[論文レビュー] Can Large Language Models Understand Context?
本論文は、生成系LLMの文脈理解ベンチマークを提案し、イン-context 学習とポスト・トレーニング3-bit量子化を評価し、より大きなモデルや量子化されたモデルが小さな密結合モデルよりもタスクにより異なる程度で優れていることを示している。
Understanding context is key to understanding human language, an ability which Large Language Models (LLMs) have been increasingly seen to demonstrate to an impressive extent. However, though the evaluation of LLMs encompasses various domains within the realm of Natural Language Processing, limited attention has been paid to probing their linguistic capability of understanding contextual features. This paper introduces a context understanding benchmark by adapting existing datasets to suit the evaluation of generative models. This benchmark comprises of four distinct tasks and nine datasets, all featuring prompts designed to assess the models' ability to understand context. First, we evaluate the performance of LLMs under the in-context learning pretraining scenario. Experimental results indicate that pre-trained dense models struggle with understanding more nuanced contextual features when compared to state-of-the-art fine-tuned models. Second, as LLM compression holds growing significance in both research and real-world applications, we assess the context understanding of quantized models under in-context-learning settings. We find that 3-bit post-training quantization leads to varying degrees of performance reduction on our benchmark. We conduct an extensive analysis of these scenarios to substantiate our experimental results.
研究の動機と目的
- 生成系LLMsを評価するため、9データセットにまたがる4つのタスクから構成される文脈理解ベンチマークを導入する。
- このベンチマークに対する、サイズやファミリー(OPT, LLaMA, GPT-3.5)を変えたモデルのインコンテキスト学習性能を分析する。
- ポストトレーニング3-bit量子化(GPTQ)が文脈理解タスクに与える影響を評価する。
- 文脈処理におけるモデルの成功・失敗の地点について、言語学的およびタスクレベルの詳細な分析を提供する。)
- method:[
- 文脈焦点の4つのタスク(共参照解決、対話状態追跡、暗黙的談話関係分類、クエリの書き換え)を、インコンテキスト学習のために適合させたプロンプトとともに、9データセットから作成する。
- 密結合型事前学習モデル(OPT 125M–2.7B、LLaMA 7B–65B)およびGPT-3.5-turboを、ゼロショットから十ショットまでの設定で評価する。
- 同じタスクに対して、ポストトレーニング3-bit量子化されたLLaMAモデル(GPTQ)を密結合ベースラインと比較する。
- タスク固有の指標(例:共参照のCoNLL F1、DSTのジョイントゴール精度、PDTB-3の正確度、QRのBLEU/ROUGE)を用いて性能を定量化する。
- 定性的な誤り分析とクエリ書き換えに関するケーススタディを含め、誤りの種類とモデルの挙動を理解する。
提案手法
- 研究質問
実験結果
リサーチクエスチョン
- RQ1LLMがインコンテキスト学習下で、4つの文脈中心タスクにおける文脈的特徴をどの程度理解できるか?
- RQ2モデルサイズとファミリー(OPT、LLaMA、GPT-3.5)が文脈理解の性能にどう影響するか?
- RQ33-bitのポストトレーニング量子化がタスク全般の文脈理解に与える影響はどのようなものか?
- RQ4量子化されたモデルは規模拡大によって小ささを補えるのか、言語学的にはどこが失敗するのか?
- RQ5文脈関連タスクでよく見られる誤りのタイプは何か、密結合モデルと量子化モデルでどう異なるか?
主な発見
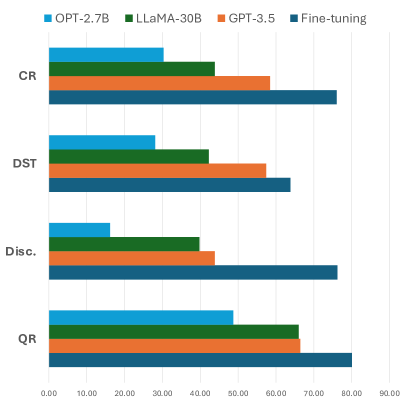
- 事前学習済みLLMを用いたインコンテキスト学習は、ほとんどの文脈タスクでファインチューニング済みモデルに追いつくのが難しい。
- 量子化された3-bit LLaMA(GPTQ)はタスクごとに異なる低下を示し、30Bへスケールすると一部の談話系タスクで利得が見られる。
- 30Bの量子化LLaMAモデルは、いくつかのタスクで7Bの密結合モデルよりも優れることが多く、文脈理解においてはスケールが量子化を上回ることを示している。
- GPT-3.5は対話状態追跡でファインチューニングモデルと同等の水準に達するが、全体としてはFTモデルが多くのタスクで依然優れている。
- クエリ書き換えでは大きなモデルがファインチューニングとの差を埋める傾向を示す一方、小さなモデルは顕著な失敗を示し、生成タスクにおけるICLの限界を浮き彫りにする。
- タスクを通じて、QRデータセットにおける生成指標(BLEU/ROUGE)の一部を改善する一方、他のタスクでは根本的な文脈理解を一般的に低下させる。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。