[論文レビュー] BioMedLM: A 2.7B Parameter Language Model Trained On Biomedical Text
BioMedLM は PubMed 抄録と記事のみに基づいて訓練された 2.7B パラメータの GPT 型モデルで、ファインチューニング後に競合的な生物医学 QA パフォーマンスを達成し、オンデバイス推論とオープンなデータ系譜を実現します。
Models such as GPT-4 and Med-PaLM 2 have demonstrated impressive performance on a wide variety of biomedical NLP tasks. However, these models have hundreds of billions of parameters, are computationally expensive to run, require users to send their input data over the internet, and are trained on unknown data sources. Can smaller, more targeted models compete? To address this question, we build and release BioMedLM, a 2.7 billion parameter GPT-style autoregressive model trained exclusively on PubMed abstracts and full articles. When fine-tuned, BioMedLM can produce strong multiple-choice biomedical question-answering results competitive with much larger models, such as achieving a score of 57.3% on MedMCQA (dev) and 69.0% on the MMLU Medical Genetics exam. BioMedLM can also be fine-tuned to produce useful answers to patient questions on medical topics. This demonstrates that smaller models can potentially serve as transparent, privacy-preserving, economical and environmentally friendly foundations for particular NLP applications, such as in biomedicine. The model is available on the Hugging Face Hub: https://huggingface.co/stanford-crfm/BioMedLM.
研究の動機と目的
- 大規模モデルのプライバシー、コスト、透明性の懸念に対処するため、ドメイン固有の小型 LLM の開発を動機づける。
提案手法
- 2.7B パラメータの Autoregressive デコーダのみの Transformer(GPT-2 型)。
- PubMed 抄録で訓練されたドメイン固有の Byte-Pair Encoding トークナイザーを用いて、生物医学用語のトークン化を改善。
- PubMed 抄録と記事(34.6B トークン、8.67 パス、約300B トークンを探索)での事前訓練を、混合精度、最終訓練は bf16、Decoupled AdamW オプティマイザを使用して実施。
- 下流の生物医学 QA タスク向けに、複数の選択肢プロンプトを前提としたアーキテクチャに特化したファインチューニング(タスクごとのプロンプト整形と回答スコア上の最終線形分類器)。
- ウェブ由来の QA ペアを用いた長文回答型の消費者向け健康質問回答の生成スタイルのファインチューニング。

実験結果
リサーチクエスチョン
- RQ1 compact でドメイン特化型のモデル(2.7B パラメータ)は、生物医学 QA タスクで大規模モデルの性能に匹敵するか、あるいは近づくか?
- RQ2PubMed データのみで訓練し、生物医学用トークナイザーを使用すると、下流タスクの性能は一般ドメインのベースラインと比べて改善されるか?
- RQ3小型でオープンな生物医学 LLM を展開する際のプライバシー、コスト、アクセス性のトレードオフは、クローズドな大規模モデルと比べてどうか?
主な発見
| データセット | モデル | パラメータ | 方法 | 正確度 |
|---|---|---|---|---|
| MedMCQA | GPT-4 | – | few-shot | 72.4 |
| MedMCQA | Flan-PaLM | 540B | few-shot | 57.6 |
| MedMCQA | BioMedLM | 2.7B | fine-tune | 57.3 |
| MedMCQA | Galactica | 120B | zero-shot | 52.9 |
| MedMCQA | GPT-3.5 | 175B | few-shot | 51.0 |
| MedQA | Med-PaLM 2 | – | closed, few-shot | 85.4 |
| MedQA | GPT-4 | – | closed, few-shot | 81.4 |
| MedQA | Flan-PaLM | 540B | closed, few-shot | 67.2 |
| MedQA | BioMedLM (MedMCQA data + classifier) | 2.7B | fully open, fine-tune | 54.7 |
| MedQA | GPT-3.5 | 175B | closed, few-shot | 53.6 |
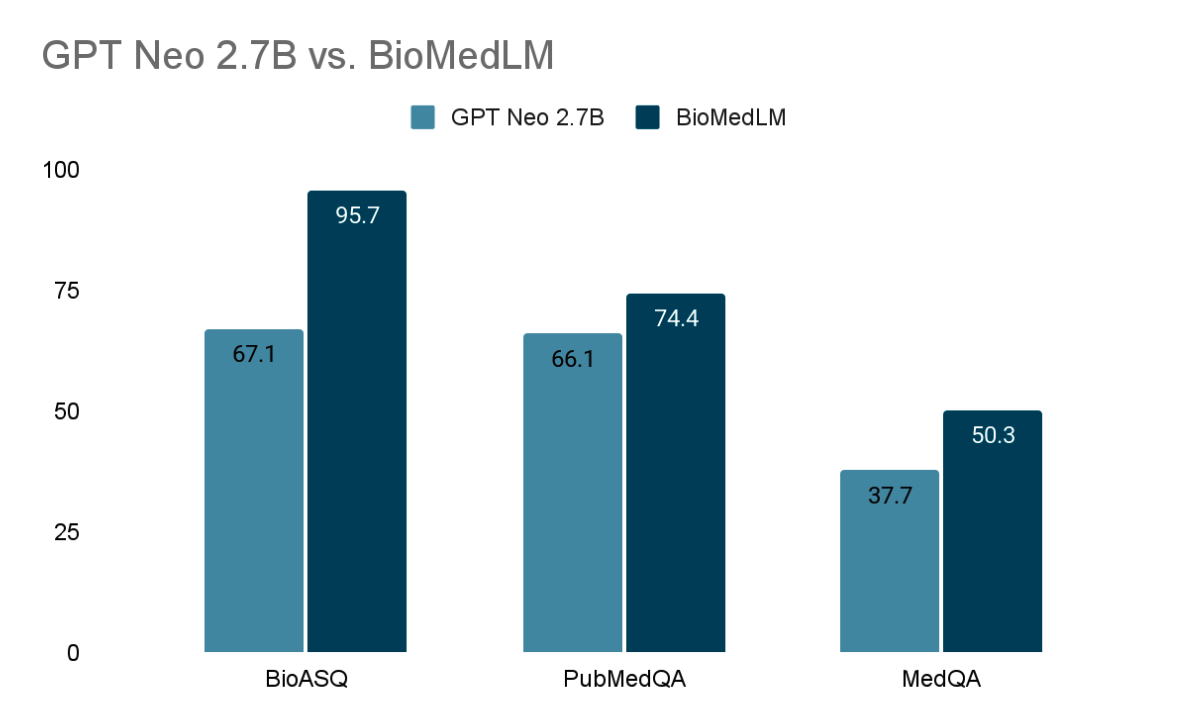
| MedQA | BioMedLM (classifier) | 2.7B | fully open, fine-tune | 50.3 |
| MedQA | DRAGON | 360M | fully open, fine-tune | 47.5 |
| MedQA | BioLinkBERT | 340M | fully open, fine-tune | 45.1 |
| MedQA | Galactica | 120B | open weights, zero-shot | 44.4 |
| MedQA | GPT-Neo 2.7B | 2.7B | fully open, fine-tune | 37.7 |
| BioASQ | BioMedLM | 2.7B | fine-tune | 95.7 |
| BioASQ | DRAGON | 360M | fine-tune | 96.4 |
| BioASQ | BioLinkBERT | 340M | fine-tune | 94.9 |
| BioASQ | Galactica | 120B | zero-shot | 94.3 |
| BioASQ | GPT-Neo 2.7B | 2.7B | fine-tune | 67.1 |
| PubMedQA | BioMedLM | 2.7B | fine-tune | 74.4 |
- BioMedLM はファインチューニング後に複数の生物医学 QA ベンチマークで競争力のある結果を達成し、いくつかのタスクで大規模モデルに近づくまたは上回る(例:MedMCQA 57.3%、MMLU Medical Genetics 69.0%)。
- PubMed 上のドメイン固有の事前訓練と専門トークナイザーは、GPT-2/トークナイザーベースラインより顕著な利得をもたらす(例:125M スケールで MedQA が 33.05 から 34.98 へ改善)。
- GPT-Neo 2.7B が一般英語データで訓練された場合と比べて、BioMedLM は選択された QA タスクで顕著に上回る(例:BioASQ で 27 ポイントの改善)。
- BioMedLM はオンデバイス推論をサポートし、比較的低性能なハードウェアでファインチューニング可能で、訓練データとアーキテクチャに関する透明性を提供する。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。