[論文レビュー] Benchmarking Large Language Models for News Summarization
論文はニュース要約のための十個のLLMを対象に包括的な人間評価を実施し、指示チューニングはモデルサイズよりゼロショット性能を大きく左右し、参照ベースの指標の限界を露呈する高品質なフリーランス要約を示す。
Large language models (LLMs) have shown promise for automatic summarization but the reasons behind their successes are poorly understood. By conducting a human evaluation on ten LLMs across different pretraining methods, prompts, and model scales, we make two important observations. First, we find instruction tuning, and not model size, is the key to the LLM's zero-shot summarization capability. Second, existing studies have been limited by low-quality references, leading to underestimates of human performance and lower few-shot and finetuning performance. To better evaluate LLMs, we perform human evaluation over high-quality summaries we collect from freelance writers. Despite major stylistic differences such as the amount of paraphrasing, we find that LMM summaries are judged to be on par with human written summaries.
研究の動機と目的
- LLMのゼロショットニュース要約性能に寄与する設計上の決定を特定する。
- モデル規模、 prompting、指示チューニングが要約品質に与える影響を評価する。
- LLM要約の標準的な参照ベースの指標の信頼性を評価する。
- LLM出力とフリーランス作家による高品質な人間要約を比較する。
- 将来のベンチマークのための高品質な評価データとリソースを提供する。
提案手法
- CNN/Daily MailおよびXSUMデータセット全体で十の多様なLLMを系統的に人間が評価する。
- 3つのアノテータ評価基準を使用:忠実度(二値)、一貫性(1–5)、関連性(1–5)。
- ゼロショットとファ few-shotプロンプトを比較し、微調整済みベースライン(Pegasus、BRIO)を含める。
- Upworkから高品質なフリーランス要約を募集し、人間レベルの性能と指標信頼性を評価する。
- 切り貼り操作の分類法によって抽出性と要約的スタイルを分析する。
- 18モデル設定と2データセットの評価データを公開する。
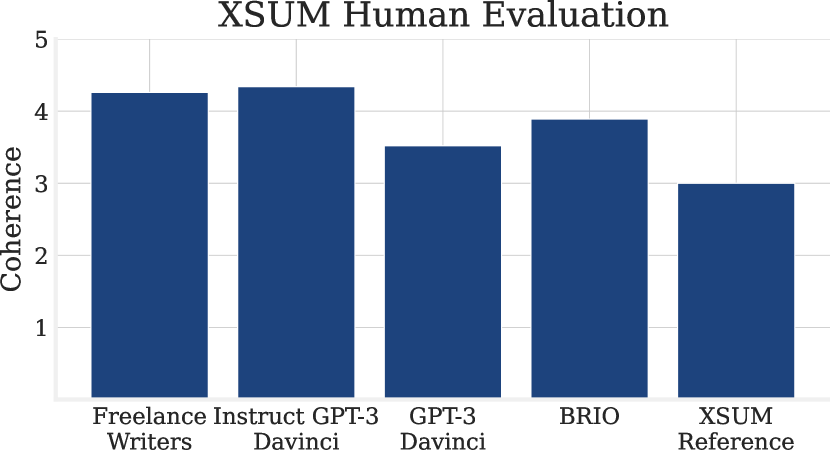
実験結果
リサーチクエスチョン
- RQ1指示チューニング済みLLMは、スケール重視で非指示チューニングのモデルよりゼロショットのニュース要約で優れているか?
- RQ2高品質な人間の参照は、LLMおよび微調整モデルの認識される性能と実際の性能にどのような影響を与えるか?
- RQ3CNN/DMとXSUMにわたる高品質なLLM出力を評価する際、参照ベースの自動指標は信頼できるか?
- RQ4LLM要約はフリーランス人間要約と忠実度・一貫性・情報量の点でどのように比較されるか?
主な発見
| Model | Faithfulness CNN/DM | Coherence CNN/DM | Relevance CNN/DM | Faithfulness XSUM | Coherence XSUM | Relevance XSUM |
|---|---|---|---|---|---|---|
| GPT-3 (350M) | 0.29 | 1.92 | 1.84 | 0.26 | 2.03 | 1.90 |
| GPT-3 (6.7B) | 0.29 | 1.77 | 1.93 | 0.77 | 3.16 | 3.39 |
| GPT-3 (175B) | 0.76 | 2.65 | 3.50 | 0.80 | 2.78 | 3.52 |
| Ada Instruct v1 (350M*) | 0.88 | 4.02 | 4.26 | 0.81 | 3.90 | 3.87 |
| Curie Instruct v1 (6.7B*) | 0.97 | 4.24 | 4.59 | 0.96 | 4.27 | 4.34 |
| Davinci Instruct v2 (175B*) | 0.99 | 4.15 | 4.60 | 0.97 | 4.41 | 4.28 |
| Anthropic-LM (52B) Five-shot | 0.94 | 3.88 | 4.33 | 0.70 | 4.77 | 4.14 |
| Cohere XL (52.4B) | 0.99 | 3.42 | 4.48 | 0.63 | 4.79 | 4.00 |
| GLM (130B) | 0.94 | 3.69 | 4.24 | 0.74 | 4.72 | 4.12 |
| OPT (175B) | 0.96 | 3.64 | 4.33 | 0.67 | 4.80 | 4.01 |
| GPT-3 (350M) – (repeat) | 0.86 | 3.73 | 3.85 | - | - | - |
| GPT-3 (6.7B) – (repeat) | 0.97 | 3.87 | 4.17 | 0.75 | 4.19 | 3.36 |
| GPT-3 (175B) – (repeat) | 0.99 | 3.95 | 4.34 | 0.69 | 4.69 | 4.03 |
| Ada Instruct v1 (350M*) – (repeat) | 0.84 | 3.84 | 4.07 | 0.63 | 3.54 | 3.07 |
| Curie Instruct v1 (6.7B*) – (repeat) | 0.96 | 4.30 | 4.43 | 0.85 | 4.28 | 3.80 |
| Davinci Instruct (175B*) – (repeat) | 0.98 | 4.13 | 4.49 | 0.77 | 4.83 | 4.33 |
| Brio (Fine-tuned) | 0.94 | 3.94 | 4.40 | 0.58 | 4.68 | 3.89 |
| Pegasus (Fine-tuned) | 0.97 | 3.93 | 4.38 | 0.57 | 4.73 | 3.85 |
| Existing references | 0.84 | 3.20 | 3.94 | 0.37 | 4.13 | 3.00 |
- 指示チューニングが、モデルサイズではなくゼロショット要約性能の主な推進力である。
- 最大規模型(例:175B)は、一貫性と関連性において、より小さな指示チューニングモデルに敗れることがある。
- XSUMの参照要約は人間によって最良のLLM出力よりも評価が低いと判断され、こうした参照の信頼性に疑問が生じる。
- フリーランスの作家はCNN/DMおよびXSUMのベースラインより高品質な参照を作成する;Instruct Davinciは多くの場合フリーランス作家と同等。
- より高品質な参照を用いると、Rouge-Lと人間の忠実性の相関がXSUMで改善する。
- LLMとフリーランス要約の好みにおいてアノテータ間で大きなばらつきがあり、主観的なスタイルの違いを示している。

より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。