[論文レビュー] Can ChatGPT Write a Good Boolean Query for Systematic Review Literature Search?
本研究は、システマティックレビューのためのBooleanクエリの作成と磨き上げにおけるChatGPTを評価し、高い精度だが再現率が較低であること、プロンプトと例の質が性能に大きく影響することを示す;多段階のガイド付きプロンプティングが結果を改善し、HQEの例を含むプロンプトが最も効果的である。
Systematic reviews are comprehensive reviews of the literature for a highly focused research question. These reviews are often treated as the highest form of evidence in evidence-based medicine, and are the key strategy to answer research questions in the medical field. To create a high-quality systematic review, complex Boolean queries are often constructed to retrieve studies for the review topic. However, it often takes a long time for systematic review researchers to construct a high quality systematic review Boolean query, and often the resulting queries are far from effective. Poor queries may lead to biased or invalid reviews, because they missed to retrieve key evidence, or to extensive increase in review costs, because they retrieved too many irrelevant studies. Recent advances in Transformer-based generative models have shown great potential to effectively follow instructions from users and generate answers based on the instructions being made. In this paper, we investigate the effectiveness of the latest of such models, ChatGPT, in generating effective Boolean queries for systematic review literature search. Through a number of extensive experiments on standard test collections for the task, we find that ChatGPT is capable of generating queries that lead to high search precision, although trading-off this for recall. Overall, our study demonstrates the potential of ChatGPT in generating effective Boolean queries for systematic review literature search. The ability of ChatGPT to follow complex instructions and generate queries with high precision makes it a valuable tool for researchers conducting systematic reviews, particularly for rapid reviews where time is a constraint and often trading-off higher precision for lower recall is acceptable.
研究の動機と目的
- ChatGPTが高品質なシステマティックレビューBooleanクエリを生成できるかを評価する。
- ChatGPT生成クエリを、最先端の自動クエリ手法と比較する。
- 例やガイディングプロンプトを含むプロンプト設計がクエリの有効性にどのように影響するかを評価する。
- システマティックレビューにおけるクエリ作成でChatGPTを使用する際の留意点と制約を特定する。
提案手法
- クエリ作成のための、単純・詳細・例を含むさまざまな複雑さのプロンプトを設計・評価する。
- ガイドなしとガイド付きプロンプティングの方式を評価する。
- 単一プロンプトおよび複数プロンプトを用いた洗練ワークフローでクエリを生成・洗練する。
- 標準コレクション(CLEF TAR 2017/2018およびSeed Collection)を対象に、利用可能な場合はシード研究を用いてプロンプトをテストする。
- Entrez APIを介して生成されたPubMedクエリを実行し、精度、再現率、およびF値を算出する。
- プロンプトの安定性と堅牢性を評価するため、実行間の変動を分析する。
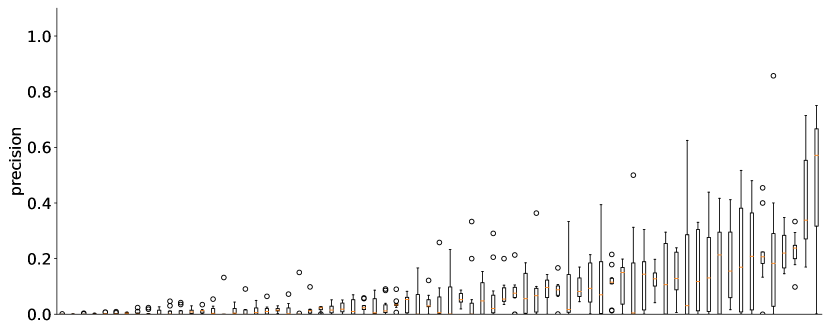
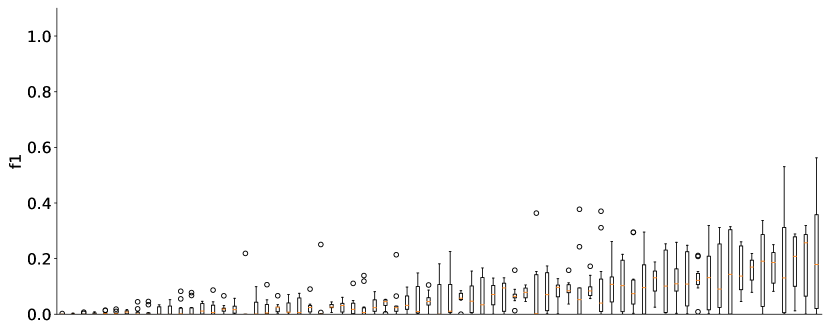
実験結果
リサーチクエスチョン
- RQ1RQ1: ChatGPTは、システマティックレビューBooleanクエリの作成と洗練において、現在の最先端手法とどう比較されるか?
- RQ2RQ2: システマティックレビューBooleanクエリを生成する際に使用されるプロンプトは、ChatGPTが生成するBooleanクエリの有効性にどの程度影響するか?
- RQ3RQ3: 現在の最先端の自動Booleanクエリ生成手法のプロセスを模倣する複数のプロンプトを使用して、ChatGPTによるクエリ作成プロセスをガイドする効果は何か?
- RQ4RQ4: ChatGPTを用いてシステマティックレビュー用Booleanクエリを作成する際の留意点と潜在的な課題は何か?
主な発見
- ChatGPT生成クエリは、基準となる自動手法より一般に高い精度を達成するが、再現率が低いという代償を伴う。
- 実際のシステマティックレビューからの高品質な例(HQE)を含むプロンプトは、HQEのないプロンプトと比較して、F1およびF3スコアと再現率を一貫して改善する。
- ガイド付きプロンプティング(多段階プロンプト)は、シード研究が利用可能な場合、特に作成タスクにおいて、単一プロンプトより優れることがある。
- ChatGPTによるクエリの洗練は精度とF1を高める一方、再現率を低下させる; 洗練後のカバレッジを維持するためには高再現率のシードクエリから始めるのが望ましい。
- 実行とプロンプトによって有効性は変動し、不安定であることを示している。ChatGPTによるMeSH用語の提案は特に弱い。
- プロンプト内にサンプルクエリ(例クエリ)を提供することは、単にタスクを説明するよりも全体的に性能に有利である。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。