[論文レビュー] BuildingsBench: A Large-Scale Dataset of 900K Buildings and Benchmark for Short-Term Load Forecasting
BuildingsBench は Buildings-900K を導入し、ほぼ100万のシミュレーション建物データセットと、実建物でのゼロショットSTLFと転移学習の評価プラットフォームを提供します。
Short-term forecasting of residential and commercial building energy consumption is widely used in power systems and continues to grow in importance. Data-driven short-term load forecasting (STLF), although promising, has suffered from a lack of open, large-scale datasets with high building diversity. This has hindered exploring the pretrain-then-fine-tune paradigm for STLF. To help address this, we present BuildingsBench, which consists of: 1) Buildings-900K, a large-scale dataset of 900K simulated buildings representing the U.S. building stock; and 2) an evaluation platform with over 1,900 real residential and commercial buildings from 7 open datasets. BuildingsBench benchmarks two under-explored tasks: zero-shot STLF, where a pretrained model is evaluated on unseen buildings without fine-tuning, and transfer learning, where a pretrained model is fine-tuned on a target building. The main finding of our benchmark analysis is that synthetically pretrained models generalize surprisingly well to real commercial buildings. An exploration of the effect of increasing dataset size and diversity on zero-shot commercial building performance reveals a power-law with diminishing returns. We also show that fine-tuning pretrained models on real commercial and residential buildings improves performance for a majority of target buildings. We hope that BuildingsBench encourages and facilitates future research on generalizable STLF. All datasets and code can be accessed from https://github.com/NREL/BuildingsBench.
研究の動機と目的
- 大規模な合成データが住宅および商業ビルのSTLFモデルの事前学習にどの程度価値をもたらすかを示す。
- シミュレーションデータと実データを組み合わせたオープンな評価プラットフォームを提供し、ゼロショットSTLFと転移学習を実現する。
- 合成事前学習から実建物への一般化と、ターゲットデータでのファインチューニングの利点を分析する。
- データセットサイズ、モデルサイズ、アーキテクチャがゼロショットと転移学習の性能に及ぼす影響を調査する。
提案手法
- NREL End-Use Load Profiles (EULP) 由来の 900K 建物モデルを含むシミュレーションデータセット Buildings-900K を導入する。
- 過去168時間の履歴と共変量に基づき、24時間先の負荷分布の確率分布を予測する確率的な短期負荷予測の定式化を採用する。
- Buildings-900K で 10億ロード・アワーを用いたトランスフォーマー型時系列モデル(ガウス型およびトークン化型)を事前学習し、実データセットでゼロショットと転移学習を評価する。
- 7つの公開データセット(BuildingsBench)から1,900件超の実建物評価スイートを提供する。
- Persistence、LightGBM、線形/ DLinear/ RNN 系、トランスフォーマー系予測器のファインチューニング有無を含むベースラインをベンチマークする。
- 点予測と不確実性の両方について、NRMSE と ranked probability score (RPS) で性能を評価する。
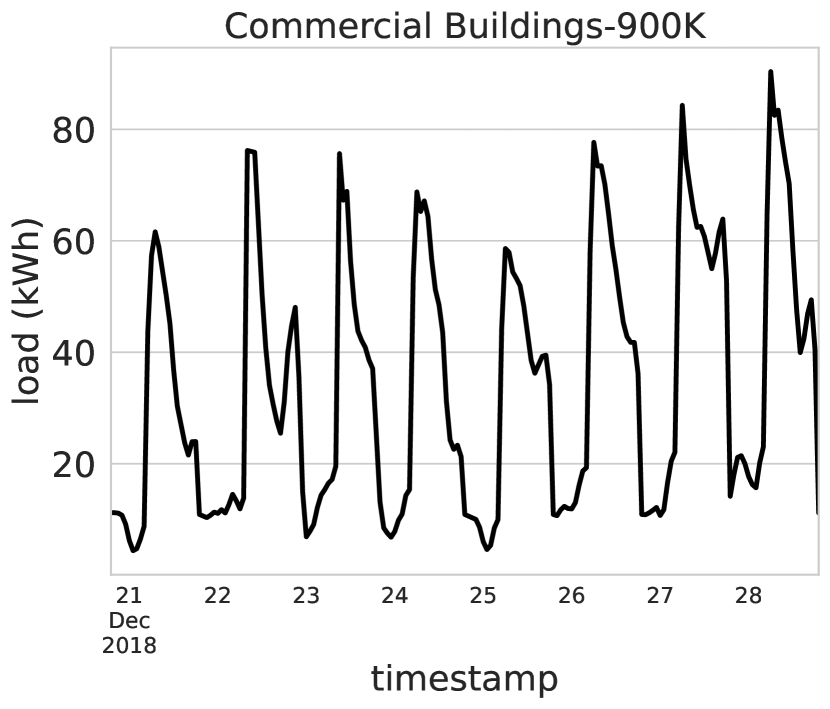
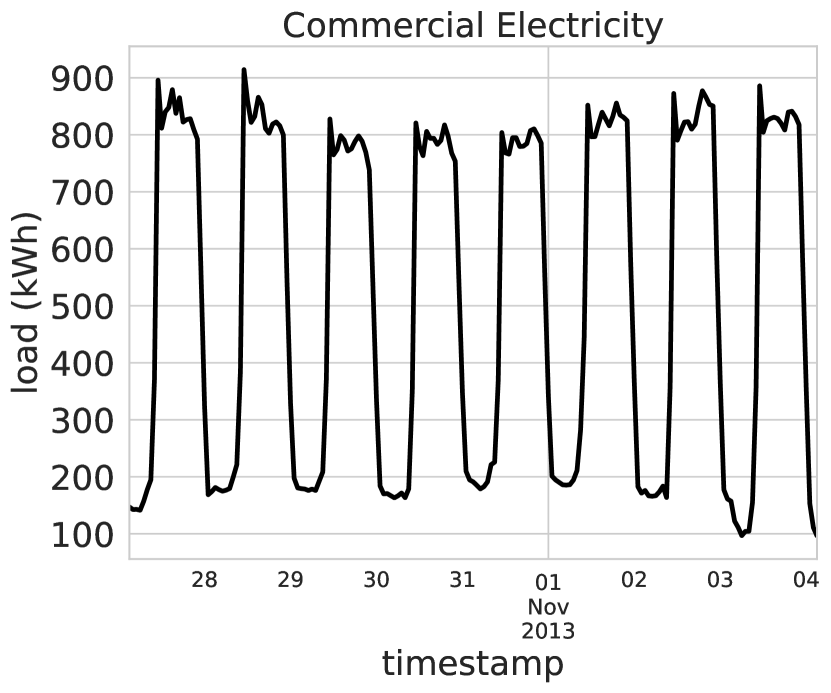
実験結果
リサーチクエスチョン
- RQ1Buildings-900K で事前学習したモデルは、特に商業ビルで実建物へ一般化できるか。
- RQ2限られた実データでのファインチューニングは、ターゲットビルの性能を向上させるか。
- RQ3事前学習データセット規模とモデル規模は、ゼロショット性能と実データへの一般化にどのように影響するか。
- RQ4大規模なSTLF事前学習では、連続負荷よりトークン化負荷での事前学習が有利か。
- RQ5地理空間と建物タイプの共変量を組み込むと、予測精度にどの程度影響するか。
主な発見
- Buildings-900K での事前学習は、実ビルの商業分野で強力なゼロショットSTLF性能をもたらす一方、住宅ビルではシミュレーションと実データの間にギャップがある。
- 6ヶ月分の実データで事前学習済みトランスフォーマをファインチューニングすると、商業・住宅ビルのSTLFが改善され、特に商業ケースで顕著な利得が得られる。
- 商業ビルのゼロショット性能はデータセット規模の増加とともにべき乗則に従い、収得は減衰する。一方で住宅ビルはシミュレーション実データ間の乖離が大きいため一般化が制限される。
- トランスフォーマー系 M モデルはファインチューニングから最大の利得を得て、大規模な事前学習ベースラインに近づくか同等になる一方、非常に大規模なモデルはゼロショット設定で飽和する可能性がある。
- トークン化された負荷表現(Tokens)は学習の安定性を提供するが、精度面では一般的にガウス型トランスフォーマより劣る。ただし量子化はデータを効果的に圧縮する。
- 地理空間共変量は精度向上を modest に提供し、位置情報付与が一般化をわずかに助けることを示唆する。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。