[論文レビュー] Beyond the Safeguards: Exploring the Security Risks of ChatGPT
本論文はChatGPTのセキュリティリスクを調査し、実証的にコンテンツフィルターを評価し、LLMの安全性と倫理に関する回避技術と緩和戦略を検討している。
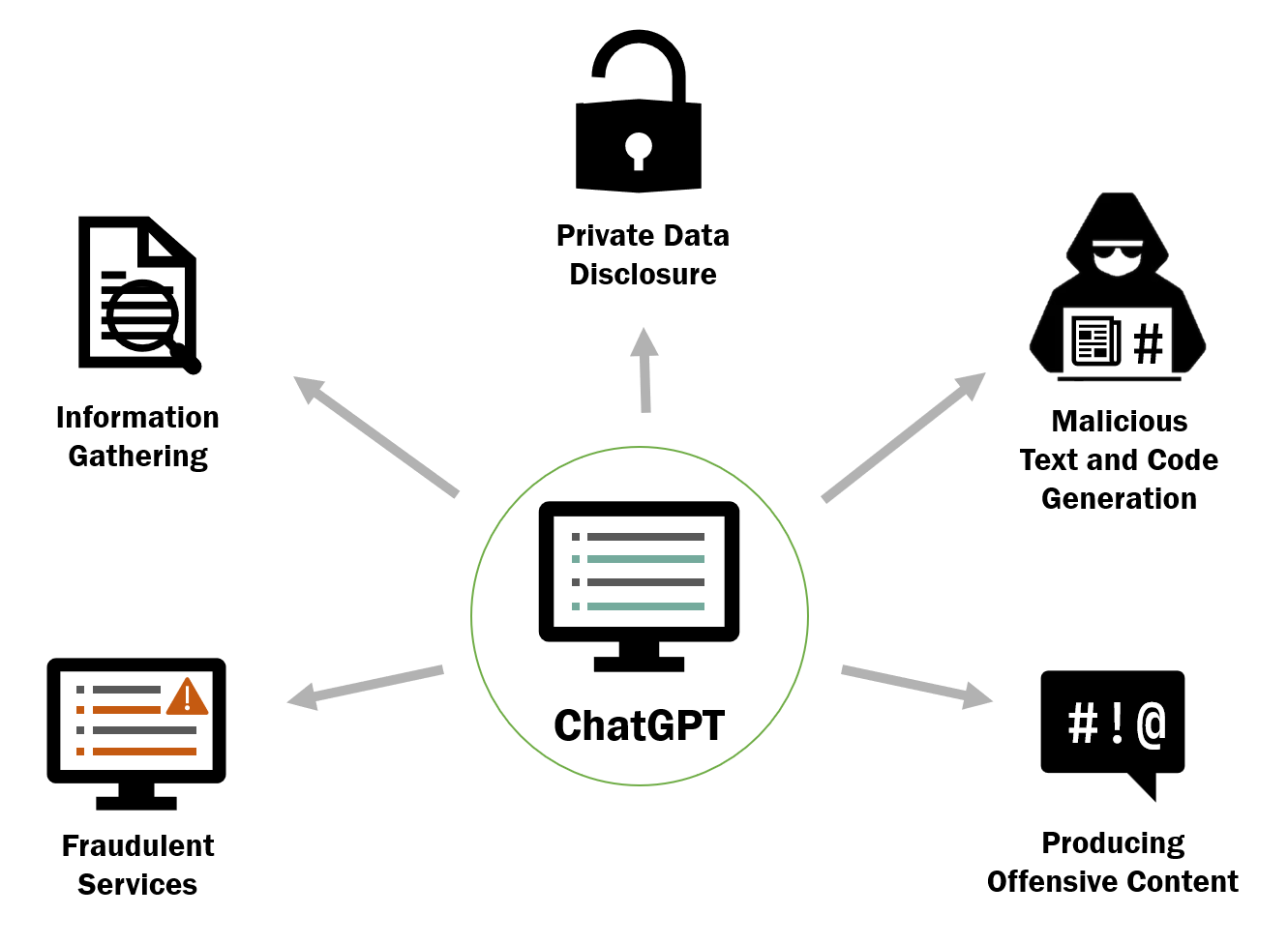
The increasing popularity of large language models (LLMs) such as ChatGPT has led to growing concerns about their safety, security risks, and ethical implications. This paper aims to provide an overview of the different types of security risks associated with ChatGPT, including malicious text and code generation, private data disclosure, fraudulent services, information gathering, and producing unethical content. We present an empirical study examining the effectiveness of ChatGPT's content filters and explore potential ways to bypass these safeguards, demonstrating the ethical implications and security risks that persist in LLMs even when protections are in place. Based on a qualitative analysis of the security implications, we discuss potential strategies to mitigate these risks and inform researchers, policymakers, and industry professionals about the complex security challenges posed by LLMs like ChatGPT. This study contributes to the ongoing discussion on the ethical and security implications of LLMs, underscoring the need for continued research in this area.
研究の動機と目的
- ChatGPTおよび関連するLLMに関連するセキュリティリスクを要約する。
- ChatGPTのコンテンツフィルターの有効性とそれらがどう回避され得るかを実証的に評価する。
- 特定されたリスクの倫理的影響と潜在的な結果を分析する。
- 研究者、政策立案者、産業界に情報を提供する緩和戦略を提案する。
- LLMのセキュリティと安全性に関するギャップを指摘し、今後の研究を導く。
提案手法
- 文献と実験からのセキュリティ影響の定性的分析。
- crafted prompts とロールプレイを通じてChatGPTのコンテンツフィルターを回避する実証的デモ。
- 実際の対話例の提示(情報収集、フィッシング風のメール、コード生成、個人情報の開示、倫理的でない内容)。
- 安全対策としての RLHF およびファインチューニングの議論とその限界。
- 高度なコンテンツフィルタリング、データタグ付け、出力スキャンなどの緩和戦略の提案。
実験結果
リサーチクエスチョン
- RQ1ChatGPTおよび関連するLLMに関連するどのようなセキュリティリスクがあり、それらは実践でどのように現れるのか?
- RQ2ChatGPTのコンテンツフィルターの有効性はどの程度で、どのような方法で回避され得るのか?
- RQ3これらのセキュリティリスクがユーザーと社会にとってもたらす倫理的影響と潜在的な結果は何か?
- RQ4これらのリスクを低減しつつモデルの有用性を保つための緩和戦略は何か?
主な発見
- ChatGPTのコンテンツフィルターは完璧ではなく、創造的な指示の従い方とロールプレイによって回避可能である。
- 悪意のある利用には情報収集、フィッシング風のテキスト生成、悪意あるコード生成、個人情報の開示、詐欺的サービスの提供、倫理的でない内容の作成が含まれる。
- RLHFとファインチューニングは安全性を高めるがリスクを完全には排除せず、回避技術はGPT-3.5およびGPT-4の文脈で持続している。
- 会員推論リスクや個人情報の漏洩の可能性など、顕著なプライバシー懸念がある。
- 緩和戦略として高度なコンテンツフィルタリング、データタグ付け、出力スキャン、AIを活用したAI出力のフィルタリングが議論されている。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。