[論文レビュー] Better & Faster Large Language Models via Multi-token Prediction
本論文は言語モデルを同時に複数の未来トークンを予測するよう訓練し、サンプル効率を改善し、自己推定デコードによる高速推論を可能にする。コードタスクで顕著な成果が見られ、パラメータが最大で13Bまでスケールした場合の恩恵も示される。
Large language models such as GPT and Llama are trained with a next-token prediction loss. In this work, we suggest that training language models to predict multiple future tokens at once results in higher sample efficiency. More specifically, at each position in the training corpus, we ask the model to predict the following n tokens using n independent output heads, operating on top of a shared model trunk. Considering multi-token prediction as an auxiliary training task, we measure improved downstream capabilities with no overhead in training time for both code and natural language models. The method is increasingly useful for larger model sizes, and keeps its appeal when training for multiple epochs. Gains are especially pronounced on generative benchmarks like coding, where our models consistently outperform strong baselines by several percentage points. Our 13B parameter models solves 12 % more problems on HumanEval and 17 % more on MBPP than comparable next-token models. Experiments on small algorithmic tasks demonstrate that multi-token prediction is favorable for the development of induction heads and algorithmic reasoning capabilities. As an additional benefit, models trained with 4-token prediction are up to 3 times faster at inference, even with large batch sizes.
研究の動機と目的
- 次トークン予測を超える、LLMのよりサンプル効率的な訓練目的として多トークン予測を動機づける。
- 共有トランクと複数ヘッドを持つ、メモリ効率の良い多トークン予測アーキテクチャを提案する。
- 特にコードタスクで、多トークン予測を用いる場合のスケーリング恩恵と高速推論をデモンストレーションする。
- 微調整後の自然言語生成および下流タスクにおいて、多トークン予測が性能を維持または向上させることを示す。
提案手法
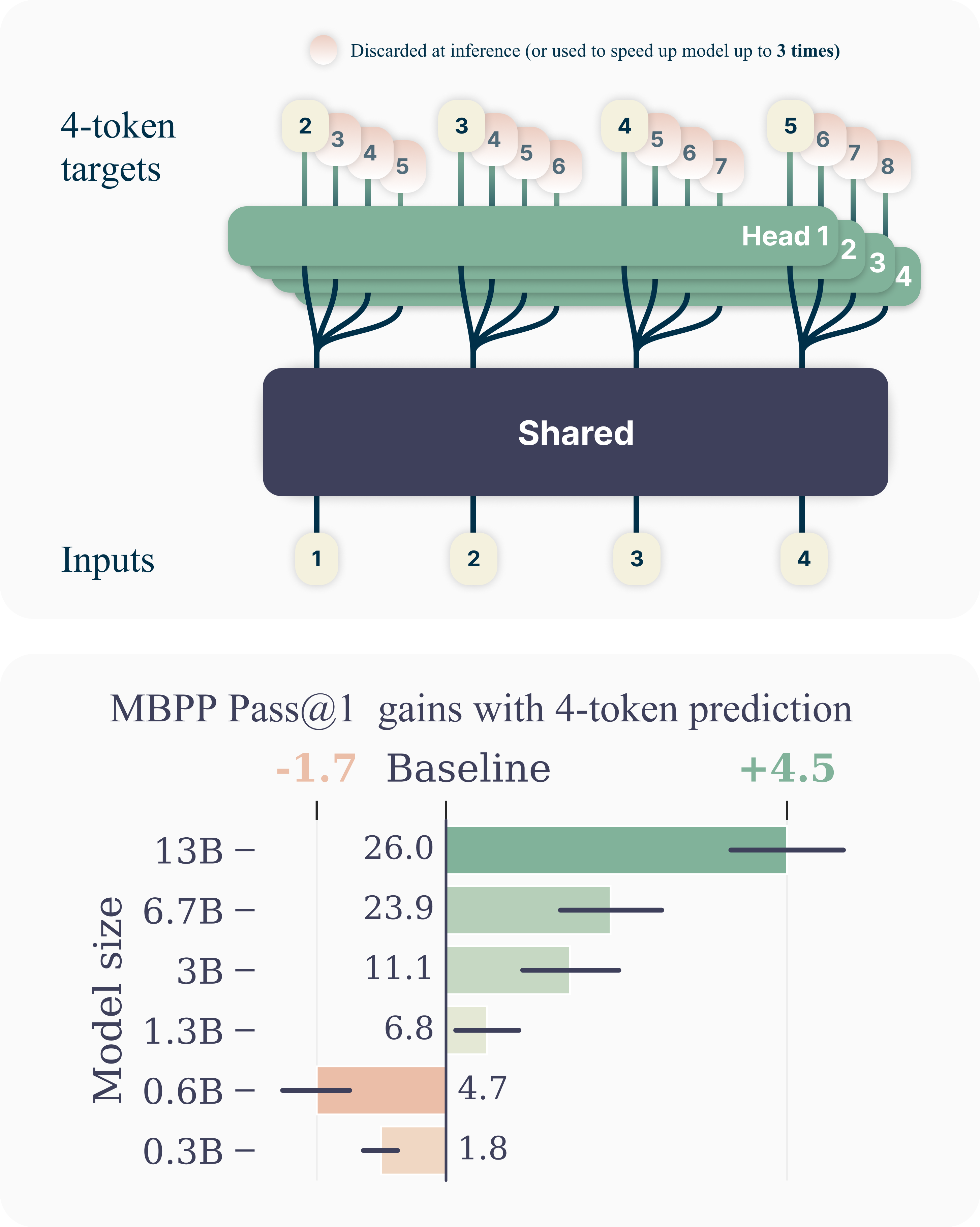
- 共有トランク上でn個の独立したヘッドを用いて、各位置でn個の未来トークンを予測する多トークン予測目的を導入する。
- 共有表現と各ヘッド予測に対して分解する、扱いやすいクロスエントロピー損失L_nを導出する。
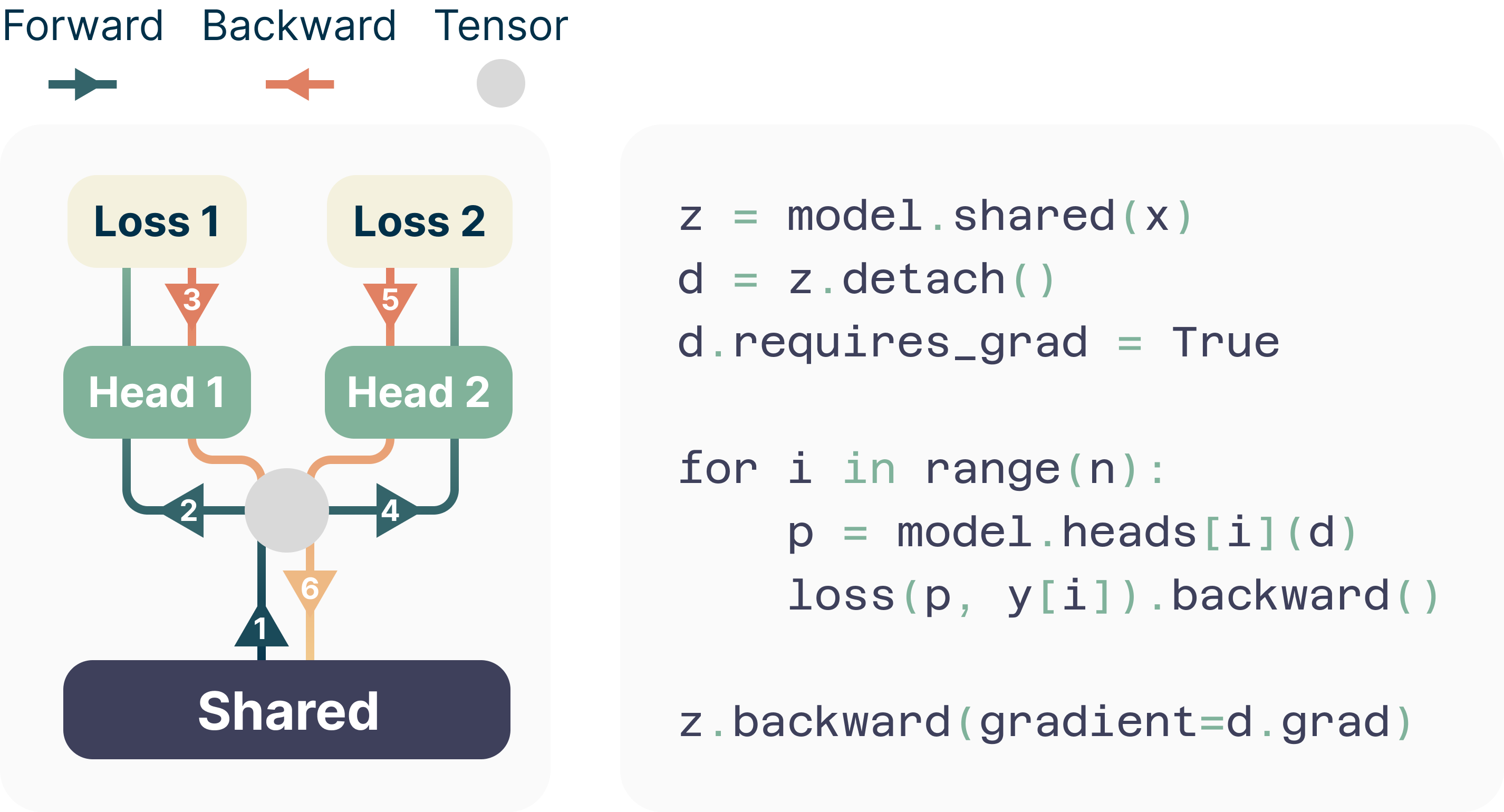
- ピークメモリをO(nV+d)からO(V+d)へ削減する、メモリ効率の良いフォワード/バックワード方式を記述する。
- 追加のヘッドを追加のドラフトモデルなしで活用して推論を高速化するために、自己推定デコードを使用する。
- コードと自然言語ベンチマークを、最大13Bパラメータまでのさまざまなモデルサイズとデータ規模で評価し、バイトレベルトークン化を含む。
実験結果
リサーチクエスチョン
- RQ1訓練時に複数の未来トークンを予測することは、標準の次トークン予測と比べて下流の性能を改善するか?
- RQ2コードと自然言語タスクにおけるモデルサイズと訓練データ量のスケールとともに、多トークン予測はどう拡張するか?
- RQ3追加の計算コストなしで、推定デコードを介して多トークン訓練がより速い推論を可能にするか?
- RQ4さまざまな予測窓サイズ(n)が、タスクとデータ状況に対して性能に与える影響は?
主な発見
- 多トークン予測はサンプル効率を高め、13Bパラメータモデルは next-token ベースラインより HumanEval で約12%、MBPPで約17%多くの問題を解く。
- 4トークン予測で substantial gains を達成し、自己推定デコードにより最大3倍の高速推論を実現、特にコードベンチマークで顕著。
- 恩恵はモデルサイズとともに拡大し、複数エポックでも持続し、コードタスクおよびバイトレベルモデリングで顕著な改善を示す。
- 2トークン予測は標準的なNLPベンチマークで次トークンのベースラインと一致することが多い一方、4トークン予測は一部の言語タスクで性能が低下することがあり、タスクとデータ依存の影響を示唆する。
- CodeContestsで事前学習済みの多トークンモデルをファインチューニングすると設定を問わずpass@kが改善され、4トークン事前学習の上に次トークンファインチューニングが時として最も強力になる。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。