[論文レビュー] Cal-QL: Calibrated Offline RL Pre-Training for Efficient Online Fine-Tuning
Cal-QL は、参照ポリシーに対して Q 値を較正することで、オンラインのファインチューニングを高速化・サンプル効率化するよう、保守的なオフライン RL を拡張します。CQL を基盤とし、単純な較正制約を追加することで、多様なタスクにおけるオンライン性能を改善します。
A compelling use case of offline reinforcement learning (RL) is to obtain a policy initialization from existing datasets followed by fast online fine-tuning with limited interaction. However, existing offline RL methods tend to behave poorly during fine-tuning. In this paper, we devise an approach for learning an effective initialization from offline data that also enables fast online fine-tuning capabilities. Our approach, calibrated Q-learning (Cal-QL), accomplishes this by learning a conservative value function initialization that underestimates the value of the learned policy from offline data, while also being calibrated, in the sense that the learned Q-values are at a reasonable scale. We refer to this property as calibration, and define it formally as providing a lower bound on the true value function of the learned policy and an upper bound on the value of some other (suboptimal) reference policy, which may simply be the behavior policy. We show that offline RL algorithms that learn such calibrated value functions lead to effective online fine-tuning, enabling us to take the benefits of offline initializations in online fine-tuning. In practice, Cal-QL can be implemented on top of the conservative Q learning (CQL) for offline RL within a one-line code change. Empirically, Cal-QL outperforms state-of-the-art methods on 9/11 fine-tuning benchmark tasks that we study in this paper. Code and video are available at https://nakamotoo.github.io/Cal-QL
研究の動機と目的
- オンラインのサンプル複雑さを削減するために、オンラインファインチューニングに先立つオフライン RL の事前学習を動機づける。
- 保守的なオフライン RL がオンラインのファインチューニングを妨げる理由を特定し、それに対処するための較正を提案する。
- Cal-QL を、較正された値の推定を可能にする、CQL への実用的な1行の変更として開発する。
- 複数のベンチマークにおいて、較正がファインチューニングの性能をより高めることを示す。
提案手法
- オフライン RL の事前学習には、保守的Q学習 (CQL) をベースとする。
- 学習された Q 関数が参照ポリシーの値以上になるよう制約することで、較正を導入する(例:挙動ポリシーの値)。
- 学習済みの Q が較正されていない場合、CQL 正則化項を、V^μ 未満の pushes を max(Q, V^μ) に置換するよう変更する。
- 較正参照として V^μ の挙動ポリシーに基づく推定を用いる。
- ファインチューニング中は、オフラインデータとオンラインデータの混合で訓練し、学習中は Cal-QL の較正を強制する。
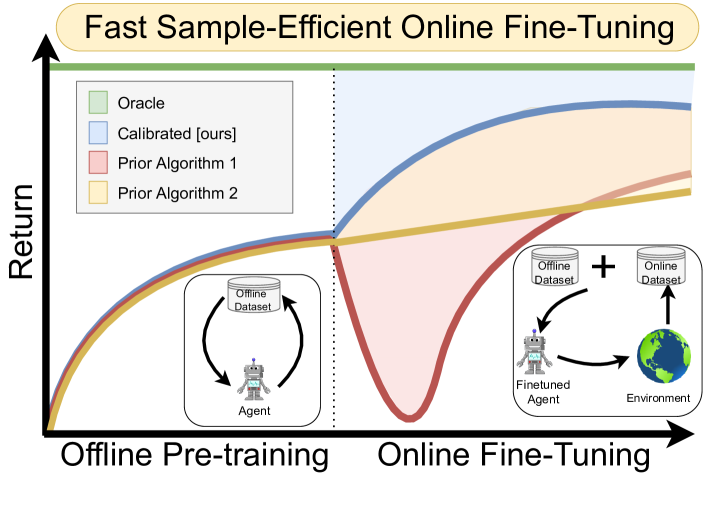
実験結果
リサーチクエスチョン
- RQ1参照ポリシーに対して保守的なオフライン Q 関数を較正することは、オンラインのファインチューニングの効率と最終的な性能を改善しますか?
- RQ2ファインチューニング中のオンライン後悔 (online regret) に対する較正の影響は、標準的なオフライン-to-オンライン手法と比較してどうですか?
- RQ3視覚ベースの入力を含む多様なタスクと観測モダリティにおいて、オンラインのファインチューニング時に Cal-QL はどのように性能を示しますか?
- RQ4Cal-QL は実用的なハイパーパラメータを備えた、既存のオフライン RL パイプラインへのドロップイン変更ですか?
- RQ5オンラインのファインチューニング中の累積後悔に対して、較正はどのような理論的保証を提供しますか?
主な発見
- Cal-QL は、操作・ナビゲーション領域を含むタスク群に対して、最先端のオフライン→オンライン手法と比較してオンラインのファインチューニング性能を向上させます。
- 較正は、いくつかの保守的なオフライン RL 手法で観察される初期の再学習不能 (unlearning) を防ぎ、Q 値が真のリターンと同様にスケーリングされるようにします。
- 報告されたベンチマークのファインチューニングタスク11件のうち9件で、Cal-QL は最良のベースラインと同等かそれ以上の性能を示します。
- データセット状態の期待値に対して較正を強制するには、CQL 目的関数への単純な1行の変更で十分です。
- 理論分析は、保守性と較正のバランスによって、オンラインのファインチューニング中の後悔のより洗練された境界をもたらすことを示します。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。