[論文レビュー] BOLAA: Benchmarking and Orchestrating LLM-augmented Autonomous Agents
BOLAA はさまざまな LAA アーキテクチャを異なる LLM バックボーンでベンチマークし、専門の LAAs を統括するマルチエージェント コントローラを導入して、意思決定と知識推論タスクで評価します。
The massive successes of large language models (LLMs) encourage the emerging exploration of LLM-augmented Autonomous Agents (LAAs). An LAA is able to generate actions with its core LLM and interact with environments, which facilitates the ability to resolve complex tasks by conditioning on past interactions such as observations and actions. Since the investigation of LAA is still very recent, limited explorations are available. Therefore, we provide a comprehensive comparison of LAA in terms of both agent architectures and LLM backbones. Additionally, we propose a new strategy to orchestrate multiple LAAs such that each labor LAA focuses on one type of action, extit{i.e.} BOLAA, where a controller manages the communication among multiple agents. We conduct simulations on both decision-making and multi-step reasoning environments, which comprehensively justify the capacity of LAAs. Our performance results provide quantitative suggestions for designing LAA architectures and the optimal choice of LLMs, as well as the compatibility of both. We release our implementation code of LAAs to the public at \url{https://github.com/salesforce/BOLAA}.
研究の動機と目的
- LAA アーキテクチャがさまざまな LLM バックボーン上でどのようにパフォーマンスを発揮するかを評価する。
- アーキテクチャと LLM の組み合わせのうち、タスク性能が最も高い組み合わせを特定する。
- コントローラを介して複数の専門 LAAs を調整する利点を調査する。
- スケーラブルな LAA システムの設計選択に関するガイダンスを提供する。
- 再現性を促進するオープンソース実装を公開する。
提案手法
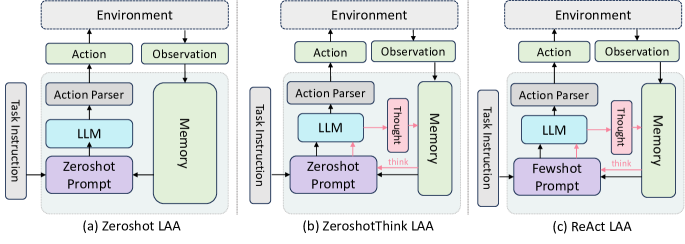
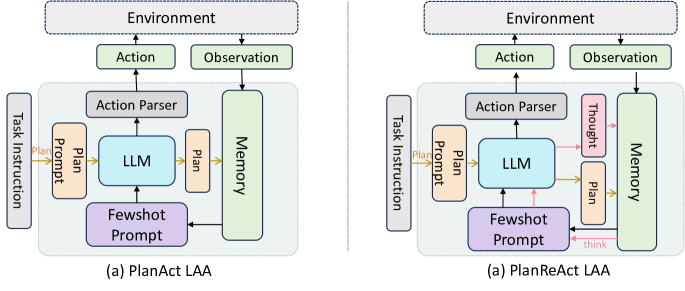
- prompting、self-thinking、planning のバリアントを網羅した 6 種類のソロ LAA アーキテクチャを構築する。
- アーキテクチャを複数のバックボーン LLM と組み合わせて広範な評価マトリクスを作成する。
- BOLAA: 専門の labo LAAs(例:別々のクリックエージェントと検索エージェント)へアクションをルーティングするコントローラベースのアーキテクチャを提案する。
- WebShop(ウェブナビゲーション)と HotPotQA(多段階知識推論)環境で評価する。
- 最終報酬と中間リコールを報告し、有効性と通信品質を評価する。
実験結果
リサーチクエスチョン
- RQ1さまざまな LAA アーキテクチャが、ウェブナビゲーションと推論タスクで多様な LLM バックボーンと組み合わせた場合、どのようにパフォーマンスを発揮するか?
- RQ2コントローラを介して複数の専門 LAAs を調整する(BOLAA)が、ソロエージェントと比較して性能を改善するか?
- RQ3文脈長とモデルサイズがアーキテクチャ間で LAA の有効性に与える影響はどの程度か?
- RQ4どの LLM バックボーンとアーキテクチャの組み合わせがオープンドメインのタスクと計画シナリオへ最も良く一般化するか?
主な発見
| LLM | Len. | LAA アーキテクチャ | ZS | ZST | ReAct | PlanAct | PlanReAct | BOLAA |
|---|---|---|---|---|---|---|---|---|
| fastchat-t5-3b | 2k | 0.3971 | 0.2832 | 0.3098 | 0.3837 | 0.1507 | 0.5169 | |
| vicuna-7b | 2k | 0.0012 | 0.0002 | 0.1033 | 0.0555 | 0.0674 | 0.0604 | |
| vicuna-13b | 2k | 0.0340 | 0.0451 | 0.1509 | 0.3120 | 0.4127 | 0.5350 | |
| vicuna-33b | 2k | 0.1356 | 0.2049 | 0.1887 | 0.3692 | 0.3125 | 0.5612 | |
| llama-2-7b | 4k | 0.0042 | 0.0068 | 0.1248 | 0.3156 | 0.2761 | 0.4648 | |
| llama-2-13b | 4k | 0.0662 | 0.0420 | 0.2568 | 0.4892 | 0.4091 | 0.3716 | |
| llama-2-70b | 4k | 0.0122 | 0.0080 | 0.4426 | 0.2979 | 0.3770 | 0.5040 | |
| mpt-7b-instruct | 8k | 0.0001 | 0.0001 | 0.0573 | 0.0656 | 0.1574 | 0.0632 | |
| mpt-30b-instruct | 8k | 0.1664 | 0.1255 | 0.3119 | 0.3060 | 0.3198 | 0.4381 | |
| xgen-8k-7b-instruct | 8k | 0.0001 | 0.0015 | 0.0685 | 0.1574 | 0.1004 | 0.3697 | |
| longchat-7b-16k | 16k | 0.0165 | 0.0171 | 0.0690 | 0.0917 | 0.1322 | 0.1964 | |
| longchat-13b-16k | 16k | 0.0007 | 0.0007 | 0.2373 | 0.3978 | 0.4019 | 0.3205 | |
| text-davinci-003 | 4k | 0.5292 | 0.5395 | 0.5474 | 0.4751 | 0.4912 | 0.6341 | |
| gpt-3.5-turbo | 4k | 0.5061 | 0.5057 | 0.5383 | 0.4667 | 0.5483 | 0.6567 | |
| gpt-3.5-turbo-16k | 16k | 0.5657 | 0.5642 | 0.4898 | 0.4565 | 0.5607 | 0.6541 |
- BOLAA は、テストされたほとんどの LLM で最も高い報酬を達成する傾向があり、専門化された統括型エージェントの利点を示している。
- LLM とアーキテクチャの最適な組み合わせはタスクとモデル依存であり(例:PlanAct、PlanReAct、または BOLAA がモデル間で異なるパフォーマンスを示す)。
- より大きく、より能力の高い LLM はしばしば小さなものより優れているが、極端に長い文脈は幻聖を引き起こし、必ずしも結果を改善しない。
- Plan フローはオープンソース LLM には有用である傾向がある一方、知識推論タスクでは事前計画のずれにより計画が妨げになることがある。
- WebShop では、専門の labor LAAs(検索とクリック)を備えた BOLAA が一貫して高い性能とリコールを発揮する;HotPotQA では ReAct ベースのアーキテクチャが few-shot プロンプトで優れる。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。