[論文レビュー] Bambi: A simple interface for fitting Bayesian linear models in Python
Bambi は Python ベースの、式に基づくインターフェースを提供し、PyMC の上にベイズ的一般化線形混合モデルを適合させ、回帰、ロジスティック、および階層モデルを含む仕様、適合、診断、予測を容易にする。
The popularity of Bayesian statistical methods has increased dramatically in recent years across many research areas and industrial applications. This is the result of a variety of methodological advances with faster and cheaper hardware as well as the development of new software tools. Here we introduce an open source Python package named Bambi (BAyesian Model Building Interface) that is built on top of the PyMC probabilistic programming framework and the ArviZ package for exploratory analysis of Bayesian models. Bambi makes it easy to specify complex generalized linear hierarchical models using a formula notation similar to those found in R. We demonstrate Bambi's versatility and ease of use with a few examples spanning a range of common statistical models including multiple regression, logistic regression, and mixed-effects modeling with crossed group specific effects. Additionally we discuss how automatic priors are constructed. Finally, we conclude with a discussion of our plans for the future development of Bambi.
研究の動機と目的
- GLMM の適合障壁を下げることで、ベイズ法の広範な普及を促進する。
- R の lme4 に似た直感的な式ベースのインターフェースを提供し、複雑なモデルを指定できるようにする。
- PyMC と ArviZ との統合により、ベイズモデルの効率的なサンプリング、診断、可視化を実現する。
- 複数回帰、ロジスティック回帰、ランダム効果を持つ階層モデルなど、例を通じて汎用性を示す。
- デフォルトの事前分布、推論ワークフロー、Bambi パッケージの今後の開発について論じる。
提案手法
- PyMC と ArviZ をベースにしたベイズ GLMM のための Python パッケージ(Bambi)を導入する。
- R に似た公式インターフェースを使い、Model クラスで固定効果とランダム効果を指定する。
- 後方サンプリングには適応的動的ヘルマンモンテカルロを採用し、診断のために複数の連鎖を実行する。
- 未指定時にはデフォルトの事前分布を提供し、plot_priors() によって事前分布を検査する仕組みを備える。
- Family クラスを介してさまざまなファミリー(Gaussian、Bernoulli など)とリンク関数をサポートする。
- .predict() メソッドと ArviZ の可視化を通じて後方予測チェックと予測を可能にする。
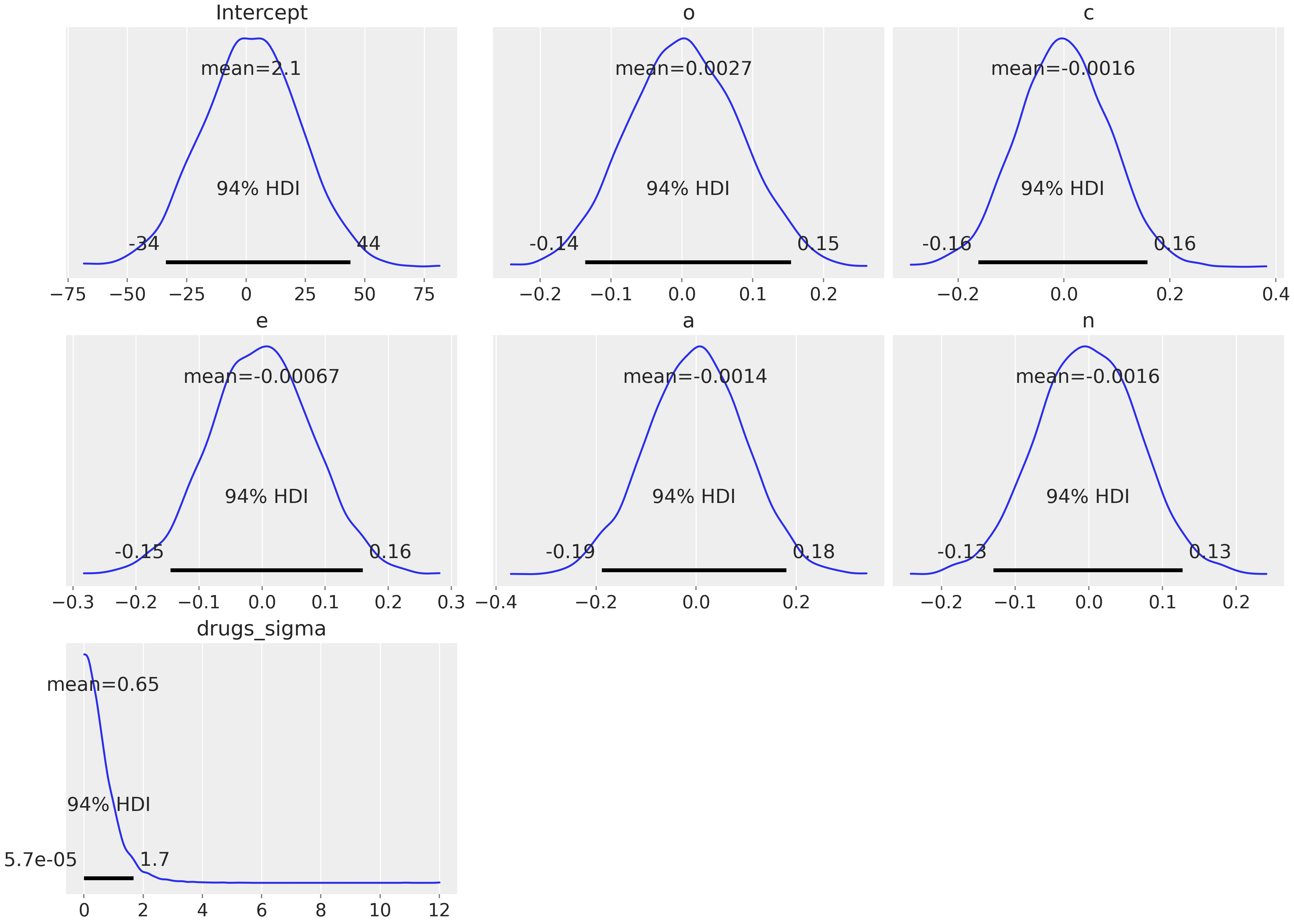
実験結果
リサーチクエスチョン
- RQ1式風のインターフェースを用いて、ベイズ一般化線形混合モデルを Python でいかに便利に指定できるか?
- RQ2Bambi でデフォルトとして使用される事前分布は何で、ユーザーはそれをどのようにカスタマイズできるか?
- RQ3Gaussian、Bernoulli などの異なるファミリーに対して、モデルの適合、診断、後方予測チェックを Bambi はどのように支援するか?
- RQ4交差ランダム効果を持つ複雑な階層モデルをユーザーは簡単に実行し、モデル出力を検査できるか?
- RQ5事後不確実性を伴うインサンプルおよびアウトオブサンプル予測を行うワークフローはどうなるか?
主な発見
- Bambi は実用的なデフォルトと馴染みのある式構文で GLMM の迅速な指定と適合を可能にする。
- このパッケージは PyMC の適応的動的ヘンリオンモンテカルロを活用して結合后分布からサンプルを取得する。
- ユーザーは ArviZ を介して事前分布、診断、後方要約を検査でき、トレースプロットや要約統計を含む。
- .predict() 関数は新しいデータに対して後方平均予測および後方予測サンプルを生成する。
- 複数のランダム効果(切片と傾き)を持つ階層モデルを、カスタム事前分布で指定・適合できる。
- 例は回帰、ロジスティック回帰、交差したランダム効果を示し、使いやすさとモデリングの柔軟性を示す。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。