[論文レビュー] BurstGPT: A Real-world Workload Dataset to Optimize LLM Serving Systems
BurstGPTを初めて実世界のLLM提供ワークロードのトレースとして紹介し、バースト的なワークロード下でのLLM提供システムを評価・最適化するためのベンチマークスイート。
Serving systems for Large Language Models (LLMs) are often optimized to improve quality of service (QoS) and throughput. However, due to the lack of open-source LLM serving workloads, these systems are frequently evaluated under unrealistic workload assumptions. Consequently, performance may degrade when systems are deployed in real-world scenarios. This work presents BurstGPT, an LLM serving workload with 10.31 million traces from regional Azure OpenAI GPT services over 213 days. BurstGPT captures LLM serving characteristics from user, model and system perspectives: (1) User request concurrency: burstiness variations of requests in Azure OpenAI GPT services, revealing diversified concurrency patterns in different services and model types. (2) User conversation patterns: counts and intervals within conversations for service optimizations. (3) Model response lengths: auto-regressive serving processes of GPT models, showing statistical relations between requests and their responses. (4) System response failures: failures of conversation and API services, showing intensive resource needs and limited availability of LLM services in Azure. The details of the characteristics can serve multiple purposes in LLM serving optimizations, such as system evaluation and trace provisioning. In our demo evaluation with BurstGPT, frequent variations in BurstGPT reveal declines in efficiency, stability, or reliability in realistic LLM serving. We identify that the generalization of KV cache management, scheduling and disaggregation optimizations can be improved under realistic workload evaluations. BurstGPT is publicly available now at https://github.com/HPMLL/BurstGPT and is widely used to develop prototypes of LLM serving frameworks in the industry.
研究の動機と目的
- 実世界のLLM提供ワークロードの特徴を浮き彫りにし、システム設計とリソース割り当ての指針とする。
- 実世界のGPTサービス(ChatGPTとGPT-4)のバースト性・同時実行パターン・故障率を定量化する。
- BurstGPTのワークロードパターンを反映した、スケーラブルなベンチマークスイートを開発し、提供システムを評価する。
- LLM提供における弾力的なリソース管理とQoS向上の実現に役立つ知見を提供する。
提案手法
- キャンパス環境で2か月間、ChatGPTとGPT-4 APIおよび対話サービスのリアルタイムワークロードトレースを収集・分析する。
- LLMワークロードの時系列的(周期的/非周期的)および空間的(リクエスト長/レスポンス長)パターンを特徴付ける。
- ガンマ分布を用いてバースト性をモデル化し、GPUメモリとサービス信頼性への影響を示す。
- 観測されたワークロードパターンを反映し、異なるシステムサイズにスケールする対になるBurstGPTベンチマークを開発する。
- LLM提供システムを評価するための、プロンプトプール、同時実行生成器、HTTPベース推論ドライバを備えたワークロードジェネレータを試作する。
- BurstGPT様式のワークロード下でLlama-2-chatモデルに対するvLLMの評価を行い、待機時間、スループット、故障挙動を検討する。
実験結果
リサーチクエスチョン
- RQ1実世界のLLM提供ワークロードの時系列的および空間的特徴は何か?
- RQ2バースト性はLLM提供システムの信頼性とGPUメモリ使用量にどう影響するか?
- RQ3BurstGPTに基づくベンチマークスイートは、スケールを超えて提供システムを忠実に評価できるか?
- RQ4BurstGPT様式のバーストワークロード下で、先行するLLM提供フレームワーク(vLLM)はどのように性能を示すか?
主な発見
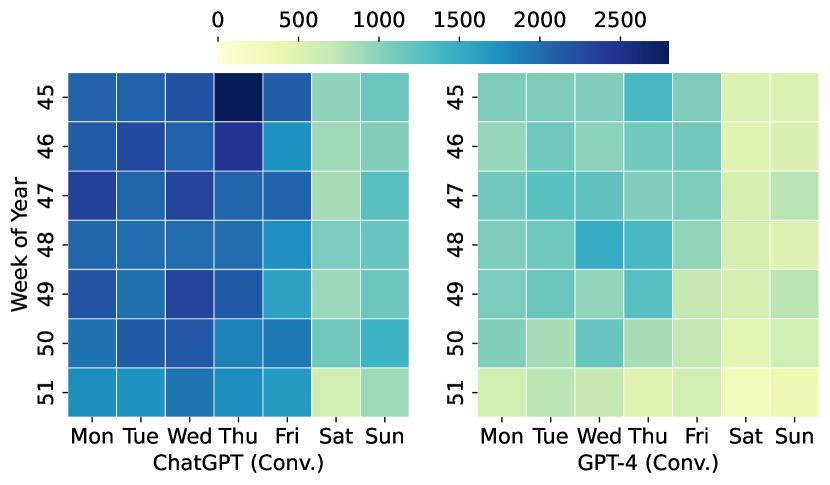
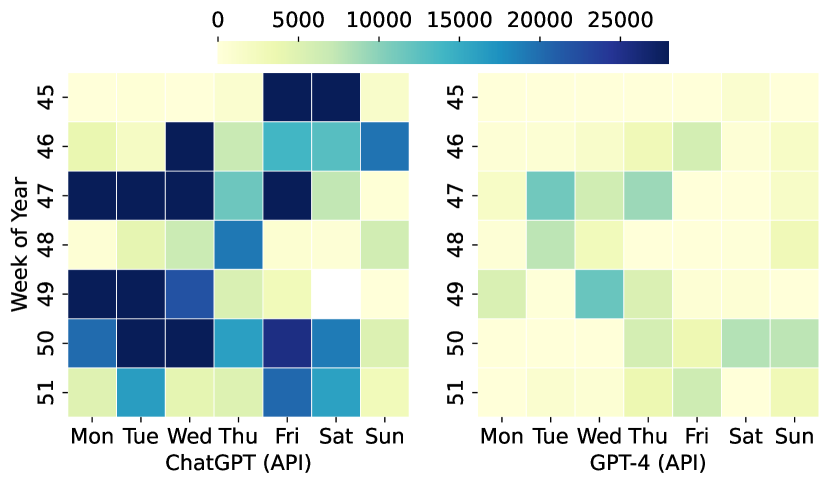
- LLMワークロードのバースト性は、サービス種別(対話 vs API)およびモデル(ChatGPT vs GPT-4)によって、周期的および非周期的パターンの両方を示す。
- 対話サービスはより規則的な日次パターンを示し、APIサービスは不規則でバースト的なトラフィックを示し、変動性が高い。
- リクエスト長はZipf様分布に従い、レスポンス長はモデル依存で、しばしば二峰性または長尾分布を示す。
- GPUメモリの逼迫はバースト性ワークロードと故障率の上昇と相関しており、メモリボトルネックが信頼性リスクの重要な要因であることを示している。
- BurstGPTベンチマークは実世界のバースト性を再現し、既存システムが短期のバースト下で性能低下を示すことを明らかにできる。
- BurstGPT様式のワークロード下でのvLLM評価は、バースト性とメモリ管理に対する感度を示し、待機時間と成功率に影響を及ぼす。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。