[論文レビュー] CAS-ViT: Convolutional Additive Self-attention Vision Transformers for Efficient Mobile Applications
CAS-ViT は従来の自己注意を置換する Convolutional Additive Token Mixer (CATM) を提案し、モバイルおよびエッジデバイスに適した線形計算量で競争力のある精度を実現します。分類、検出、セグメンテーションの評価を、GPU、ONNX、iPhone 展開で行います。
Vision Transformers (ViTs) mark a revolutionary advance in neural networks with their token mixer's powerful global context capability. However, the pairwise token affinity and complex matrix operations limit its deployment on resource-constrained scenarios and real-time applications, such as mobile devices, although considerable efforts have been made in previous works. In this paper, we introduce CAS-ViT: Convolutional Additive Self-attention Vision Transformers, to achieve a balance between efficiency and performance in mobile applications. Firstly, we argue that the capability of token mixers to obtain global contextual information hinges on multiple information interactions, such as spatial and channel domains. Subsequently, we propose Convolutional Additive Token Mixer (CATM) employing underlying spatial and channel attention as novel interaction forms. This module eliminates troublesome complex operations such as matrix multiplication and Softmax. We introduce Convolutional Additive Self-attention(CAS) block hybrid architecture and utilize CATM for each block. And further, we build a family of lightweight networks, which can be easily extended to various downstream tasks. Finally, we evaluate CAS-ViT across a variety of vision tasks, including image classification, object detection, instance segmentation, and semantic segmentation. Our M and T model achieves 83.0\%/84.1\% top-1 with only 12M/21M parameters on ImageNet-1K. Meanwhile, throughput evaluations on GPUs, ONNX, and iPhones also demonstrate superior results compared to other state-of-the-art backbones. Extensive experiments demonstrate that our approach achieves a better balance of performance, efficient inference and easy-to-deploy. Our code and model are available at: \url{https://github.com/Tianfang-Zhang/CAS-ViT}
研究の動機と目的
- リソース制約/モバイル環境での ViT の効率的なトークンミキサーを動機づける。
- 畳み込み演算を介して線形計算量のアテンションを実現する Convolutional Additive Token Mixer (CATM) の提案。
- 分類、検出、インスタンス分割、セマンティック分割タスクにおいて CAS-ViT の競争力のある精度とデプロイ効率を示す。
- GPU、ONNX、iPhone 展開でのスループットを評価することで実用性を示す。
提案手法
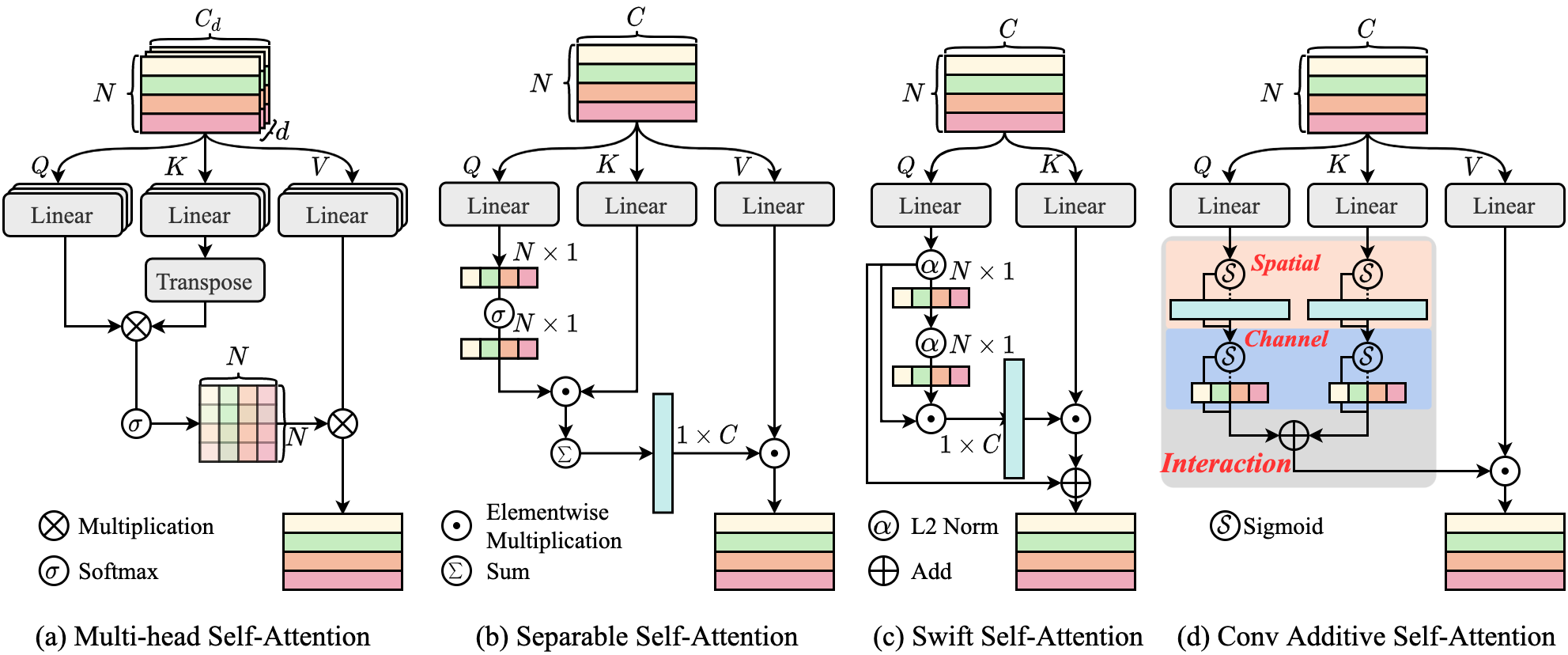
- Sim(Q,K) = Phi(Q) + Phi(K) という新規の加法的類似度関数を定義し、Phi が空間的およびチャネル間の相互作用を組み合わせる。
- Depthwise conv + Sigmoid 空間アテンションと簡略化されたチャネルアテンションを用いて Convolutional Additive Token Mixer (CATM) を実装する。
- CAS-ViT を four stages を持つ軽量 ViT として、層をまたぐ CATM ベースのブロックに加え、統合サブネットと残差を持つ MLP を組み込んで構築する。
- 入力サイズに対して全体で線形計算量を達成するための計算複雑性を分析する(Omega(CATM) ~ (47+10b)HWC)。
- ImageNet-1K でのゼロからのトレーニングを提供し、その後下流タスクと CoreML および ONNX を介したモバイル展開を行う。
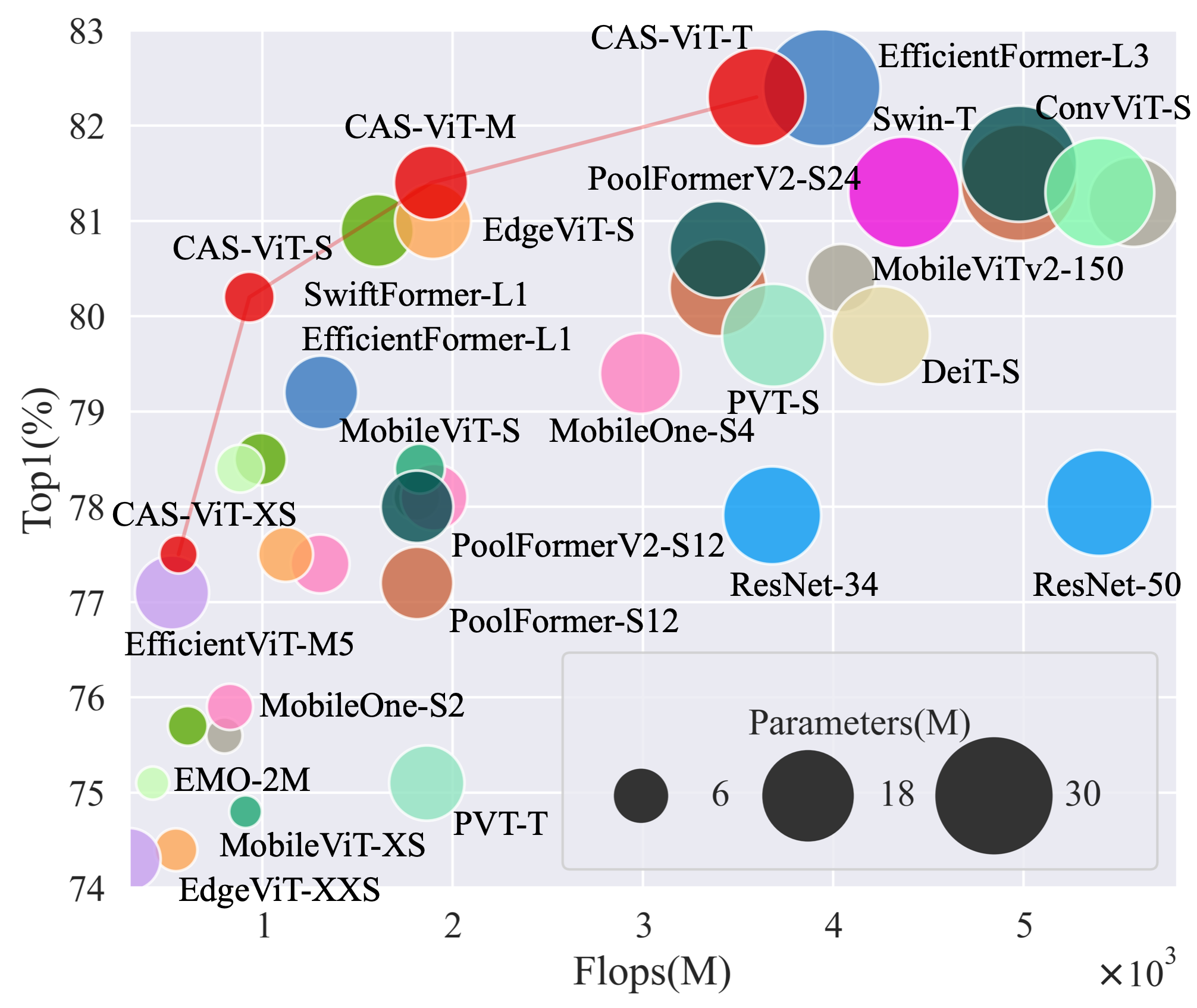
実験結果
リサーチクエスチョン
- RQ1畳み込みベースの加法的アテンション機構が、モバイル展開において線形時間計算量で競争力のある ViT パフォーマンスを達成できるか?
- RQ2加法的類似度における空間的およびチャネル相互作用の統合が、視覚タスク全体の精度と効率にどう影響するか?
- RQ3GPU、ONNX、および iPhone ハードウェア上での CAS-ViT のスループットと精度のトレードオフは?
- RQ4検出、インスタンス分割、セマンティック分割における CAS-ViT の性能は、最先端バックボーンと比較してどうか?
主な発見
- CAS-ViT のバリアントは ImageNet-1K で、比較的少ないパラメータと FLOPs で競争力の Top-1 精度を達成する。
- CATM は線形計算量を維持しつつ、空間的およびチャネルの相互作用を取り入れつつ Softmax ベースの重い計算を回避する。
- 物体検出/インスタンス分割では、CAS-ViT バックボーン(例:CAS-ViT-S/M)は、いくつかのベースラインよりも同程度または低い FLOPs でより良い AP 指標を示す。
- ADE20K のセマンティック分割では CAS-ViT-M が比較的低い FLOPs で 43.6% の mIoU を達成。
- GPU、ONNX、Apple Neural Engine 上のスループット分析は、実用的なモバイル展開の可能性を示す。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。