[論文レビュー] Bridging Language and Items for Retrieval and Recommendation
BLaIR は、ユーザーの言語コンテキストとアイテムメタデータを結びつけて検索と推奨を改善する一連の事前学習済み文表現モデルを導入し、巨大な Amazon Reviews 2023 データセットで訓練し、シーケンシャル推奨と複雑な商品検索タスクで評価しました。
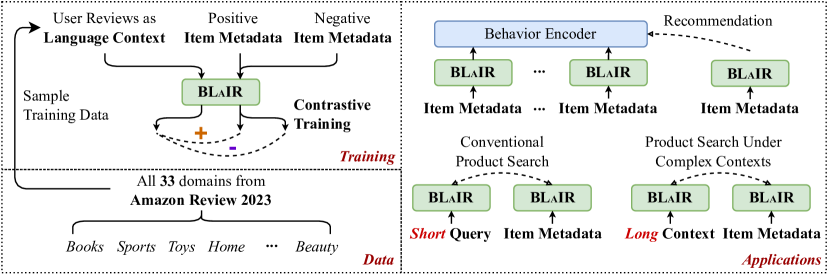
This paper introduces BLaIR, a series of pretrained sentence embedding models specialized for recommendation scenarios. BLaIR is trained to learn correlations between item metadata and potential natural language context, which is useful for retrieving and recommending items. To pretrain BLaIR, we collect Amazon Reviews 2023, a new dataset comprising over 570 million reviews and 48 million items from 33 categories, significantly expanding beyond the scope of previous versions. We evaluate the generalization ability of BLaIR across multiple domains and tasks, including a new task named complex product search, referring to retrieving relevant items given long, complex natural language contexts. Leveraging large language models like ChatGPT, we correspondingly construct a semi-synthetic evaluation set, Amazon-C4. Empirical results on the new task, as well as conventional retrieval and recommendation tasks, demonstrate that BLaIR exhibit strong text and item representation capacity. Our datasets, code, and checkpoints are available at: https://github.com/hyp1231/AmazonReviews2023.
研究の動機と目的
- 数百万件のアイテムを含む状況で、言語を重視した検索と推奨を推進する。
- ナチュラル言語とアイテムメタデータを結ぶ、軽量で専門的なモデルファミリを提案する。
- 事前学習のために、大規模で最新の Amazon Reviews 2023 データセットを作成・活用する。
- 新しい複雑な商品検索タスクを導入し評価する。
- 複数のドメインとタスクにわたる汎化を評価し、Amazon-C4 を用いた半合成評価を含む。
提案手法
- 言語コンテキスト c とアイテムメタデータ m を対になる対照的目的で結ぶ形式で、一連の sentence-embedding モデル(BLaIR)を事前学習する。
- バックボーンアーキテクチャには RoBERTa ベースのエンコーダを含む。埋め込み s は [CLS] トークン表現である。
- 監視付き対比損失 L_CL = -sum_i log exp(c_i · m_i / τ) / sum_j exp(c_i · m_j / τ) で訓練する。
- 訓練を安定させるための補助目的 L_PT(例:RoBERTa/BERT の MLM、T5 のデノイズ)を用い、L = L_CL + λ L_PT とする。
- Amazon Reviews 2023 から、レビューコンテキストとアイテムメタデータをペアリングし、汚染を避けるために固定タイムスタンプでデータを分割してデータを準備する。
- シーケンシャル推奨、従来の商品検索、および新しい複雑な商品検索タスクで評価する。半合成評価のために ChatGPT を介して Amazon-C4 を作成する。
実験結果
リサーチクエスチョン
- RQ1言語を意識したアイテム表現は、複数のドメインで検索と推奨を改善できるか。
- RQ2複数ドメインの事前学習と対照的目的は、複雑な商品検索のような新しいタスクに一般化するか。
- RQ3零-shot 設定における BLaIR は、従来の ID ベースおよび他のテキストベースのアイテム表現とどのように比較されるか。
- RQ4データカリキュラムとマルチドメイン訓練がモデル性能に与える影響は何か。
主な発見
- BLaIR はゼロショット設定で、複数のドメインとタスクにおいて既存手法を上回る。
- テキストベースの表現は、BLaIR を用いる場合、評価データセット全体で ID ベースの手法を一般的に上回る。
- モデルパラメータを拡張(123M から 354M)し、混合専門家アダプターを使用(SASRec から UniSRec)することで性能向上を得る。
- マルチドメインの事前学習は、ドメイン内訓練と比べて一般化を一般的に高める。
- 新たに導入された複雑な商品検索タスクで、Amazon-C4 データを用いて強い性能を示す。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。