[論文レビュー] BiBench: Benchmarking and Analyzing Network Binarization
BiBench は、複数のタスク、アーキテクチャ、破損、学習設定、ハードウェアを横断して 8 個の二値化アルゴリズムを比較する包括的なベンチマークを提供し、精度と効率性に対する演算子レベルの影響を明らかにする。
Network binarization emerges as one of the most promising compression approaches offering extraordinary computation and memory savings by minimizing the bit-width. However, recent research has shown that applying existing binarization algorithms to diverse tasks, architectures, and hardware in realistic scenarios is still not straightforward. Common challenges of binarization, such as accuracy degradation and efficiency limitation, suggest that its attributes are not fully understood. To close this gap, we present BiBench, a rigorously designed benchmark with in-depth analysis for network binarization. We first carefully scrutinize the requirements of binarization in the actual production and define evaluation tracks and metrics for a comprehensive and fair investigation. Then, we evaluate and analyze a series of milestone binarization algorithms that function at the operator level and with extensive influence. Our benchmark reveals that 1) the binarized operator has a crucial impact on the performance and deployability of binarized networks; 2) the accuracy of binarization varies significantly across different learning tasks and neural architectures; 3) binarization has demonstrated promising efficiency potential on edge devices despite the limited hardware support. The results and analysis also lead to a promising paradigm for accurate and efficient binarization. We believe that BiBench will contribute to the broader adoption of binarization and serve as a foundation for future research. The code for our BiBench is released https://github.com/htqin/BiBench .
研究の動機と目的
- 実運用におけるネットワーク二値化の実用的要件と評価トラックを定義する。
- 二値化演算子がタスクとアーキテクチャ全体で精度、効率、導入性に与える影響を評価する。
- 破損耐性と二値化ネットワークのハードウェア導入可能性を評価する。
- 高精度で効率的な二値化アルゴリズムを設計するための洞察とガイドラインを提供する。
提案手法
- スケーリング因子、パラメータ再配分、勾配近似の分野を横断する 8 個の影響力のある演算子レベルの二値化アルゴリズムを選択する。
- これらのアルゴリズムを 9 datasets、13 neural architectures、2 deployment libraries、14 hardware chips、変化するハイパーパラメータでベンチマークする。
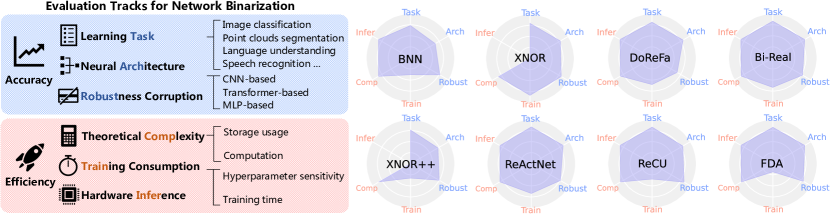
- 6 つの評価トラック(Learning Task、Neural Architecture、Corruption Robustness、Training Consumption、Theoretical Complexity、Hardware Inference)を統一指標で定義する。
- 全精度ベースラインを用いて各トラックの平均相対精度と二次平均を全体指標として算出する。
- 評価のために PyTorch で訓練/推論パイプラインを実装し、事前学習、ファインチューニング、ONNX エクスポートを標準化する。
実験結果
リサーチクエスチョン
- RQ1二値化の精度は異なる学習タスクやデータモダリティ間でどのように変化するか?
- RQ2ニューラルアーキテクチャの選択(CNN、Transformer、MLP)は二値化の性能にどのように影響するか?
- RQ3データの破損が二値化ネットワークに与える影響は、フルプレシジョンモデルと比較してどうか?
- RQ4二値化ネットワークの実用的な学習コストとハードウェア導入可能性はどの程度か?
- RQ5精度と効率のバランスを取る効果的な演算子設計の一般的な設計パラダイムは存在するか?
主な発見
- 二値化演算子は性能にとって極めて重要で、同じアルゴリズムでもタスク間で大きな精度差(例:GLUE 対 ShapeNet)が生じる。
- Transformer ベースのアーキテクチャは二値化が特に難しく、CNN と MLP はフルプレシジョン精度のより高い割合に到達できる。
- 二値化ネットワークは CIFAR10-C でフルプレシジョンモデルと同程度の破損耐性を示すことがあり、アルゴリズム次第でそれを上回ることもある。
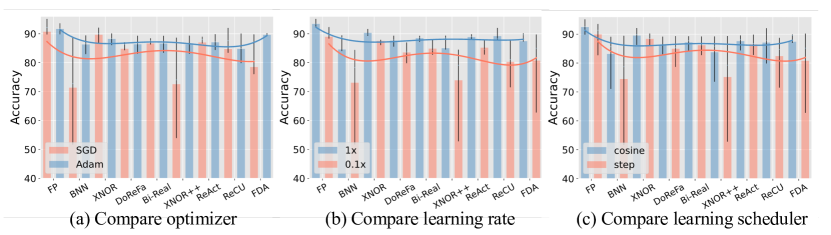
- 訓練コストは変動が大きく、いくつかのアルゴリズムはハイパーパラメータに対して安定している一方で、勾配近似技術のために大幅な訓練時間を要するものもある。
- エッジ機器では推論ライブラリの available によってハードウェア導入が制限されるが、サポートされれば二値化はストレージと推論速度の大幅な向上ポテンシャルを示す。
- FDA および ReActNet アプローチは、CNN と Transformer の両方で安定性の利点を提供し、実用的な演算子設計パラダイムを示唆する。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。