[論文レビュー] Can LLMs Produce Faithful Explanations For Fact-checking? Towards Faithful Explainable Fact-Checking via Multi-Agent Debate
本論文は、ゼロショットのLLMがしばしば不正確な事実検証の説明を生み出すことを示し、複数のLLMエージェントを用いて逐次討論・精練して証拠への忠実性を向上させる Multi-Agent Debate Refinement (MADR) フレームワークを提案します。
Fact-checking research has extensively explored verification but less so the generation of natural-language explanations, crucial for user trust. While Large Language Models (LLMs) excel in text generation, their capability for producing faithful explanations in fact-checking remains underexamined. Our study investigates LLMs' ability to generate such explanations, finding that zero-shot prompts often result in unfaithfulness. To address these challenges, we propose the Multi-Agent Debate Refinement (MADR) framework, leveraging multiple LLMs as agents with diverse roles in an iterative refining process aimed at enhancing faithfulness in generated explanations. MADR ensures that the final explanation undergoes rigorous validation, significantly reducing the likelihood of unfaithful elements and aligning closely with the provided evidence. Experimental results demonstrate that MADR significantly improves the faithfulness of LLM-generated explanations to the evidence, advancing the credibility and trustworthiness of these explanations.
研究の動機と目的
- ゼロショット設定において、LLMs が事実検証のための忠実な説明を生成できるかを評価する。
- 新しい誤り類型を用いて、LLMの説明における一般的な忠実性のエラーを特徴づける。
- 忠実性を向上させるための Multi-Agent Debate Refinement (MADR) フレームワークを提案・評価する。
- 自動評価と人間評価を用いて、MADRをベースラインのプロンプティング戦略と比較する。
提案手法
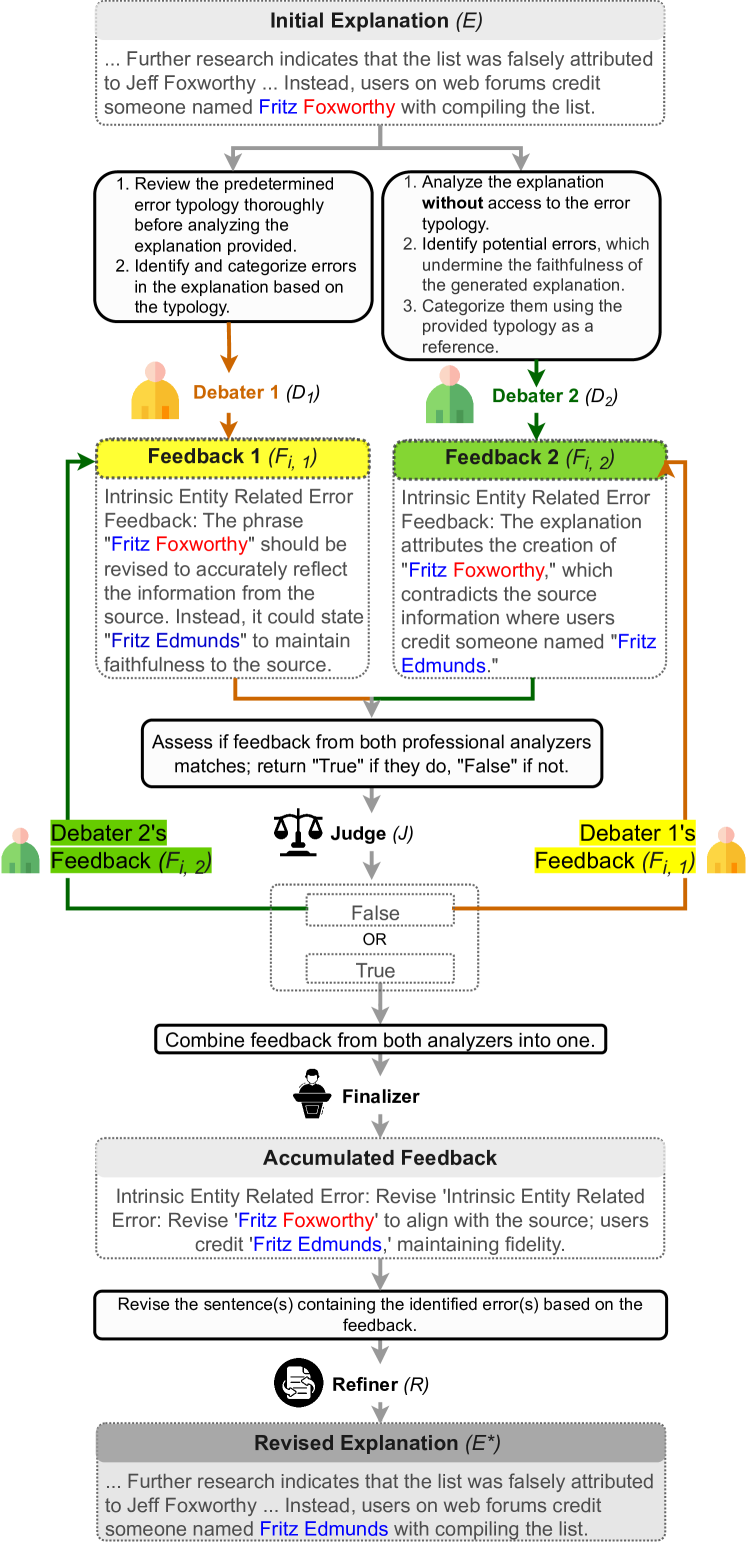
- 事実検証の説明における忠実性の新しい誤り類型を開発する( 内在的/外在的なエンティティ/イベント/名詞句の誤り、推論の一貫性、過一般化、関連性のない証拠)。
- MADR を提案する:複数のLLMエージェント(2名のDebater、1名のJudge、1名のRefiner)が反復的にフィードバックを生成して説明を精練する。
- Debater は誤りを類型と非類型の手掛かりに基づいて特定する。Judge はフィードバックの合意を裁定し、Refiner が最終的な説明を作成する。
- 合意または反復制限によって終了する、忠実な説明を生成する有限のマルチエージェント討論ループを適用する。
- PolitiHop のマルチホップ事実検証データと GPT-4 Turbo を用いた G-Eval で、複数の粒度プロトコル(文レベルおよび文書レベル)に跨って評価する。
- 自動評価と人間評価を用いて、ゼロショット、チェーン・オブ・思考、Self-Refine のベースラインと比較する。
実験結果
リサーチクエスチョン
- RQ1ゼロショット prompting の下で、LLMs は事実検証の忠実な説明を生成できるか?
- RQ2LLM が生成する説明に一般的に現れる不忠実性エラーの類型は何か?
- RQ3複数エージェントの討論精練プロセスは生成された説明の忠実性を改善できるか?
- RQ4事実検証におけるLLMの説明の忠実性は自動評価と人間評価のどちらで評価すべきか?
主な発見
| 方法 | 文レベル(類型なし) | 文レベル(類型あり) | 文書レベル(類型なし) | 文書レベル(類型あり) |
|---|---|---|---|---|
| Zero-shot | 4.87 | 4.84 | 4.70 | 4.92 |
| CoT | 4.86 | 4.91 | 4.76 | 4.96 |
| Self-Refine | 4.70 | 4.86 | 4.89 | 4.81 |
| MADR (ours) | 4.82 | 4.99 | 4.88 | 4.97 |
- ゼロショットの説明は頻繁に不忠実で、いくつかのプロンプトでは詳細の最大80%が幻視的(ハルシネーション)となる。
- MADR は、プロトコルの変種を跨る自動評価においてベースラインより忠実性を著しく改善する。
- 人間の評価は、MADR がサンプルケースでより忠実な説明をもたらすことを示し、ディベーターが単一エージェントでは見逃される誤りを捉える。
- 誤り類型を取り入れたプロンプトを用いた自動評価プロトコルは、誤り類型を用いないプロトコルより人間の判断とより高い相関を示す。
- 相関分析は、誤り類型付きの文レベル評価が人間の忠実性判断とより近い一致を示す( Kendall の Tau が高い)。
- 自己精練だけでは、エラーを修正し忠実な推論を得るにはMADRより効果が低い。

より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。