[論文レビュー] Can Generalist Foundation Models Outcompete Special-Purpose Tuning? Case Study in Medicine
この論文は、プロンプト設計(Medprompt)がGPT-4の医療専門能力を解き放ち、Med-PaLM 2のような最先端の専門モデルを、9つの医療ベンチマークでモデル呼び出し回数を減らして上回ることを示しています。
Generalist foundation models such as GPT-4 have displayed surprising capabilities in a wide variety of domains and tasks. Yet, there is a prevalent assumption that they cannot match specialist capabilities of fine-tuned models. For example, most explorations to date on medical competency benchmarks have leveraged domain-specific training, as exemplified by efforts on BioGPT and Med-PaLM. We build on a prior study of GPT-4's capabilities on medical challenge benchmarks in the absence of special training. Rather than using simple prompting to highlight the model's out-of-the-box capabilities, we perform a systematic exploration of prompt engineering. We find that prompting innovation can unlock deeper specialist capabilities and show that GPT-4 easily tops prior leading results for medical benchmarks. The prompting methods we explore are general purpose, and make no specific use of domain expertise, removing the need for expert-curated content. Our experimental design carefully controls for overfitting during the prompt engineering process. We introduce Medprompt, based on a composition of several prompting strategies. With Medprompt, GPT-4 achieves state-of-the-art results on all nine of the benchmark datasets in the MultiMedQA suite. The method outperforms leading specialist models such as Med-PaLM 2 by a significant margin with an order of magnitude fewer calls to the model. Steering GPT-4 with Medprompt achieves a 27% reduction in error rate on the MedQA dataset over the best methods to date achieved with specialist models and surpasses a score of 90% for the first time. Beyond medical problems, we show the power of Medprompt to generalize to other domains and provide evidence for the broad applicability of the approach via studies of the strategy on exams in electrical engineering, machine learning, philosophy, accounting, law, nursing, and clinical psychology.
研究の動機と目的
- 一般istファウンデーションモデルが医療において専門家の性能を達成または超えることが、広範な微調整を必要とせずに可能であることを実証する。
- プロンプトエンジニアリング技術を体系的に探求し、ドメイン特化の能力を解き放つ。
- コスト効果が高く、 broadly適用可能な一般的プロンプティングフレームワーク(Medprompt)を開発・評価する。
提案手法
- 埋め込み空間のk-NNを用いた動的な few-shot 例示選択で関連する訓練例を選択。
- GPT-4によって自動生成された自己生成の思考連鎖プロンプトを検証ステップとともに作成。
- 選択肢の位置バイアスを低減し頑強性を向上させるための選択肢シャッフルエンsembling。
- 前処理と推論フェーズの二段階 Medprompt ワークフローへ上記を統合。
- プロンプティングの過剰適合を防ぐためのeyes-offホールドアウトデータセットを用いた頑健な評価設計。
- 各Medpromptコンポーネントの寄与を定量化するアブレーション研究。
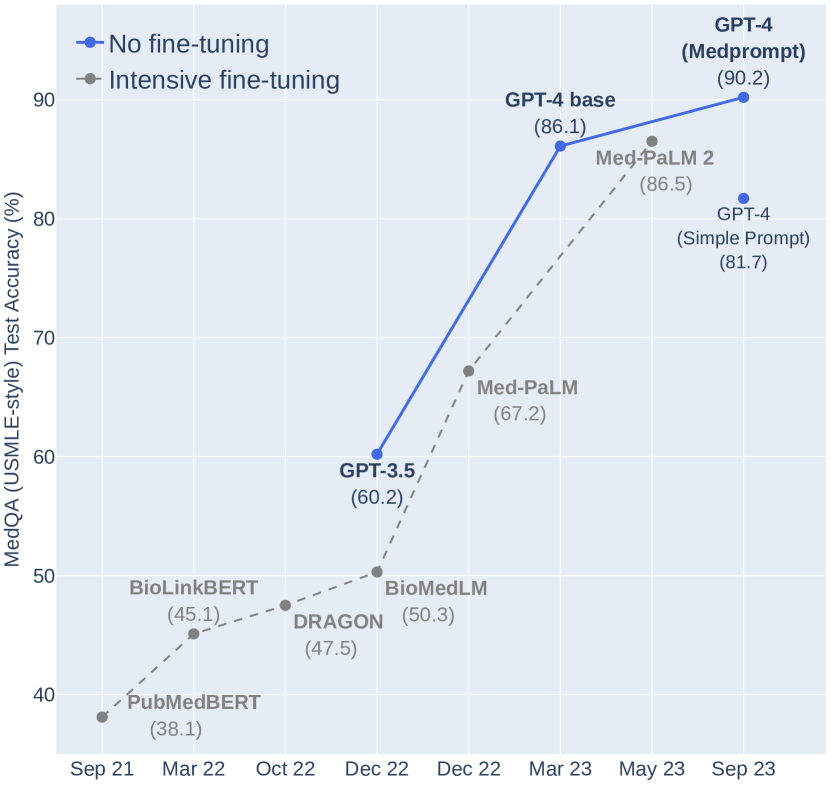
実験結果
リサーチクエスチョン
- RQ1ドメイン特化の微調整を行わなくても、一般istファウンデーションモデルは医療チャレンジベンチマークで最先端の性能を達成できるか。
- RQ2医療QAタスクで性能向上に最も寄与するプロンプティング要素はどれか。
- RQ3Medpromptは医療以外の非医療ドメインや能力試験へどの程度一般化するか。
- RQ4保持データに対する評価時に、プロンプト設計は過適合と一般化にどのような影響を与えるか。
主な発見
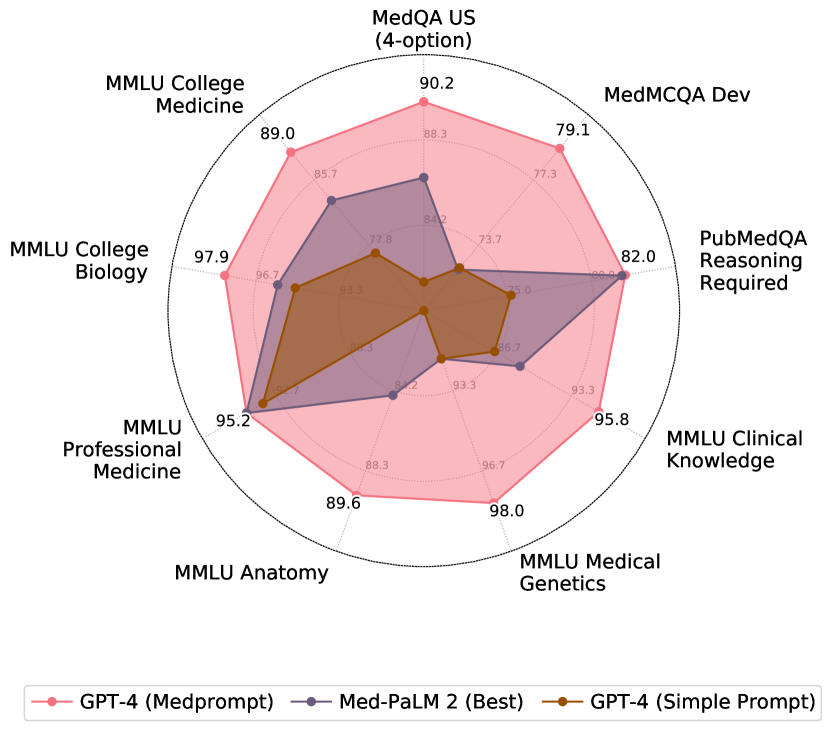
- GPT-4 with Medprompt は、MedQA、MedMCQA、PubMedQA、MMLU medicalサブセットを含む9つのMultiMedQAデータセットで全ベースラインを上回る。
- MedQA(USMLE-式)において、Medpromptは特定設定下で90.6%の正解率を達成し、従来の最良専門手法より誤差を27%低減。
- 自己生成の思考連鎖プロンプトはMedprompt要素の中で最大の単一ゲインをもたらし、次いでfew-shot exemplarsとchoice shuffle ensembling。
- Medpromptは医療の外のドメインの能力試験にも強い一般化を示し、さまざまな領域でゼロショットベースラインに対して平均約7.3ポイントの改善を示す。
- Eyes-offホールドアウトテストは、eyes-onテストと比較して同等または高い性能を示し、ベンチマークプロンプトへの過適合リスクが低いことを示唆。
- アブレーションは、より多くのエ exemplarとアンサンブル手順を追加することでさらなる改善の可能性を示すが、計算コストは高くなる。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。