[論文レビュー] AutoRT: Embodied Foundation Models for Large Scale Orchestration of Robotic Agents
AutoRT 系は視覚-言語モデルと language model を用いて現実世界のロボットの fleet を指揮し、多様なデータ収集を実現します。7か月で20台以上のロボットに渡る77kエピソードを達成し、混合自律と遠隔操作を組み合わせます。
Foundation models that incorporate language, vision, and more recently actions have revolutionized the ability to harness internet scale data to reason about useful tasks. However, one of the key challenges of training embodied foundation models is the lack of data grounded in the physical world. In this paper, we propose AutoRT, a system that leverages existing foundation models to scale up the deployment of operational robots in completely unseen scenarios with minimal human supervision. AutoRT leverages vision-language models (VLMs) for scene understanding and grounding, and further uses large language models (LLMs) for proposing diverse and novel instructions to be performed by a fleet of robots. Guiding data collection by tapping into the knowledge of foundation models enables AutoRT to effectively reason about autonomy tradeoffs and safety while significantly scaling up data collection for robot learning. We demonstrate AutoRT proposing instructions to over 20 robots across multiple buildings and collecting 77k real robot episodes via both teleoperation and autonomous robot policies. We experimentally show that such "in-the-wild" data collected by AutoRT is significantly more diverse, and that AutoRT's use of LLMs allows for instruction following data collection robots that can align to human preferences.
研究の動機と目的
- 実験室外の大規模な現実世界ロボットデータ収集の必要性を動機づける。
- ファウンデーションモデルを用いてロボット群でタスクを計画・地上化・実行するシステムを提案する。
- 安全性制約の下で自律ポリシーと人間の遠隔操縦者による混合監督を可能にする。
- 複数の建物での実世界展開と大規模データ収集を実証する。
- AutoRT を介して収集したデータが下流のロボット学習モデルを改善することを示す。
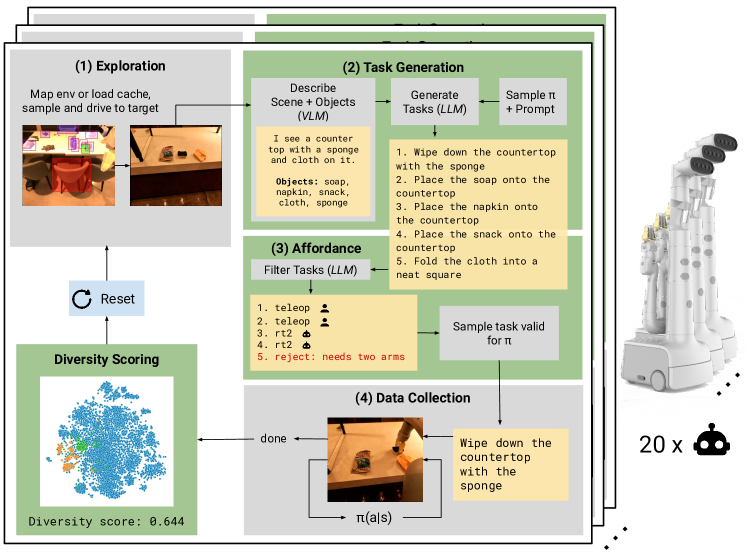
提案手法
- シーンを記述し物体を地上化するビジョン-言語モデルを使用する。
- scene description から多様で新規な操作タスクを生成する大規模言語モデルを活用する。
- 安全性と embodiment のルールを用いてタスク提案を制約するロボット憲章(constitution)を適用する。
- L L M が現実的なタスクとポリシーを批評・選択するアフォーダンスフィルタリングを組み込む。
- 複数の収集ポリシー(遠隔操作、スクリプト付きピック、RT-2)を監督制約の下でロボット群と連携させる。
- 生成タスクの多様性と実現可能性を評価し、RT-1 モデルのファインチューニングへのデータ有用性を示す。
実験結果
リサーチクエスチョン
- RQ1 embodied foundation-model-driven システムは 複数台のロボットで現実世界のデータ収集をスケールさせられるのか?
- RQ2LLMs は視覚観察に grounding された安全で実現可能かつ多様な操作タスクをどれだけ効果的に生成できるのか?
- RQ3ロボット憲章とアフォーダンス prompting はタスクの安全性と関連性にどう影響するのか?
- RQ4AutoRT データは RT-1 のような下流のロボット学習モデルにどのような影響を与えるのか?
- RQ5混合監督下の野外データ収集のスループット、多様性、安全性の特徴は?
主な発見
| 収集ポリシー | #エピソード | 成功率 |
|---|---|---|
| スクリプトポリシー | 73293 | 21% |
| 遠隔操作 | 3060 | 82% |
| RT-2 | 936 | 4.7% |
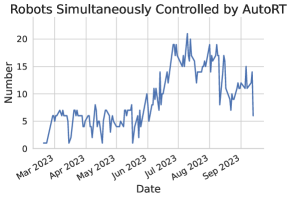
- AutoRT は 7 か月で 53 台のロボットにわたり 4 棟のビルで 77,000 の現実世界エピソードを収集した。
- 単一の人間が 3–5 台のロボットを監督し、スケーラブルな展開を可能にした。
- 遠隔操作は最高のタスク成功率(82%)を生み出す一方、スクリプトポリシーが最も頻繁に使用された(73,293 エピソード)。
- RT-2 の自律は収集中に低い成功率を示した(4.7%)、訓練データとのドメインシフトを反映。
- AutoRT データはベースラインより言語・視覚の多様性が高く、生成データは RT-1 の性能を改善する可能性がある(高さの選択、拭き取りなど)。
- 憲章的 prompting と自己反省に基づくアフォーダンスフィルタリングは提案タスクの安全性と実現性を向上させた。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。