[論文レビュー] Can Large Language Models Be an Alternative to Human Evaluations?
本論文は、巨大言語モデル(LLMs)を人間評価の代替として活用し、人間の評価で用いられた同じ指示、サンプル、質問を提供して出力を評価し、オープンエンドのストーリ生成と対戦的攻撃における評価を行うことを検討している。
Human evaluation is indispensable and inevitable for assessing the quality of texts generated by machine learning models or written by humans. However, human evaluation is very difficult to reproduce and its quality is notoriously unstable, hindering fair comparisons among different natural language processing (NLP) models and algorithms. Recently, large language models (LLMs) have demonstrated exceptional performance on unseen tasks when only the task instructions are provided. In this paper, we explore if such an ability of the LLMs can be used as an alternative to human evaluation. We present the LLMs with the exact same instructions, samples to be evaluated, and questions used to conduct human evaluation, and then ask the LLMs to generate responses to those questions; we dub this LLM evaluation. We use human evaluation and LLM evaluation to evaluate the texts in two NLP tasks: open-ended story generation and adversarial attacks. We show that the result of LLM evaluation is consistent with the results obtained by expert human evaluation: the texts rated higher by human experts are also rated higher by the LLMs. We also find that the results of LLM evaluation are stable over different formatting of the task instructions and the sampling algorithm used to generate the answer. We are the first to show the potential of using LLMs to assess the quality of texts and discuss the limitations and ethical considerations of LLM evaluation.
研究の動機と目的
- 信頼性の低さと再現性の低さによるNLPにおける人間評価の課題を動機づける。
- 人間評価で用いられた同じ指示、サンプル、質問をLLMsに与えることで、LLM評価を代替手段として提案する。
- オープンエンドのストーリ生成と対敵的テキスト攻撃の分野で、LLM評価と専門家の人間評価を経験的に比較する。
- 指示の変化とサンプリングの超パラメータ下でのLLM評価の安定性を分析する。
- LLMベースの評価を採用する際の制限、倫理、および実践的考慮事項を論じる。
提案手法
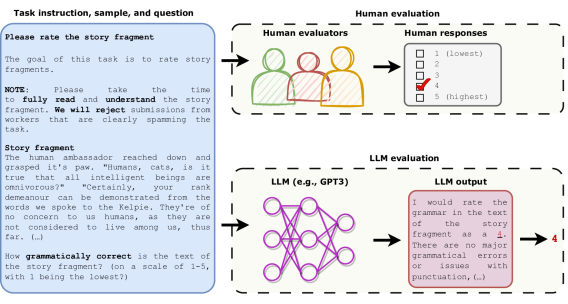
- 人間評価で用いられた同一のタスク指示、サンプル、質問をLLMsに提供し、LLMの出力からリッカート形式の評価を抽出する。
- 核サンプリングを用いて複数のLLMs(T0, text-curie-001, text-davinci-003, ChatGPT)で評価を生成する。
- 200件の人間が書いたストーリーと200件のGPT-2生成ストーリーに対する、3名の英語専門家の評価とLLM評価を比較する。
- 指示とサンプリング温度の変化を伴って実験を繰り返し、頑健性を評価する。
実験結果
リサーチクエスチョン
- RQ1LLMsは専門家の人間評価者と整合する形で文本品質を評価できるか。
- RQ2タスク指示、質問、およびサンプリング設定の変更に対してLLM評価はどれくらい安定しているか。
- RQ3LLM評価は敵対的テキストの品質(流暢さと意味の保持)に関する人間の判断と一致するか。
主な発見
- 強力なモデル(特に text-davinci-003)を用いたLLM評価は専門家の人間評価と整合する評価を生み出し、人間作成のテキストが複数の属性でGPT-2生成より好まれる。
- 異なるタスク指示やサンプリング温度によるLLM評価の変動はわずかで、人間作成とモデル生成テキストの相対的な順位関係を維持する。
- ChatGPTは推論を説明でき、一般に人間作成テキストを高く評価する傾向があるが、いくつかの属性で絶対スコアが異なる場合がある。
- LLMsは流暢さと意味の保持において、敵対的サンプルと健全なサンプルを専門家の判断と一致する形で効果的に順位付けできるが、いくつかのモデル特有の偏り(例:安全ポリシーが評価に影響)も存在する。
- このアプローチは人間評価と比べて再現性の向上とコスト低減を提供する一方、知識バイアスやLLMsの安全制約といった限界を認識している。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。