[論文レビュー] BlackMamba: Mixture of Experts for State-Space Models
BlackMamba は Mamba の状態空間ブロックを Mixture-of-Experts ルーティングと組み合わせ、線形時間生成と訓練/推論 FLOP の削減を実現。オープンソースの 340M/1.5B および 630M/2.8B モデルが 300B トークンで訓練。
State-space models (SSMs) have recently demonstrated competitive performance to transformers at large-scale language modeling benchmarks while achieving linear time and memory complexity as a function of sequence length. Mamba, a recently released SSM model, shows impressive performance in both language modeling and long sequence processing tasks. Simultaneously, mixture-of-expert (MoE) models have shown remarkable performance while significantly reducing the compute and latency costs of inference at the expense of a larger memory footprint. In this paper, we present BlackMamba, a novel architecture that combines the Mamba SSM with MoE to obtain the benefits of both. We demonstrate that BlackMamba performs competitively against both Mamba and transformer baselines, and outperforms in inference and training FLOPs. We fully train and open-source 340M/1.5B and 630M/2.8B BlackMamba models on 300B tokens of a custom dataset. We show that BlackMamba inherits and combines both of the benefits of SSM and MoE architectures, combining linear-complexity generation from SSM with cheap and fast inference from MoE. We release all weights, checkpoints, and inference code open-source. Inference code at: https://github.com/Zyphra/BlackMamba
研究の動機と目的
- 密なトランスフォーマーよりも効率性とスケーラビリティを向上させるため、状態空間モデル(SSM)とMixture-of-Experts(MoE)の組み合わせを動機づける。
- 注意機構の代わりに Mamba ブロックを用い、MLP コンポーネントに MoE ルーティングを組み込んで BlackMamba を設計・実装する。
- 性能、訓練 FLOPs、推論効率の観点で、BlackMamba を Mamba およびトランスフォーマーのベースラインと経験的に評価する。
- 大規模な BlackMamba 変種の拡張訓練を示し、モデル重みと推論コードをコミュニティ利用向けに公開する。
提案手法
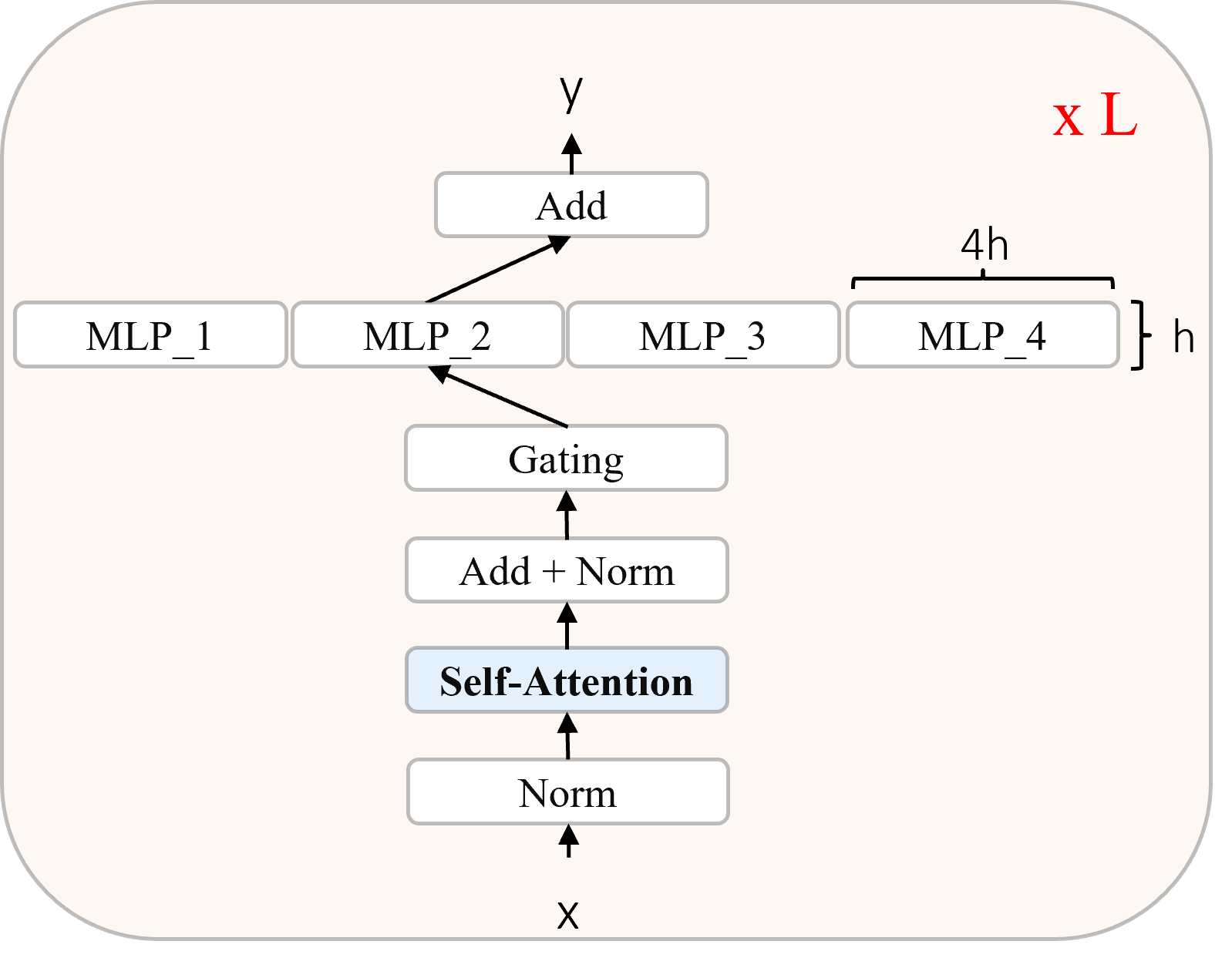
- 注意機構を備えない Mamba ブロックとルーティングされた MoE 層を交互に積み重ねたスタック型アーキテクチャとして BlackMamba を導入する。
- 式 (4) の SSM 行列 A, B, C を入力に依存するゲーティングで x(t) に依存させる。
- 層ごとに 8 個の MoE エキスパート間の負荷を均等化するため、Sinkhorn に基づく最適化器を用いた top-1 ルーティングを適用する。
- 1.8–2.0 兆トークンの混合データセットで、2 種類のモデルサイズ (340M/1.5B および 630M/2.8B の前方パラメータ総数) を訓練する。
- Megatron-LM フレームワークを用いて bf16 精度で訓練する;MoE ブロックあたり 8 エキスパートを有効化;バイアスを無効化;エキスパート MLP で SwiGLU を使用。
- 推論コードと Apache 2.0 の下でのオープンソースのチェックポイントを提供する。
実験結果
リサーチクエスチョン
- RQ1Mamba に似た状態空間ブロックと MoE ルーティングを組み合わせることで、スケールするときに競争力のある言語モデリング性能を得つつ、訓練および推論 FLOP を削減できるか?
- RQ2BlackMamba モデルは、生成遅延および長い文脈処理において、 Dense Transformer および純粋な Mamba のベースラインとどう比較されるか?
- RQ3深さと訓練時間にわたる BlackMamba での MoE ルーティングの挙動はどうで、Sinkhorn ルーティングの初期化が収束に与える影響は何か?
- RQ4大規模なマルチデータセット前処理コーパス上で BlackMamba 変種を訓練する際のデータおよびパラメータ効率はどれくらいか?
主な発見
- BlackMamba は dense transformers および純粋な Mamba ベースラインよりも大幅に低い訓練 FLOPs と高速な推論で、競争力のある評価性能を達成する。
- 長いシーケンス長で特に、BlackMamba の推論待機時間は、線形時間の SSM 生成とスパース MoE ルーティングの組み合わせによって、標準的なトランスフォーマーおよび同等の MoE トランスフォーマーよりも実質的に高速である。
- ほとんどの層は Sinkhorn ベースのルーティングでエキスパートの利用が良くバランスしているが、最終層には新たな専門化/不均衡パターンが顕在化し、さらなる研究が必要。
- 2 つのオープンソース BlackMamba 構成 (340M/1.5B および 630M/2.8B) が 300B トークンで訓練され、ウェイトと推論コードをコミュニティ利用のため公開。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。