[論文レビュー] Balancing Specialized and General Skills in LLMs: The Impact of Modern Tuning and Data Strategy
本論文は、ドメイン内データと一般データをバランス良く組み合わせてLLMsを微調整する枠組み、機能的に関連するタスクのための45問評価、そしてモデルサイズと継続的トレーニングが性能に与える影響の分析を提示する。
This paper introduces a multifaceted methodology for fine-tuning and evaluating large language models (LLMs) for specialized monetization tasks. The goal is to balance general language proficiency with domain-specific skills. The methodology has three main components: 1) Carefully blending in-domain and general-purpose data during fine-tuning to achieve an optimal balance between general and specialized capabilities; 2) Designing a comprehensive evaluation framework with 45 questions tailored to assess performance on functionally relevant dimensions like reliability, consistency, and business impact; 3) Analyzing how model size and continual training influence metrics to guide efficient resource allocation during fine-tuning. The paper details the design, data collection, analytical techniques, and results validating the proposed frameworks. It aims to provide businesses and researchers with actionable insights on effectively adapting LLMs for specialized contexts. We also intend to make public the comprehensive evaluation framework, which includes the 45 tailored questions and their respective scoring guidelines, to foster transparency and collaboration in adapting LLMs for specialized tasks.
研究の動機と目的
- マネタイズに焦点を当てたLLMsにおいて、一般言語スキルとドメイン特化能力のバランスを取る課題に対処する。
- 監視付きファインチューニング中に、一般データとドメイン内データを混ぜたデータバランス戦略を提案する。
- 信頼性・一貫性・ビジネス影響を評価するための45問からなる総合評価フレームワークを開発する。
- モデルサイズと継続的トレーニングが性能に与える影響を分析し、資源配分の効率化を導く。
提案手法
- 監視付きファインチューニング中に、一般データとドメイン内データを組み合わせて、一般的な能力を保持しつつドメインスキルを強化するデータ結合手法。
- コサイン学習率スケジュール、0.1のウェイトデケイ、2048トークンのシーケンス長、モデルサイズに依存したバッチサイズを含む監視付きファインチューニング設定。
- 一般およびドメイン内タスクを網羅する厳選した45問のセットを用いたテスト推論モジュールによる総合評価。
- 明快さ、正確さ、完全性、安全性、具体性、配慮、丁寧さ、総合性能の8カテゴリを動的加重で評価するスコアリングフレームワーク。
- 性能への影響を検討する継続的トレーニング実験(1–5エポック)と、透明性のためのオープンソース評価フレームワーク。
- データプライバシー対策と公開ソースおよび製品/サービスデータからのデータ融合により、バランスの取れた学習コーパスを作成。
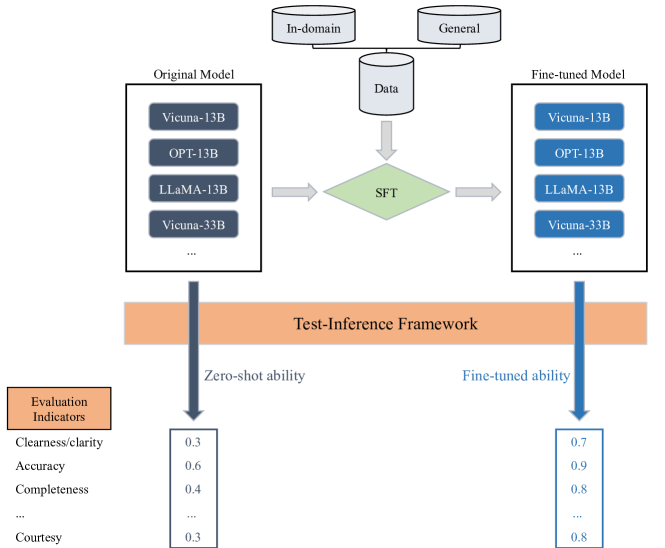
実験結果
リサーチクエスチョン
- RQ1ドメイン内のマネタイズデータを一般データと組み合わせて、一般的な言語スキルとドメイン特化能力のバランスをどう取るか。
- RQ2モデルサイズと継続的トレーニングが、専門化されたLLMsの評価指標に与える影響は何か。
- RQ345問評価フレームワークは、標準ベンチマークよりビジネス影響をより正確に捉える。
- RQ4データバランス戦略は、信頼性、一貫性、実用的なビジネス成果にマネタイズ文脈でどのような影響を与えるか。
主な発見
| モデル | 明快さ | 正確さ | 完全性 | 簡潔さ | 安全性 | 具体性 | 配慮 | 丁寧さ | 総合スコア |
|---|---|---|---|---|---|---|---|---|---|
| Vicuna-13b-v1.1 | 0.785 | 0.707 | 0.781 | 0.911 | 0.820 | 0.726 | 1.00 | 0.922 | 0.820 |
| Vicuna-13b-v1.3 | 0.915 | 0.644 | 0.633 | 0.952 | 1.00 | 0.926 | 0.989 | 1.00 | 0.828 |
| Llama-2-13b | 0.904 | 0.763 | 0.663 | 0.967 | 0.967 | 0.867 | 1.00 | 1.00 | 0.856 |
| Vicuna-33b-v1.3 | 0.937 | 0.718 | 0.730 | 0.970 | 1.00 | 1.00 | 1.00 | 1.00 | 0.869 |
- ドメインデータとアウトオブドメインデータの混合は、一般的な熟練度を維持しつつ専門的な有用性を向上させる。
- 総合的な45問評価フレームワークは、標準ベンチマークよりビジネス影響をより正確に捉える。
- 継続的トレーニングとモデルスケーリングは評価指標にニュアンスのある影響を及ぼし、資源配分を導く。
- 大規模モデルは通常、能力が強い一方で、エポックとモデルバリアントに応じて簡潔さと完全性のトレードオフが生じる。
- Vicuna-13b-v1.3 は特定の指標で v1.1 より改善する傾向がある一方、Llama-2-13b および Vicuna-33b-v1.3 はカテゴリごとに異なる強みを示す。
- 本研究は、複数のSFT-trainedモデルにわたる八カテゴリスコアと総合性能を示すベンチマークを提供する。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。