[論文レビュー] Brain in a Vat: On Missing Pieces Towards Artificial General Intelligence in Large Language Models
本論文は現在のLLM評価を批判し、それらが能力を過大評価していると主張するとともに、真の汎用人工知能に向けた欠落要素を概説し、現実世界での相互作用と試行錯誤による学習を通じた「知ること」と「行うこと」の統合を強調している。
In this perspective paper, we first comprehensively review existing evaluations of Large Language Models (LLMs) using both standardized tests and ability-oriented benchmarks. We pinpoint several problems with current evaluation methods that tend to overstate the capabilities of LLMs. We then articulate what artificial general intelligence should encompass beyond the capabilities of LLMs. We propose four characteristics of generally intelligent agents: 1) they can perform unlimited tasks; 2) they can generate new tasks within a context; 3) they operate based on a value system that underpins task generation; and 4) they have a world model reflecting reality, which shapes their interaction with the world. Building on this viewpoint, we highlight the missing pieces in artificial general intelligence, that is, the unity of knowing and acting. We argue that active engagement with objects in the real world delivers more robust signals for forming conceptual representations. Additionally, knowledge acquisition isn't solely reliant on passive input but requires repeated trials and errors. We conclude by outlining promising future research directions in the field of artificial general intelligence.
研究の動機と目的
- 既存の標準化評価と能力指向の評価をレビューし、LLMsの能力の過大評価を特定する。
- LLMsを超える人工汎用知能が含むべき枠組みを提案する。
- 行動、世界の基盤づけ、経験的知識獲得に焦点を当て、AGIに向けて欠如している要素を強調する。
提案手法
- LLMsを評価するために用いられる標準化テストと能力指向ベンチマークの系統的レビュー。
- 記号のグラウンディング、世界との相互作用、知識獲得に関する知見の批判的総合。
- 一般的な知性を有するエージェントの4つの特徴の概念的整理。
- LLMsをAGIとして疑問視する実証的証拠の検討と将来の研究方向の概説。
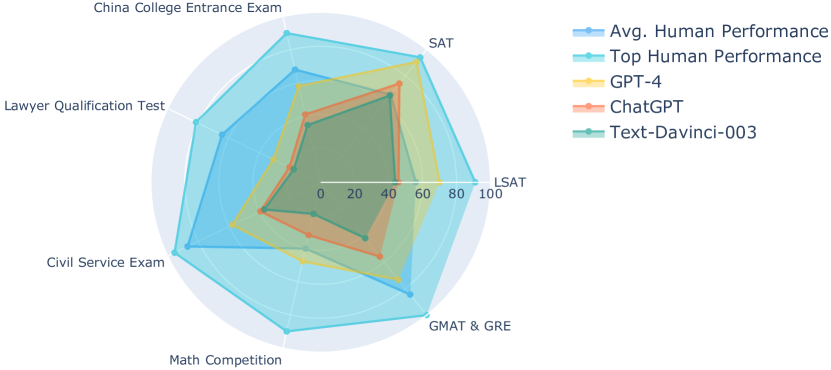
実験結果
リサーチクエスチョン
- RQ1一般知能を捉えるうえで、現在のLLM評価方法論の限界は何か?
- RQ2LLMsが示す能力を超えた、人工汎用知能とは何を意味するのか?
- RQ3知ることと行うことをAIシステムで結びつけるうえで、鍵となる欠落要素は何か?
主な発見
- LLMsは言語ベースのテストで高いパフォーマンスを示す一方、訓練データが少ない教科領域での推論や問題解決に苦戦する。
- データのバイアスや指標の選択により、評価方法論がLLMの能力を過大評価する可能性がある。
- 複数の領域の証拠は、LLMsがショートカットに頼り、堅牢な記号的理解を欠き、分布外の因果推論や抽象的推論タスクで失敗することを示している。
- 堅牢な概念表現と一般化のためには、記号のグラウンディングと現実世界での相互作用が不可欠であると示されている。
- 著者らは、世界への能動的な関与、試行錯誤的学習、基づいた知識獲得を統合する将来のAGI方向性を主張している。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。