[論文レビュー] Bayesian Recurrent Neural Networks
本論文は Bayes by Backprop を RNNs に適用し、posterior sharpening を導入し、不確実性推定を伴う言語モデリングと画像キャプション生成の性能向上を示す。
In this work we explore a straightforward variational Bayes scheme for Recurrent Neural Networks. Firstly, we show that a simple adaptation of truncated backpropagation through time can yield good quality uncertainty estimates and superior regularisation at only a small extra computational cost during training, also reducing the amount of parameters by 80\%. Secondly, we demonstrate how a novel kind of posterior approximation yields further improvements to the performance of Bayesian RNNs. We incorporate local gradient information into the approximate posterior to sharpen it around the current batch statistics. We show how this technique is not exclusive to recurrent neural networks and can be applied more widely to train Bayesian neural networks. We also empirically demonstrate how Bayesian RNNs are superior to traditional RNNs on a language modelling benchmark and an image captioning task, as well as showing how each of these methods improve our model over a variety of other schemes for training them. We also introduce a new benchmark for studying uncertainty for language models so future methods can be easily compared.
研究の動機と目的
- 重みの不確実性を捉えるために、RNNsのトレーニングに直接的な variational Bayes 手法(BBB)を導入する。
- KL正則化を伴う後方推定を得るために切り詰められた BPTT に適用する。
- 勾配情報を用いてバッチごとに局所的に事後を適応させる posterior sharpening を提案する。
- 言語モデリングと画像キャプション生成のタスクで従来の正則化より性能が向上することを示す。
- 言語モデルの不確実性に関する新しいベンチマークを提供する。
提案手法
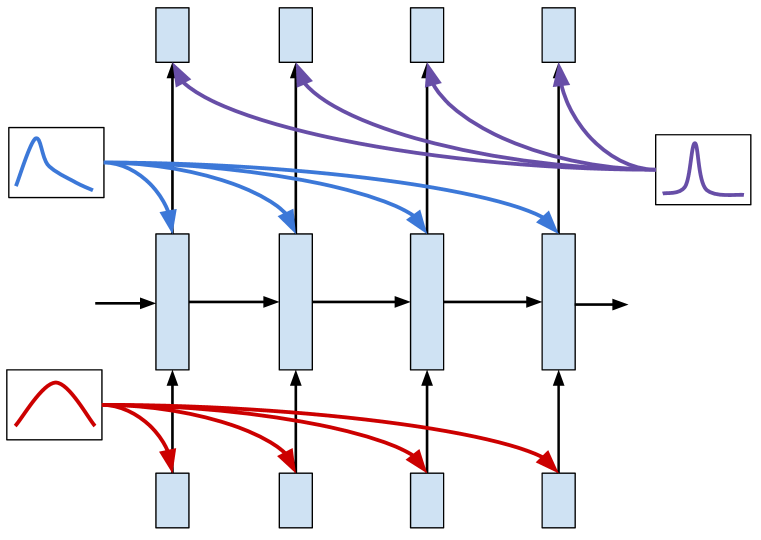
- 対角共分散を持つガウス事後分布から重みをサンプルして RNNs に Bayes by Backprop を適用する。
- 切り詰められた BPTT を持つ RNNs のために変分自由エネルギーを導出し、KL コストを minibatch およびシーケンス区間に分配する。
- posterior sharpening を導入する: バッチの勾配情報を用いて theta を調整する階層的 posterior q(theta|varphi,(x,y))。
- sharpened posterior q(theta|varphi,(x,y)) を theta = varphi - eta * grad_theta log p(y|varphi,x) でパラメータ化し、eta を学習する。
- モンテカルロ推定で訓練し、訓練目的関数に KL 正則化項を含める。
- 言語モデリング(Penn Treebank)と画像キャプション生成(MSCOCO)のベンチマークで、ベースラインの正則化技法より改善を示す。
実験結果
リサーチクエスチョン
- RQ1Bayes by Backprop を RNNs に適用することは、標準的な正則化と比較して予測性能とモデルキャリブレーションを改善するか。
- RQ2posterior sharpening は勾配分散を減らし、ベイズ感のある RNN の学習を改善できるか。
- RQ3Bayesian RNNs は言語モデリングと画像キャプション生成タスクで、既存のベイズ法や非ベイズ法と比較してどの程度性能を発揮するか。
- RQ4分布外データ上での Bayes RNN の不確実性特性はどうなるか。
- RQ5提案手法は RNN 以外の他のニューラルアーキテクチャにも一般化できるか。
主な発見
- BBB を用いた Bayesian RNNs は Penn Treebank で dropout ベースラインと競合する困惑度を達成する。
- Posterior sharpening は標準の BBB よりも困惑度を低下させ、キャリブレーションを改善する。
- BBB は MSCOCO の画像キャプション生成指標(BLUE-4, CIDEr)を Show and Tell ベースラインより改善する。
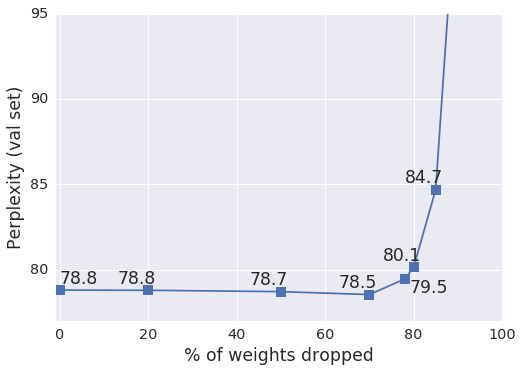
- 重みの剪定により、多くの重みを削除しても性能への影響は限定的(約80%程度)。
- BBB は不確実性推定を提供し、キャリブレーションを反映し、Entropy に基づく分析で MC-Dropout を上回る。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。