[論文レビュー] BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models
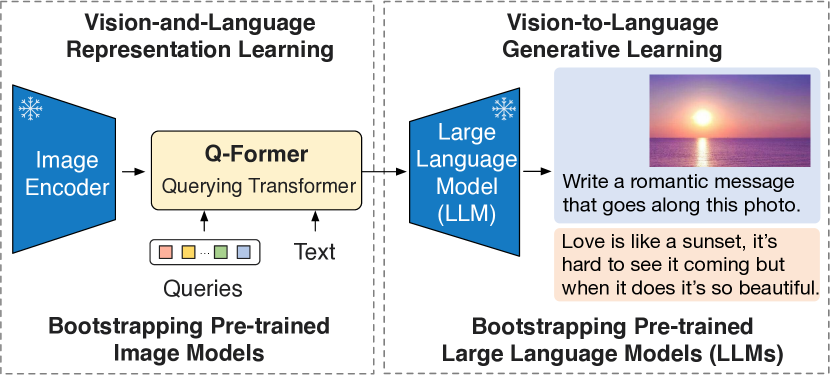
BLIP-2 は、凍結された事前訓練済み画像エンコーダと凍結された大規模言語モデルを、軽量な Querying Transformer を用いてブートストラップしたビジョン-ランゲージ事前訓練を実現し、訓練可能パラメータを大幅に削減しつつ、ゼロショットおよび指示付きの画像からテキスト生成で高い性能を達成します。
The cost of vision-and-language pre-training has become increasingly prohibitive due to end-to-end training of large-scale models. This paper proposes BLIP-2, a generic and efficient pre-training strategy that bootstraps vision-language pre-training from off-the-shelf frozen pre-trained image encoders and frozen large language models. BLIP-2 bridges the modality gap with a lightweight Querying Transformer, which is pre-trained in two stages. The first stage bootstraps vision-language representation learning from a frozen image encoder. The second stage bootstraps vision-to-language generative learning from a frozen language model. BLIP-2 achieves state-of-the-art performance on various vision-language tasks, despite having significantly fewer trainable parameters than existing methods. For example, our model outperforms Flamingo80B by 8.7% on zero-shot VQAv2 with 54x fewer trainable parameters. We also demonstrate the model's emerging capabilities of zero-shot image-to-text generation that can follow natural language instructions.
研究の動機と目的
- 軽量な Q-Former でモダリティ間を橋渡しし、単一モーダルモデルを凍結することで、ビジョン-ランゲージの事前訓練コストを削減する。
- 凍結した画像エンコーダからの表現学習と凍結した LLM からの生成学習という二段階の事前訓練を通じて、跨モーダル整合を学習する。
- 指示付きのゼロショット画像からテキスト生成と、改善された効率性によるより広範な VLP 能力を実証する。
- BLIP-2 が視覚モデルと言語モデルの進歩を活用して、訓練可能パラメータを少なくしつつ強い成果を達成できることを示す。
提案手法
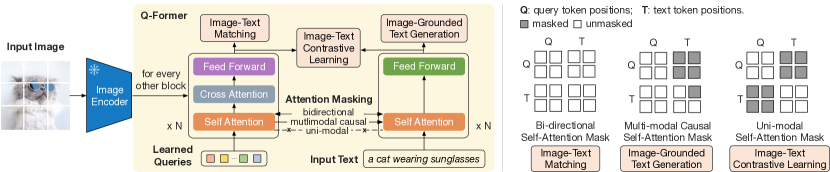
- 凍結した画像エンコーダと凍結した LLM を橋渡しする、学習可能なクエリを持つ小型トランスフォーマーである Q-Former を提案する。
- ステージ1:凍結した画像エンコーダとモダリティマスク付き注意を用いて、ITC、ITG、ITM 目標を用いたビジョン-ランゲージ表現学習。
- ステージ2:Q-Former の出力を LLM に射影し、言語モデル損失(デコーダーベースの LLM)または prefix-language modeling(エンコーダ-デコーダ LLM)で訓練する、ビジョンから言語への生成学習。
- L M L を凍結したまま、Q-Former と画像エンコーダを更新しつつ、下流タスク(VQA、キャプション、検索)に BLIP-2 をファインチューニング。
- CapFilt+キュレーションおよびインバッチネガティブを使用して、多様なソースからの 129M の画像-テキストペアを訓練に用いる。
実験結果
リサーチクエスチョン
- RQ1凍結した画像エンコーダと凍結した大規模言語モデルから構築されたビジョン-ランゲージ事前訓練フレームワークが、単一の軽量なブリッジモジュールから最先端の性能を達成できるのか?
- RQ2大規模なバックボーンを更新せずに、最小限の querying メカニズム(Q-Former)がどのように効果的な跨モーダル整合を可能にするか?
- RQ3凍結した単一モーダルモデルを用いた場合の、指示付きゼロショット画像からテキスト生成の新出現能力は何か?
- RQ4訓練可能パラメータと計算量の観点で、BLIP-2 の効率はエンドツーエンドの大規模ビジョン-ランゲージ事前訓練法とどのように比較されるか?
主な発見
- BLIP-2 は、エンドツーエンド法よりはるかに少ない訓練可能パラメータ(188M)で強力なゼロショットのビジョン-ランゲージ性能を達成し、ゼロショット VQAv2 で Flamingo80B を 8.7% 上回る。
- 二段階の事前訓練(表現学習とビジョンから言語への生成)は、凍結した画像エンコーダと凍結した LLM の間で効果的な橋渡しを可能にする。
- BLIP-2 は指示付きゼロショット画像からテキスト生成をサポートし、視覚的知識推論や視覚的会話などのタスクを可能にする。
- この手法は計算効率を示し、例えば単一の 16-A100 (40G) マシンで大規模バリアントの事前訓練手順を数日で完了できる。
- BLIP-2 の結果は、より大きな視覚エンコーダとより大きな LLM が、VQA、キャプション、検索タスク全般で一貫して性能を向上させることを示している。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。