[論文レビュー] Benchmarking LLM powered Chatbots: Methods and Metrics
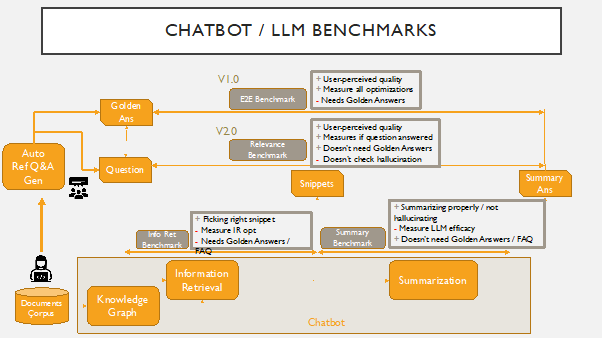
論文は End-to-End (E2E) チャットボットのベンチマークを導入し、チャットボットの回答と黄金の人間の回答との間の意味的類似性をテキスト埋め込み(USEとST)で評価することによって精度と有用性を測定し、それを ROUGE 指標と比較します。
Autonomous conversational agents, i.e. chatbots, are becoming an increasingly common mechanism for enterprises to provide support to customers and partners. In order to rate chatbots, especially ones powered by Generative AI tools like Large Language Models (LLMs) we need to be able to accurately assess their performance. This is where chatbot benchmarking becomes important. In this paper, we propose the use of a novel benchmark that we call the E2E (End to End) benchmark, and show how the E2E benchmark can be used to evaluate accuracy and usefulness of the answers provided by chatbots, especially ones powered by LLMs. We evaluate an example chatbot at different levels of sophistication based on both our E2E benchmark, as well as other available metrics commonly used in the state of art, and observe that the proposed benchmark show better results compared to others. In addition, while some metrics proved to be unpredictable, the metric associated with the E2E benchmark, which uses cosine similarity performed well in evaluating chatbots. The performance of our best models shows that there are several benefits of using the cosine similarity score as a metric in the E2E benchmark.
研究の動機と目的
- 大規模言語モデル(LLMs)により駆動されるエンタープライズチャットボットの堅牢な評価を動機づける。
- チャットボットの回答と専門家の黄金回答との意味的類似性を測定する End-to-End (E2E) ベンチマークを提案する。
- ROUGE のような従来指標と比較して埋め込みベースの類似性の利点を示すとともに、E2E を評価する。
- プロンプトエンジニアリングが E2E の性能に与える影響を探り、ROUGE の結果と比較する。
提案手法
- 黄金回答とチャットボット回答の埋め込みベクトル間のコサイン類似度を用いて E2E ベンチマークを定義する。
- 文の埋め込みを取得するために Universal Sentence Encoder (USE) と Sentence Transformer (ST) の2つの埋め込みライブラリを使用する。
- 黄金回答とチャットボット回答の間のコサイン類似度 S(G,A) = (X_G · X_A) / (|X_G||X_A|) を計算する。
- 同じ回答ペアに対して ROUGE-1、ROUGE-2、ROUGE-LCS の ROUGE スコアと E2E の結果を比較する。
- 製品サポート用チャットボットで評価し、埋め込みベースのスコアと ROUGE スコアの相関を分析する。
- 標準プロンプトと強化プロンプトというプロンプトエンジニアリングが E2E と ROUGE 指標に与える影響を検討する。
実験結果
リサーチクエスチョン
- RQ1コサイン類似度を用いた文埋め込みベースの E2E ベンチマークは、LLM 搭載チャットボットの ROUGE ベース評価と比較してどの程度の性能を示すのか?
- RQ2埋め込みベースの E2E スコアは、ROUGE スコアよりもプロンプトエンジニアリングによる改善をより正確に反映するのか?
- RQ3USE 埋め込みと ST 埋め込みがチャットボット性能の測定においてどのような関係を持つのか?
- RQ4E2E は意味のある改善とノイズ(例:ランダム語)の区別を行えるのか?
- RQ5異なる埋め込みモデルに対して E2E ベンチマークはどれくらい感度が高いのか?
主な発見
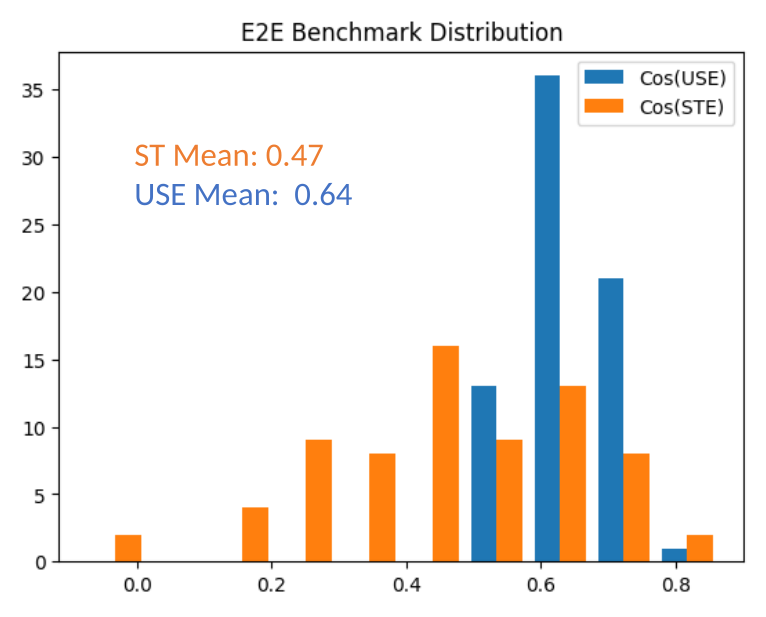
- USE を用いた E2E は平均コサイン類似度が約 0.64、ST を用いた E2E は約 0.47(評価対象のチャットボット)であった。
- USE ベースと ST ベースの E2E 結果の間には強い相関がある(R^2 ≈ 0.7)。
- ROUGE 指標は埋め込みベースの E2E 結果と関連が限定的で、プロンプトエンジニアリングによる改善を一貫して反映しなかった。
- ST 埋め込みを用いた E2E ベンチマークは、設計されたプロンプトを適用した際により鋭い改善を示し、プロンプト設計に対する感度が高いことを示した。
- ランダム語を用いた評価では E2E スコアがほぼランダムに近づき、ST が USE よりも優れていた。
- プロンプトエンジニアリング(強化プロンプト)は、ST ベースの E2E 結果を USE ベースの結果よりも大幅に改善する。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。