[論文レビュー] BLIP-Diffusion: Pre-trained Subject Representation for Controllable Text-to-Image Generation and Editing
BLIP-Diffusionは、ゼロショットおよびファ few-shot subject-driven text-to-image生成を可能にする事前学習済みのマルチモーダル・サブジェクト表現を導入し、効率的な微調整とControlNetおよびprompt-to-promptによる編集との互換性を提供します。
Subject-driven text-to-image generation models create novel renditions of an input subject based on text prompts. Existing models suffer from lengthy fine-tuning and difficulties preserving the subject fidelity. To overcome these limitations, we introduce BLIP-Diffusion, a new subject-driven image generation model that supports multimodal control which consumes inputs of subject images and text prompts. Unlike other subject-driven generation models, BLIP-Diffusion introduces a new multimodal encoder which is pre-trained to provide subject representation. We first pre-train the multimodal encoder following BLIP-2 to produce visual representation aligned with the text. Then we design a subject representation learning task which enables a diffusion model to leverage such visual representation and generates new subject renditions. Compared with previous methods such as DreamBooth, our model enables zero-shot subject-driven generation, and efficient fine-tuning for customized subject with up to 20x speedup. We also demonstrate that BLIP-Diffusion can be flexibly combined with existing techniques such as ControlNet and prompt-to-prompt to enable novel subject-driven generation and editing applications. Code and models will be released at https://github.com/salesforce/LAVIS/tree/main/projects/blip-diffusion. Project page at https://dxli94.github.io/BLIP-Diffusion-website/.
研究の動機と目的
- 効率的でスケーラブルなサブジェクト主導生成を動機付け、過度な微調整なしにサブジェクト忠実性を維持する。
- テキストと整合するガイドとしての、事前学習済みの汎用サブジェクト表現を開発する。
- ほとんど微調整ステップを大幅に削減して、サブジェクトのゼロショットおよび少数ショットのパーソナライズを実現する。
提案手法
- 2段階の事前学習: (1) BLIP-2スタイルのエンコーダを用いて画像特徴とテキストを整合させるマルチモーダル表現学習; (2) 拡散モデルが視覚特徴からサブジェクト描写を生成する方式のサブジェクト表現学習。
- BLIP-2マルチモーダルエンコーダを用いて、サブジェクト画像とカテゴリテキストからテキストと整合するサブジェクト表現を生成する。
- BLIP-2出力を射影してテキストプロンプトと結合することで、拡散モデルにソフトな視覚サブジェクトプロンプトを注入する([text prompt], the [subject text] is [subject prompt]のようなテンプレート)。
- 微調整時には過剰適合を防ぐため拡散モデルのテキストエンコーダを凍結する;サブジェクト特化生成のために数ステップ(40-120)で微調整を行う。
- ControlNetによる構造制御と、cross-attentionマップを操作するprompt-to-promptスタイルの編集を可能とするモジュール拡張を有効化する。
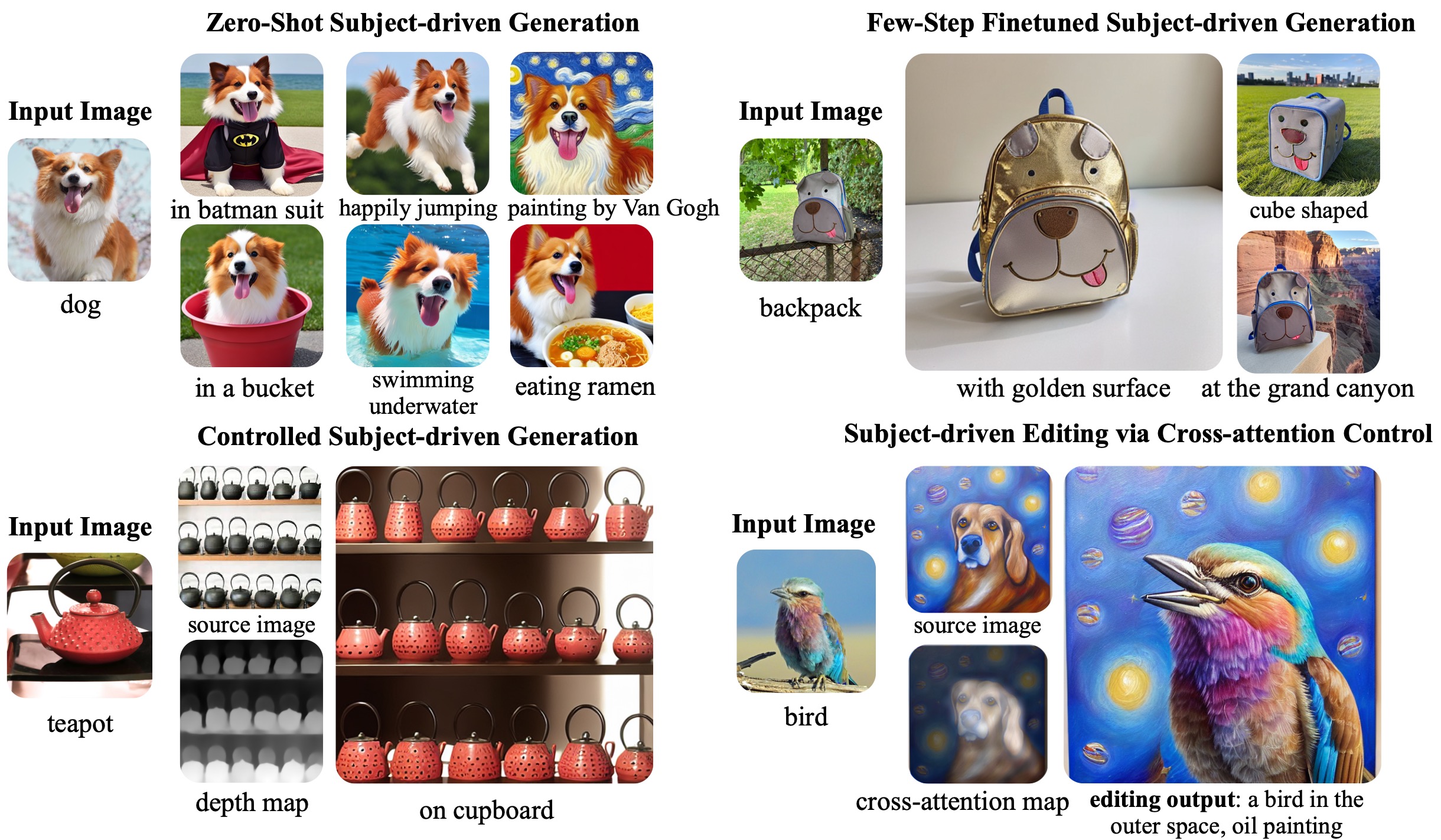
実験結果
リサーチクエスチョン
- RQ1事前学習済みのマルチモーダルサブジェクト表現は、高忠実度のゼロショットサブジェクト主導生成を可能にするか。
- RQ2新しいサブジェクトを特化させるには、従来の方法と比較してどれくらいの微調整ステップが必要か。
- RQ3サブジェクト表現を、基盤モデルを再学習させることなく、既存の編集/構造制御技術(ControlNet、prompt-to-prompt)と効果的に組み合わせられるか。
- RQ4モデルは、マルチモーダル制御を提供しつつ、コアな拡散モデルの機能を維持しているか。
- RQ52段階の事前学習が、サブジェクトの視覚情報とテキストプロンプトの整合性にどう影響するか。
主な発見
| 方法 | DINO | CLIP-I | CLIP-T |
|---|---|---|---|
| Real Images (Oracle) | 0.774 | 0.885 | - |
| Textual Inversion | 0.569 | 0.780 | 0.255 |
| Re-Imagen | 0.600 | 0.740 | 0.270 |
| DreamBooth | 0.668 | 0.803 | 0.305 |
| – 100 fine-tuning steps | 0.396 | 0.698 | 0.322 |
| – 300 fine-tuning steps | 0.500 | 0.733 | 0.319 |
| Ours (ZS) | 0.594 (±0.004) | 0.779 (±0.003) | 0.300 (±0.002) |
| Ours (FT, avg. < 80 steps) | 0.670 (±0.004) | 0.805 (±0.002) | 0.302 (±0.001) |
- BLIP-Diffusionは高いサブジェクト忠実性を伴うゼロショットのサブジェクト主導生成を実現する。
- 微調整は40–120ステップを要し、DreamBoothなど従来手法と比べて最大20倍高速。
- ControlNetやprompt-to-promptと組み合わせると、サブジェクト固有のビジュアルを用いた構造制御生成と編集をサポートする。
- 定量的指標はTextual InversionやRe-Imagenと同等かそれ以上の性能を示し、微調整が比較的少なくてもDreamBoothに近い結果を得られる。
- アブレーションでは、マルチモーダル事前学習と凍結選択の重要性が、サブジェクト表現を活用しつつテキスト制御を維持する上で示された。
- サブジェクト表現は局所的および全体的なサブジェクト特徴を捉え、柔軟な編集とスタイル転送機能を可能にする。
![Figure 2: Illustration of the two-staged pre-training for BLIP-Diffusion. Left : in the multimodal representation learning stage, we follow prior work [ 12 ] and pretrain BLIP-2 encoder to obtain text-aligned image representation. Right : in the subject representation learning stage, we synthesize i](https://ar5iv.labs.arxiv.org/html/2305.14720/assets/x1.png)
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。