[論文レビュー] Can multiple-choice questions really be useful in detecting the abilities of LLMs?
本論文はMCQ効率をLLM評価に適用することを分析し、順序依存性と長文生成との不整合を明らかにし、QA形式全体での一貫性と信頼度を測定する方法を提案する。
Multiple-choice questions (MCQs) are widely used in the evaluation of large language models (LLMs) due to their simplicity and efficiency. However, there are concerns about whether MCQs can truly measure LLM's capabilities, particularly in knowledge-intensive scenarios where long-form generation (LFG) answers are required. The misalignment between the task and the evaluation method demands a thoughtful analysis of MCQ's efficacy, which we undertake in this paper by evaluating nine LLMs on four question-answering (QA) datasets in two languages: Chinese and English. We identify a significant issue: LLMs exhibit an order sensitivity in bilingual MCQs, favoring answers located at specific positions, i.e., the first position. We further quantify the gap between MCQs and long-form generation questions (LFGQs) by comparing their direct outputs, token logits, and embeddings. Our results reveal a relatively low correlation between answers from MCQs and LFGQs for identical questions. Additionally, we propose two methods to quantify the consistency and confidence of LLMs' output, which can be generalized to other QA evaluation benchmarks. Notably, our analysis challenges the idea that the higher the consistency, the greater the accuracy. We also find MCQs to be less reliable than LFGQs in terms of expected calibration error. Finally, the misalignment between MCQs and LFGQs is not only reflected in the evaluation performance but also in the embedding space. Our code and models can be accessed at https://github.com/Meetyou-AI-Lab/Can-MC-Evaluate-LLMs.
研究の動機と目的
- MCQが中国語と英語のデータセットを含む複数言語でLLMの能力を正確に測定しているかを評価する。
- MCQの選択肢の順序がLLM出力にどのように偏りを与えるかを検討する。
- 直接出力、トークンロジット、埋め込み表現においてMCQと長文生成(LFGQ)形式を比較する。
- 出力の一貫性とモデルの信頼度を定量化する方法を提案する。
- QAベンチマークにおいてMCQとLFGQのどちらを使用すべきかの指針を提供する。
提案手法
- CARE-MI(中国語)、M3KE(中国語)、ARC(英語)、MATH(英語)の4つのQAデータセットで9つのLLMを評価する。
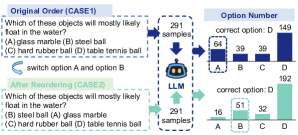
- MCQの選択肢を並べ替えて順序依存性を検査し、分布の変化を検出するためにカイ二乗検定を適用する。
- 直接出力、トークンロジット、隠れ埋め込み空間においてMCQとLFGQ形式を比較する(統合信頼度やECEなどの分析を含む)。
- 形式間の相関と一貫性と正確性の間の相関を分析する。
- 事前プロンプトと事後プロンプトを用いて簡潔な回答を引き出し、自動的な信頼度計算を可能にする。
実験結果
リサーチクエスチョン
- RQ1MCQの選択肢の配置が、二言語データセットにおけるLLMの応答にどのように影響するか?
- RQ2直接出力、トークンロジット、埋め込み空間を横断してMCQとLFGQを比較する際、どのような方法論が適切か?
- RQ3MCQとLFGQの不整合の程度はどの程度か、また形式間でキャリブレーションと一貫性はどのように異なるか?
主な発見
- LLMsは二言語MCQで順序依存性を示し、最初の選択肢を含む回答を好む。
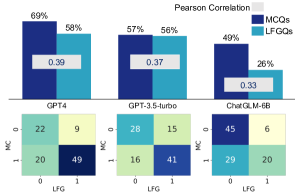
- 同一問題に対するMCQとLFGQの回答は、形式間で相関が低い。
- より一貫した回答が必ずしも高い正確性に結びつくわけではない。
- MCQはLFGQおよびTFQよりキャリブレーションが劣り(ECEが高い)、埋め込み空間は複数の層で形式間の不整合を示す。
- MCQとLFGQの埋め込みは一部の層で区別可能だが、いくつかのモデルでは後半の層で収束する。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。