[論文レビュー] Can LLMs Generate Novel Research Ideas? A Large-Scale Human Study with 100+ NLP Researchers
著者らは大規模な研究を実施し、LLMが生成した研究アイデアと人間の専門家アイデアを比較;AIアイデアは新規性で高評価、実現可能性はほぼ同等。100人超のNLP研究者によるブラインド評価に基づく。
Recent advancements in large language models (LLMs) have sparked optimism about their potential to accelerate scientific discovery, with a growing number of works proposing research agents that autonomously generate and validate new ideas. Despite this, no evaluations have shown that LLM systems can take the very first step of producing novel, expert-level ideas, let alone perform the entire research process. We address this by establishing an experimental design that evaluates research idea generation while controlling for confounders and performs the first head-to-head comparison between expert NLP researchers and an LLM ideation agent. By recruiting over 100 NLP researchers to write novel ideas and blind reviews of both LLM and human ideas, we obtain the first statistically significant conclusion on current LLM capabilities for research ideation: we find LLM-generated ideas are judged as more novel (p < 0.05) than human expert ideas while being judged slightly weaker on feasibility. Studying our agent baselines closely, we identify open problems in building and evaluating research agents, including failures of LLM self-evaluation and their lack of diversity in generation. Finally, we acknowledge that human judgements of novelty can be difficult, even by experts, and propose an end-to-end study design which recruits researchers to execute these ideas into full projects, enabling us to study whether these novelty and feasibility judgements result in meaningful differences in research outcome.
研究の動機と目的
- 最先端のLLMが大規模に新規で専門家レベルの研究アイデアを生成できるかを評価する。
- アイデア創出、報告形式、審査プロセスの混乱因子を統制し、人間の専門家と公正に比較できるようにする。
- 将来のアイデア創出エージェント研究のための標準化評価プロトコルとベンチマークデータを提供する。
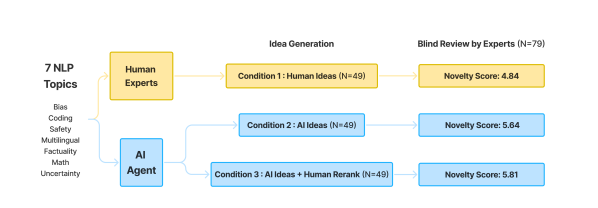
- 3つの条件を比較する:人間作成アイデア、AI生成アイデア、AI生成アイデアを人間の専門家が再ランク付けしたもの。
- LLMアイデーションエージェントの限界を調査し、実世界の成果を検討するエンドツーエンドの追跡研究を提案する。
提案手法
- リトリーバル拡張生成(RAG)を用いてAIアイデアを地づけ、トピックあたり最大120件の retrieved papers を参照し、論文の関連性・実証的内容・新しい研究を刺激する潜在性を評価する。
- 各トピックにつき4000の種アイデアを生成して候補の質を最大化し、重複排除と上位N件の選定を行う。
- 公開会議審査データで訓練されたSwissシステムの対ペア比較ベースのLLMランカーを用いてアイデアを順位付けし、人間が裏打ちするリランクオプション(AI Ideas + Human Rerank)を提供する。
- 固定テンプレートとスタイル正規化モジュールを用いてアイデア報告を標準化し、文章スタイルからの信号手がかりを除去する。
- アイデア作成とブラインド審査の専門家として100人以上のNLP研究者を募集し、条件を横断して比較可能とし、審査者と著者の機関的分離を確保する。
- 4つの指標(新規性、興奮度、実現性、期待効果)と総合点を含むブラインド審査フォームで評価し、理由付きの1–10スケールを用いる。
実験結果
リサーチクエスチョン
- RQ1現在のLLMは新規性において人間の専門家と同等かそれ以上の新規性を持つ専門家レベルの研究アイデアを生成できるか?
- RQ2AI生成アイデアは知覚される新規性・興奮度・実現性・期待される影響において、人間が作成したアイデアと異なるか?
- RQ3アイデア品質のLLMベースランキングはどの程度信頼できるか、自己評価と生成の多様性の限界は何か?
- RQ4AI生成アイデアの品質と新規性に対する人間のリランクが与える影響は何か?
- RQ5アイデア創出エージェントのエンドツーエンド実行研究における人間の新規性判断の含意は何か?
主な発見
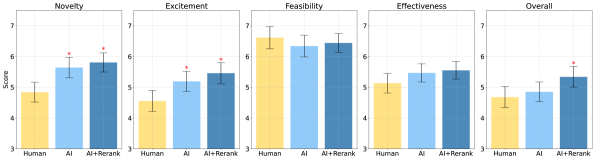
- AI生成アイデアは複数のテストで人間の専門家アイデアより新規性が高く評価される(p<0.05)。
- AI生成アイデアは人間のアイデアと比較して実現性がやや低く評価されるが、総合スコアは一貫して低くはない。
- AIアイデアと人間のリランクを組み合わせると、人間のアイデアよりも新規性と総合スコアがさらに高くなり、人間介在のランキングの価値を示唆する。
- レビュアー分析は、新規性と興奮度が総合スコアを実現性よりも左右することを示し、新規性判断の主観性を強調する。
- エージェント経由のアイデアのLMMベースランキングには、規模拡大時の多様性欠如や評価者としての自己評価の不完全さなどの限界がある。
- 本研究は将来のエンドツーエンドのアイデア創出研究を支援する標準化プロトコルとエージェント実装および審査の公開を提供する。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。