[論文レビュー] Better speech synthesis through scaling
TorToise は 自己回帰デコーディングと DDPMs を テキスト音声合成に組み合わせ、CLVP リランキングモデルに導かれ、オープンソースの 重みと データを用いて 高いリアリズムと マルチボイス TTS を 実現する。
In recent years, the field of image generation has been revolutionized by the application of autoregressive transformers and DDPMs. These approaches model the process of image generation as a step-wise probabilistic processes and leverage large amounts of compute and data to learn the image distribution. This methodology of improving performance need not be confined to images. This paper describes a way to apply advances in the image generative domain to speech synthesis. The result is TorToise -- an expressive, multi-voice text-to-speech system. All model code and trained weights have been open-sourced at https://github.com/neonbjb/tortoise-tts.
研究の動機と目的
- 従来の制約モデルを超えた TTS のスケーリングとジェネラリストアーキテクチャを動機づける。
- テキストに合わせた音声トークンを生成するために自己回帰デコーディングを活用し、拡散を用いて高品質なスペクトログラムを作成する。
- 声の特徴と韻律を捉える音声条件付入力を組み込む。
- より高いリアリズムのために対照的識別器(CLVP)を用いて候補を再ランク付けする。
- 合成品質を向上させるために大規模で多様なデータセットでの学習を実証する。
提案手法
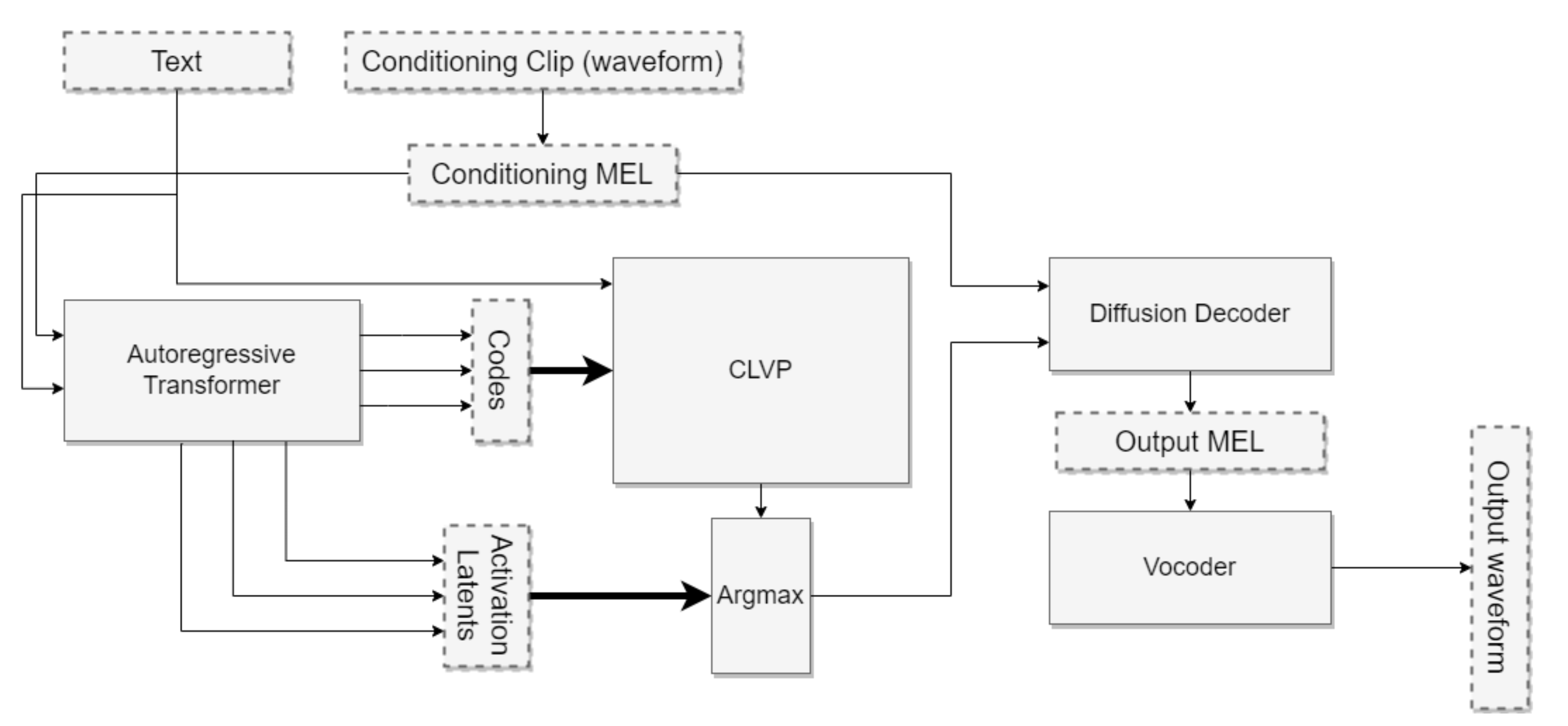
- テキストと音声条件付きエンコードに条件づけられた自己回帰デコーダを組み合わせて音声トークンを予測する。
- 音声トークンを MEL スペクトログラムへ、さらに波形へ変換する拡散デコーダを訓練する。
- 出力の再ランク付けのためにテキスト-音声ペアを評価する CLVP モデルを導入する。
- 効率と品質のために AR 潜在空間上で拡散モデルをファインチューニングすることで“TorToise Trick”を適用する。
- 訓練には大規模な LibriTTS + HiFiTTS ベースのデータセットと、49,000 時間の拡張オーディオブック/ポッドキャストデータセットを使用する。
- 推論は複数の AR 出力をサンプリングし、CLVP で再ランク付けし、拡散と vocoder によって上位候補をデコードする。
実験結果
リサーチクエスチョン
- RQ1自己回帰型および拡散ベースのモデルのスケーリングは、複数の声に跨って TTS のリアリズムを向上させることができるか?
- RQ2音声条件付入力を取り入れることで探索空間を削減し、韻律と声の特徴を改善できるか?
- RQ3対照的な音声-テキストモデルは、品質を向上させるために TTS 出力を効果的に再ランク付けできるか?
- RQ4極めて大規模で多様なデータセットでの学習が TTS の性能に与える影響は?
- RQ5AR デコーディングと DDPM の組み合わせは、伝統的な TTS パイプラインと品質とレイテンシの点でどのように比較されるか?
主な発見
- TorToise は一般ist トランスフォーマーアーキテクチャと大規模データを活用することで、現実感において従来の TTS モデルを上回ると報告されている。
- 大規模で高品質なデータセット(LibriTTS、HiFiTTS)と 49k 時間の拡張データセットが強力な性能を可能にする。
- 音声条件付けと TorToise Trick を備えた AR+DDPM アーキテクチャは、高品質な音声合成を生み出す。
- CLVP リランキングは上位出力の効率的な選択を可能にし、推論時の拡散のみ生成への依存を減らす。
- 推論は AR に nucleus sampling を、DDIM ベースの拡散には特定のスケジューリングを用い、品質と速度のトレードオフを実現する。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。