[論文レビュー] Beyond Adapting SAM: Towards End-to-End Ultrasound Image Segmentation via Auto Prompting
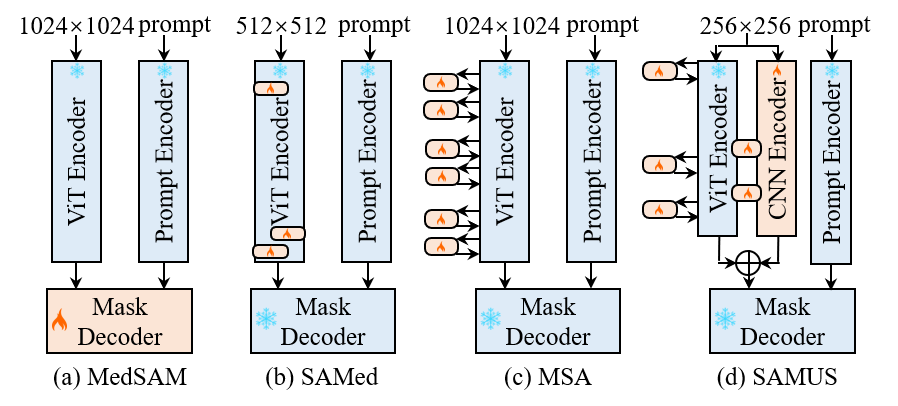
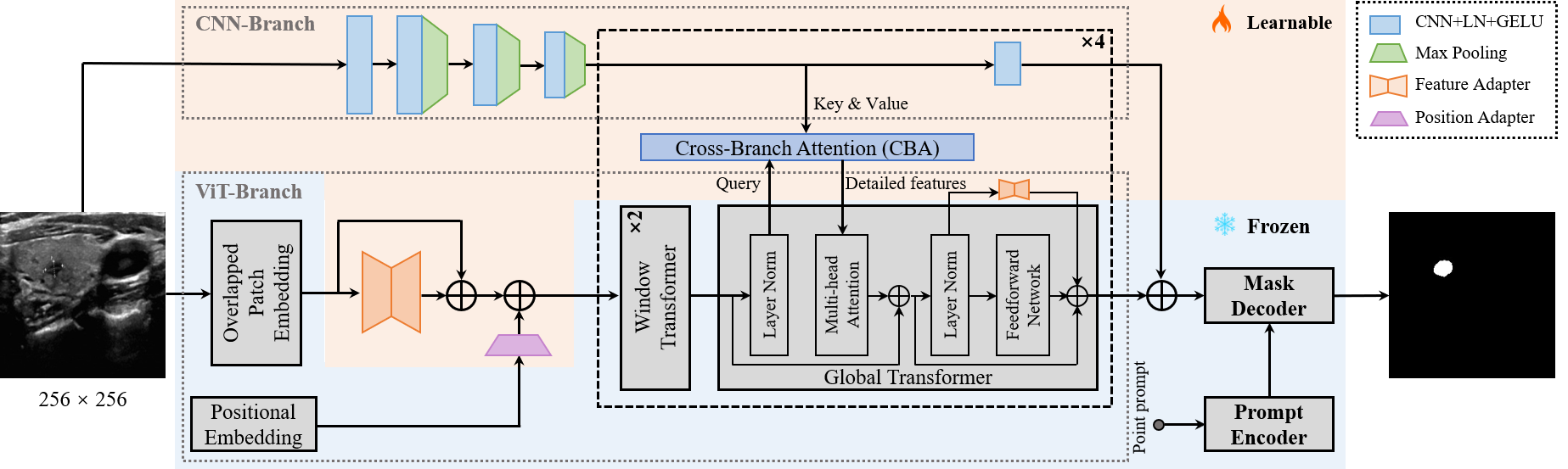
SAMUSはSAMを並列CNNエンコーダ、アダプター、クロスブランチアテンションを搭載して拡張し、エンドツーエンドの超音波分割を可能にするとともに一般化を改善し展開コストを低減。US30Kで実証。
End-to-end medical image segmentation is of great value for computer-aided diagnosis dominated by task-specific models, usually suffering from poor generalization. With recent breakthroughs brought by the segment anything model (SAM) for universal image segmentation, extensive efforts have been made to adapt SAM for medical imaging but still encounter two major issues: 1) severe performance degradation and limited generalization without proper adaptation, and 2) semi-automatic segmentation relying on accurate manual prompts for interaction. In this work, we propose SAMUS as a universal model tailored for ultrasound image segmentation and further enable it to work in an end-to-end manner denoted as AutoSAMUS. Specifically, in SAMUS, a parallel CNN branch is introduced to supplement local information through cross-branch attention, and a feature adapter and a position adapter are jointly used to adapt SAM from natural to ultrasound domains while reducing training complexity. AutoSAMUS is realized by introducing an auto prompt generator (APG) to replace the manual prompt encoder of SAMUS to automatically generate prompt embeddings. A comprehensive ultrasound dataset, comprising about 30k images and 69k masks and covering six object categories, is collected for verification. Extensive comparison experiments demonstrate the superiority of SAMUS and AutoSAMUS against the state-of-the-art task-specific and SAM-based foundation models. We believe the auto-prompted SAM-based model has the potential to become a new paradigm for end-to-end medical image segmentation and deserves more exploration. Code and data are available at https://github.com/xianlin7/SAMUS.
研究の動機と目的
- 普遍的で臨床的に優しい超音波分割を動機づける。
- SAMの基盤を活用しつつ医療ドメインの制限に対処する。
- 超音波ターゲットの局所的なディテールの把握と境界の描出を改善する。
- GPU要件を削減し、エントリーレベルのハードウェアでの展開を可能にする。
提案手法
- SAMのプロンプトエンコーダとマスクデコーダを維持し、画像エンコーダを医療用途向けに変更。
- 局所特徴をクロスブランチアテンションで注入する並列CNNブランチを追加。
- ViTを医療ドメインと小型入力へ適応させるため、ポジションアダプターと5つの特徴アダプターを導入。
- 境界情報を保持するために重なりパッチ埋め込みを実装。
- アダプター、CNNブランチ、クロスブランチアテンションで訓練し、核となるSAMコンポーネントをフリーズ; ダイス損失+ BCE損失を単一点陽性プロンプトで使用。
実験結果
リサーチクエスチョン
- RQ1全モデルを再訓練せずにSAMを超音波分割へ効果的に適応できるか?
- RQ2局所特徴統合とコンパクトなアダプターは超音波画像での境界保持と小さなオブジェクトの分割を改善するか?
- RQ3見 seen (訓練データ) および unseen 超音波データセットで、タスク特化モデルおよび他のファウンデーションモデルと比較してSAMUSはどのように性能を示すか?
主な発見
- SAMUSはTN3K, BUSI, CAMUS-LV, CAMUS-MYO, CAMUS-LAでstate-of-the-artタスク特化手法より高い平均Diceを達成(平均 Dice:84.45%、85.77%、93.73%、87.46%、91.58%)。
- ファウンデーションモデルとの比較では、SAMUSは見えるデータで一貫して優れたDiceスコアを提供(例: 83.05–93.73の範囲)し、 unseenデータセットへの一般化も向上(例: unseenデータでベースラインより平均的に増分)。
- アブレーションにより4つの構成要素(CNNブランチ、クロスブランチアテンション、特徴アダプター、ポジションアダプター)のすべてが性能に寄与することが示され、特にポジションアダプター単独で複数のデータセットでDiceを顕著に向上させる。
- SAMUSはフルSAM訓練の約28%のGPUメモリコストに抑え、推論は約3倍速く、分割と一般化を維持または改善。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。