automated machine learning (AutoML) for protein engineering. AutoPE innovatively allows biologists without DL backgrounds to interact with DL models using natural language, lowering the entry barrier for protein engineering tasks. Our AutoPE uniquely integrates LLMs with AutoML to handle model selection for both protein sequence and graph modalities, automatic hyperparameter optimization, and automated data retrieval from protein databases. We evaluated AutoPE through two real-world protein engineering tasks, demonstrating substantial performance improvements compared to traditional zero-shot and manual fine-tuning approaches. By bridging the gap between DL and biologists' domain expertise, AutoPE empowers researchers to leverage DL without extensive programming knowledge. Our code is available at https://github.com/tsynbio/AutoPE.
研究の動機と目的
- 自然言語インターフェースを通じて非DL専門の生物学者がDLモデルを使用できるようにし、タンパク質設計のエントリーバリアを下げる。
- タンパク質配列とグラフモダリティのモデル選択を自動化し、ハイパーパラメータ最適化と公開データベースからのデータ取得を自動化する。
- 実世界のタンパク質タスクでゼロショットおよび手動調整ベースラインより高い性能を示す。
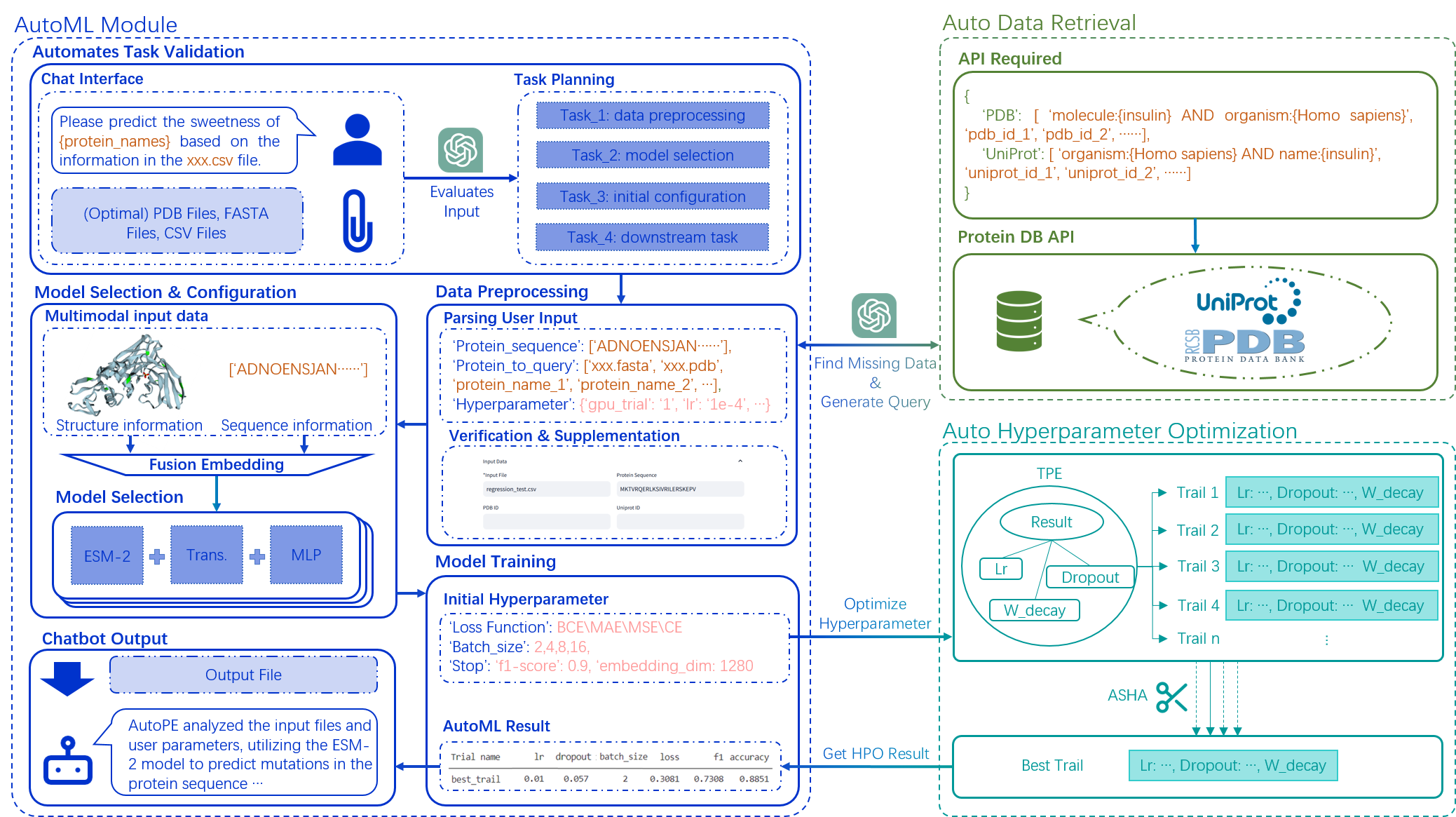
提案手法
- タスクを検証し、データ前処理を計画し、事前定義された zoo(例:ESM、AlphaFold)からモデルを選択し、トレーニングを設定するLLM駆動AutoMLパイプライン。
- 補完情報を活用するためのマルチモーダル(配列とグラフ)タンパク質データの遅延融合。
- 自然言語対話に導かれた、Tree-structured Parzen Estimator (TPE)とASHAを用いる自動ハイパーパラメータ最適化(Ray.Tune経由)。
- LLM生成クエリに導かれたUniProtとPDBからの自動データ取得。データが欠如した場合のフォールバック対話を備える。
- 指標をユーザーフレンドリーな要約に翻訳する、対話的な自然言語フィードバックで解釈性を向上。
実験結果
リサーチクエスチョン
- RQ1配列とグラフデータを含むタンパク質エンジニアリングタスクに対して、LLM駆動エージェントフレームワークは効果的なマルチモーダルAutoMLを実現できるか。
- RQ2LLMによって導かれる自動ハイパーパラメータ最適化は、ゼロショットおよび手動調整ベースラインより性能を向上させるか。
- RQ3タンパク質データベースからの自動データ取得が、タンパク質設計のDLモデル訓練を支える上でどれほど効果的か。
主な発見
| Method | F1-score | SRCC | Accuracy |
|---|---|---|---|
| Zero-Shot | 0.4764 ± 0.11 | 0.3769 ± 0.05 | 0.6917 ± 0.04 |
| Manual Fine-Tuning | 0.5709 ± 0.05 | 0.3098 ± 0.06 | 0.9137 ± 0.01 |
| AutoPE (w/o HPO) | 0.6396 ± 0.06 | 0.4405 ± 0.04 | 0.7988 ± 0.05 |
| AutoPE (w/ HPO) | 0.7306 ± 0.04 | 0.4621 ± 0.03 | 0.8908 ± 0.01 |
- 自動HPO付きAutoPEは、タスク全体で性能とロバスト性の最良のトレードオフを達成し、ゼロショットおよび非HPOバリアントを上回る。
- Brazzein甘味分類では、AutoPE w/HPOがF1 0.7306、SRCC 0.4621、精度 0.8908 を達成し、ゼロショットおよびw/o-HPOバリアントより高い。
- STM1221酵素活性回帰では、AutoPE w/HPOがRMSE 0.3488、MAE 0.1999、R2 0.6805 を達成し、ゼロショットおよびw/o-HPOバリアントを上回る。
- Manual fine-tuning は高い精度を得られる場合があるが、F1とロバスト性では劣ることがある。HPO付きのAutoPEは、より良いバランスと一般化可能性を提供。
- このフレームワークはマルチモーダルデータ融合と自動データ取得をサポートし、専門的なDL知識の必要性を低減する。

より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。