[論文レビュー] BEHAVIOR-1K: A Human-Centered, Embodied AI Benchmark with 1,000 Everyday Activities and Realistic Simulation
BEHAVIOR-1Kは、50シーンと9,000超のオブジェクトに基づく日常活動1,000件の人間中心ベンチマークをOmniGibsonで現実的な物理とレンダリングを実現し、長期的な具現化AIを研究する。論文はベースライン RL アプローチとシム・ツー・リアル転送ギャップを分析する。
We present BEHAVIOR-1K, a comprehensive simulation benchmark for human-centered robotics. BEHAVIOR-1K includes two components, guided and motivated by the results of an extensive survey on "what do you want robots to do for you?". The first is the definition of 1,000 everyday activities, grounded in 50 scenes (houses, gardens, restaurants, offices, etc.) with more than 9,000 objects annotated with rich physical and semantic properties. The second is OMNIGIBSON, a novel simulation environment that supports these activities via realistic physics simulation and rendering of rigid bodies, deformable bodies, and liquids. Our experiments indicate that the activities in BEHAVIOR-1K are long-horizon and dependent on complex manipulation skills, both of which remain a challenge for even state-of-the-art robot learning solutions. To calibrate the simulation-to-reality gap of BEHAVIOR-1K, we provide an initial study on transferring solutions learned with a mobile manipulator in a simulated apartment to its real-world counterpart. We hope that BEHAVIOR-1K's human-grounded nature, diversity, and realism make it valuable for embodied AI and robot learning research. Project website: https://behavior.stanford.edu.
研究の動機と目的
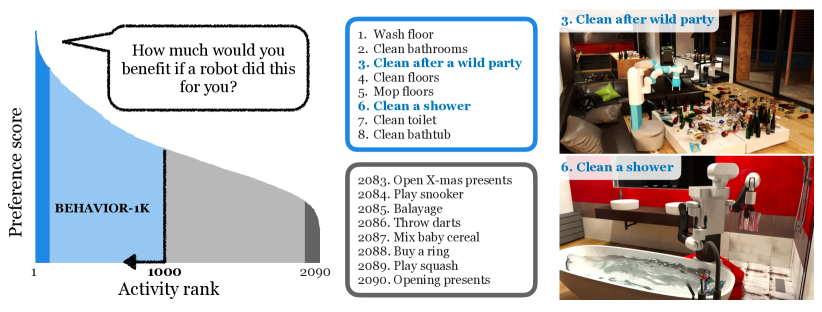
- 人間のニーズに基づく活動を、1,461名の参加者への調査を通じて日常タスクの高優先度を特定する。
- 50シーンと9,000以上の注釈付きオブジェクトモデルを含む多様なデータセットを作成し、1,000件の生態学的に妥当な活動をサポートする。
- 具現化AI研究のための剛体・変形・流体相互作用を可能にする現実的なシミュレーション環境 OmniGibson を開発する。
- BEHAVIOR-1Kにおける現在のRL能力とシム・ツー・リアル転送の課題を明らかにするベースライン評価を提供する。
提案手法
- 日常活動を robot に任せたい欲求でランク付けし、活動の定義を抽出する人間中心の調査を実施する。
- BDDL ロジックを用いて豊富な物理・意味論的アノテーションを持つ1,000件の活動・50シーン・9,000以上のオブジェクトモデルを含む BEHAVIOR-1K データセットを組み立てる。
- Nvidia Omniverse/PhysX 5 上で Fluid・Deformables・Textiles・拡張オブジェクト状態・遷移ルールをシミュレーションし、現実的なタスクの実現性を高める OmniGibson を開発する。
- スパース報酬下で視覚運動制御(RL-VMC)とアクションプリミット手法(RL-Prim, RL-Prim.Hist)を含む最先端RLベースラインをOmniGibsonで評価する。
- OmniGibson から現実の Tiago モバイルマニピュレータへ BEHAVIOR-1K シーンをマッピングし、ポリシーの性能と失敗モードを比較してシム・ツー・リアル転送を分析する。
実験結果
リサーチクエスチョン
- RQ1 laypeople による最も望まれる日常 activities は何か、そして人間のニーズをカバーするためにはシーン/オブジェクトはどれくらい多様であるべきか。
- RQ2現実的なシミュレーションで BEHAVIOR-1K の活動を現在の embodied AI 手法で解けるか、主なボトルネックは何か。
- RQ3OmniGibson から現実のモバイルマニピュレータへポリシーを転送した場合の BEHAVIOR-1K のシム・ツー・リアルギャップはどれくらいか。
- RQ4長期的で操作が豊富なタスクにおける性能を制限する要素(知覚・計画・把握・ダイナミクス)の中で最重要なのはどれか。
主な発見
| Method | Policy Features | StoreDecoration | CollectTrash | CleanTable |
|---|---|---|---|---|
| RL-VMC | No | 0.0 | 0.0 | 0.0 |
| RL-Prim. | Yes | 0.48±0.06 | 0.42±0.02 | 0.77±0.08 |
| RL-Prim.Hist. | Yes | 0.55±0.05 | 0.63±0.03 | 0.88±0.02 |
- BEHAVIOR-1K の活動は長期的で高度な操作を要し、現状のAIシステムにとって挑戦的である。
- 記憶を伴うアクションプリミット(RL-Prim.Hist)はエンドツーエンドの視覚運動制御よりも長いタスクで成功率が高い。
- 把握と物理ベースの正確な実行が重要であり、訓練時のこれらを単純化すると評価性能が大きく変化する。
- OmniGibson は競合シミュレータより視覚的リアリズムが高く、より信じられるセンサ入力を提供するが、認識とアクチュエーションの差異に起因するシム・ツー・リアルのギャップを大きく生む。
- 現実のロボット研究は、認識とナビゲーションの不一致を主要なシム・ツー・リアルの源として明らかにし、現実的なシミュレーションにもかかわらず把握に関する現実世界の難しさが顕著である。
- 多様で人間に基づく活動と高忠実度のシミュレーションの組み合わせは、具現化AIとロボット学習の進歩の余地が大きいことを示している。

より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。