[論文レビュー] Beyond Chain-of-Thought, Effective Graph-of-Thought Reasoning in Language Models
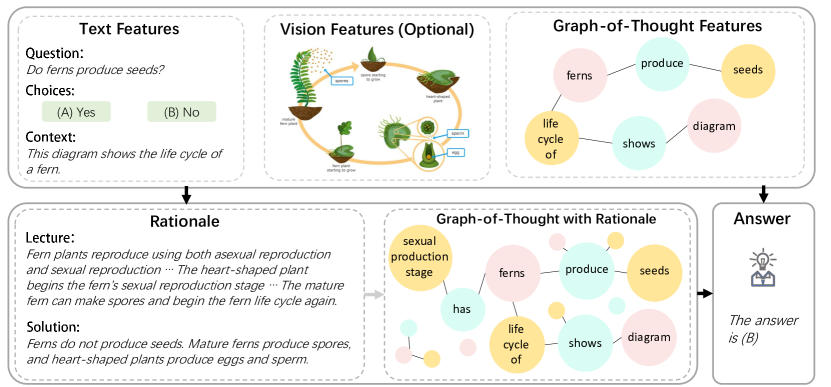
Graph-of-Thought (GoT) 推論を導入する、LLMの推論を非線形グラフベースのアプローチで強化し、思考グラフをテキストと視覚情報と統合して、少ないパラメータでGSM8KとScienceQAにおいて最先端の結果を達成します。
With the widespread use of language models (LMs) in NLP tasks, researchers have discovered the potential of Chain-of-thought (CoT) to assist LMs in accomplishing complex reasoning tasks by generating intermediate steps. However, human thought processes are often non-linear, rather than simply sequential chains of thoughts. Therefore, we propose Graph-of-Thought (GoT) reasoning, which models human thought processes not only as a chain but also as a graph. By representing thought units as nodes and connections between them as edges, our approach captures the non-sequential nature of human thinking and allows for a more realistic modeling of thought processes. GoT adopts a two-stage framework with an additional GoT encoder for thought graph representation and fuses the graph representation with the original input representation through a gated fusion mechanism. We evaluate GoT's performance on a text-only reasoning task (AQUA-RAT) and a multimodal reasoning task (ScienceQA). Our model achieves significant improvement over the strong CoT baseline on the AQUA-RAT test set and boosts accuracy from 85.19% to 87.59% using the T5-base model over the state-of-the-art Multimodal-CoT on the ScienceQA test set.
研究の動機と目的
- 人間の推論を線形連鎖ではなく非線形グラフとしてモデル化する動機づけ。
- ECCベースのグラフ構築を提案し、密で推論可能な思考グラフを作成。
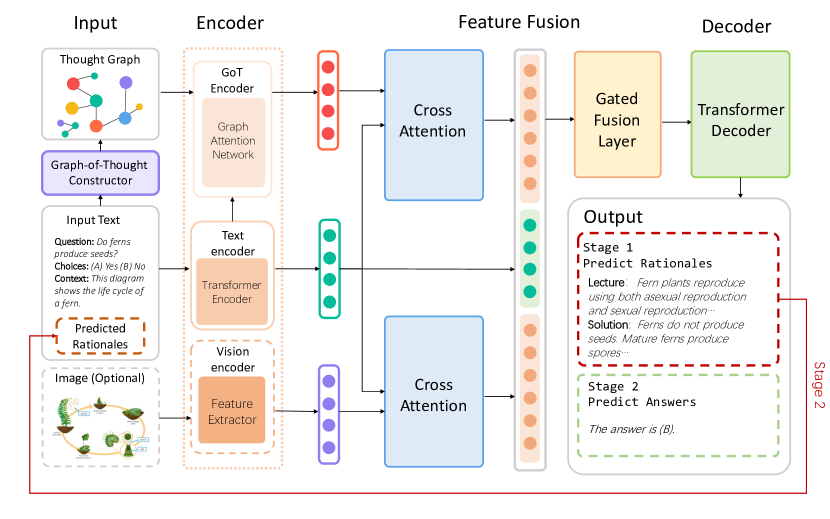
- グラフ注意ネットワークとゲート付き融合を用いたGoTエンコーダを開発し、グラフ・テキスト・視覚特徴を統合。
- テキストのみおよびマルチモーダルタスクでの2段階推論(根拠生成→解答)を実証。
- GoTの効果とパラメータ効率を、CoTおよびMultimodal-CoTベースラインと比較して示す。
提案手法
- Extract-Cluster-Coreference (ECC) によって思考グラフを構築し、推論三つ組からノードとエッジを生成。
- Transformerでテキストを、Graph Attention Network (GAT)でグラフを、必要に応じて視覚エンコーダで視覚をエンコード。
- テキストと視覚およびグラフノードを整列させるためにクロスアテンションを使用し、ゲート付き融合で融合表現を生成。
- 二段階フレームワークを適用:根拠生成→最終解答生成。第二段階で予測された根拠を使用。
- GSM8KとScienceQAでT5ベースのUnifiedQAモデル(ベースと大)を、GoTの二段階設定とゲート付き融合でファインチューニング。
- 任意のマルチモーダル拡張は、テキスト・視覚・GoT表現を単一ヘッド注意の整列とゲート融合機構で統合。
実験結果
リサーチクエスチョン
- RQ1Graph-of-Thoughtは、LLMにおける連鎖的推論より非連続的推論をよりよく捉えられるか?
- RQ2推論グラフをテキスト(および視覚)と統合することで、テキストのみおよびマルチモーダルの数学/科学タスクの性能が向上するか?
- RQ3GoTは大規模なMultimodal-CoTベースラインと比較してパラメータ効率が高く、SOTAを達成できるか?
- RQ4GoTは画像補助タスクを含む異なる科目や問題種別でどのように性能を発揮するか?
- RQ5ECCベースのグラフ構築と多頭GoTエンコードが最終推論精度に与える影響は何か?
主な発見
| モデル | トレーニング | サイズ | ACC (%) | GSM8K (G1-6) | GSM8K (G7-12) | 平均 | NAT | SOC | LAN | TXT | IMG | NO | G1-6 | G7-12 | 平均 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| GPT-3 | train-set | 175B | 55.00 | - | - | - | - | - | - | - | - | - | - | - | - |
| code-davinci-002 | few-shot | 175B | 68.01 | - | - | - | - | - | - | - | - | - | - | - | - |
| GPT-3.5 | few-shot | - | 57.10 | - | - | - | - | - | - | - | - | - | - | - | - |
| GPT-4 | few-shot | - | 92.00 | - | - | - | - | - | - | - | - | - | - | - | - |
| UnifiedQA-base | train-set | 223M | 62.70 | - | - | - | - | - | - | - | - | - | - | - | - |
| GoT-T5-base | train-set | 223M | 66.11 | - | - | - | - | - | - | - | - | - | - | - | - |
| UnifiedQA-large | train-set | 738M | 77.10 | - | - | - | - | - | - | - | - | - | - | - | - |
| GoT-T5-large | train-set | 738M | 82.18 | - | - | - | - | - | - | - | - | - | - | - | - |
| Mutimodal-CoT-base | train-set | 223M | 87.52 | - | - | - | - | - | - | - | - | - | - | - | - |
| GoT-T5-base (ScienceQA) | train-set | 223M | - | 98.29 | 98.43 | 96.23 | 98.37 | - | - | - | - | - | - | - | - |
| Mutimodal-CoT-large | train-set | 738M | 95.91 | 82.00 | 90.82 | 92.44 | 90.31 | 91.68 | - | - | - | - | - | - | - |
| GoT-T5-large (ScienceQA) | train-set | 738M | - | 98.35 | 98.45 | 96.30 | 98.41 | - | - | - | - | - | - | - | - |
- GoTはGSM8Kのエンドツーエンド精度をCoTベースラインよりGoT-baseで3.41%、GoT-largeで5.08%向上させる。
- GoTはScienceQAの精度をGoT-baseで91.54%、GoT-largeで92.77%達成し、類似または少ないパラメータ数のMultimodal-CoTベースラインを上回る。
- GSM8Kでは、GoT-baseが66.11%、GoT-largeが82.18%に達し、UnifiedQAベースラインに対してパラメータを抑えつつ顕著な向上を示す。
- ScienceQAでは、GoT(ベース)で91.68%、(large)で92.77%を達成し、大規模なMultimodal-CoTに近づくか超え、より大きなモデルと競合。
- アブレーション研究は、多頭GoTエンコーダの必要性と、現実的な思考グラフが乱雑なグラフより有効であることを確認;GoTは拡張されたMultimodal-CoTより3.00%上回る。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。