[論文レビュー] Chain of History: Learning and Forecasting with LLMs for Temporal Knowledge Graph Completion
本論文は、構造認識ヒストリーと逆論理プロンプトを活用して時系列知識グラフの補完を行うPEFT微調整済みLLMフレームワークを提示し、埋め込みベースおよび他のLLMアプローチと比べてICEWSおよびYAGOデータセットで競争力のある結果を達成する。
Temporal Knowledge Graph Completion (TKGC) is a complex task involving the prediction of missing event links at future timestamps by leveraging established temporal structural knowledge. This paper aims to provide a comprehensive perspective on harnessing the advantages of Large Language Models (LLMs) for reasoning in temporal knowledge graphs, presenting an easily transferable pipeline. In terms of graph modality, we underscore the LLMs' prowess in discerning the structural information of pivotal nodes within the historical chain. As for the generation mode of the LLMs utilized for inference, we conduct an exhaustive exploration into the variances induced by a range of inherent factors in LLMs, with particular attention to the challenges in comprehending reverse logic. We adopt a parameter-efficient fine-tuning strategy to harmonize the LLMs with the task requirements, facilitating the learning of the key knowledge highlighted earlier. Comprehensive experiments are undertaken on several widely recognized datasets, revealing that our framework exceeds or parallels existing methods across numerous popular metrics. Additionally, we execute a substantial range of ablation experiments and draw comparisons with several advanced commercial LLMs, to investigate the crucial factors influencing LLMs' performance in structured temporal knowledge inference tasks.
研究の動機と目的
- 大規模言語モデル(LLMs)を用いて時系列知識グラフ(TKGs)に対する効果的な推論を動機付け、可能にする。
- TKGCのために歴史的なグラフ情報を組み込む、移植性のある構造認識フレームワークを開発する。
- LLMベースの構造化推論における反転呪いを、微調整時の逆論理プロンプトで緩和する。
- TKGCタスクにLLMsを適合させるためのパラメータ効率的な微調整(PEFT)を実証する。
- 既存のTKGC手法および商用LLMsとの包括的なアブレーション研究と比較を提供する。
提案手法
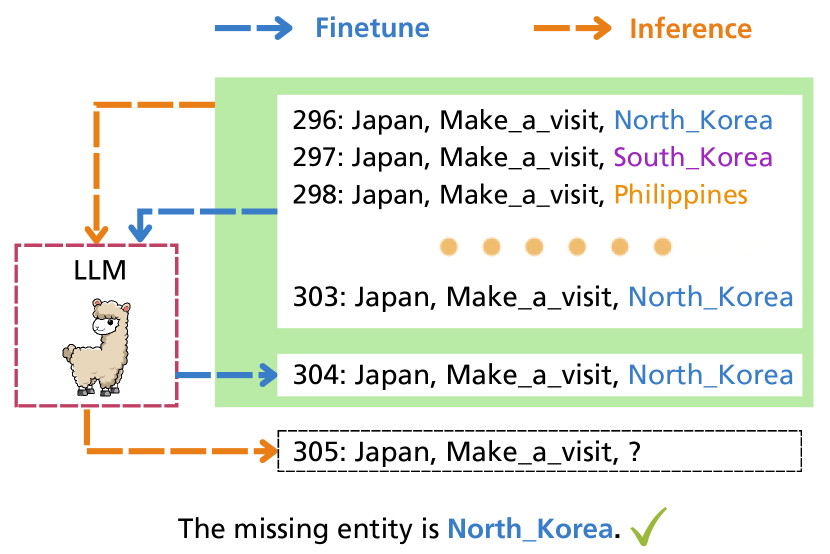
- LLM推論を情報するために、スキーマ照合履歴、エンティティ強化履歴、関係強化履歴を組み合わせた構造補強履歴モデリングにより、LLMの推論を補助する。
- 微調整時に3つのプロンプト戦略(通常型プロンプト、テキスト意識型プロンプト、位置意識型プロンプト)を導入し、構造化推論における反転問題を緩和する。
- ベースモデルを固定したまま、LoRAベースのPEFTを用いて少数のパラメータを更新することで指示調整を行う。
- ビームサーチデコードによって候補回答列を生成し、最大確率の系列を選択する形でLLMsを用いた予測。
- 文脈提供のために歴史的連鎖(L)を使用し、データセットごとの最適な履歴長に留意する。
- ICEWSおよびYAGOデータセットで、埋め込みベースのTKGCモデルおよびさまざまなオープンソース/商用LLMsと比較評価する。
実験結果
リサーチクエスチョン
- RQ1構造認識履歴と逆論理プロンプトを備えた場合、LLMが推論エージェントとして外挿的TKGCに効果的に機能するか。
- RQ2PEFT(LoRA)微調整は、全パラメータ微調整と比べてTKGCタスクにおけるLLMの性能にどのような影響を与えるか。
- RQ3履歴拡張、逆データ、プロンプト戦略が前向きおよび後向き(逆)時系列推論に与える影響は何か。
- RQ4モデルサイズとデータセットの特徴が、商用LLMsとの比較を含め、LLMベースのTKGC性能にどのように影響するか。
主な発見
- 提案されたフレームワークは、いくつかのTKGCベンチマークで最先端手法と比較して高い競争力、または優れた性能を達成する。
- 構造ベースの履歴拡張(スキーマ履歴、エンティティ履歴、関係履歴)は、TKGCにおける前向きおよび後向き推論の両方を改善する。
- 微調整時に逆論理を導入すると反転呪いを緩和し、一般に前向き推論を改善または維持する。
- LoRAベースの指示調整は相対的に少数のパラメータ更新で強い結果をもたらし、より大きなモデルサイズが必ずしもTKGC性能を向上させるとは限らない。
- 商用LLMsは性能がまちまちで、RLHFを備えた一部のチャットモデルは特定データセットでベースラインモデルに近づくか上回ることがある一方、他のデータセットでは専門的TKGCモデルを下回る。
- データセット全体で、履歴長とデータ拡張戦略が性能に影響を与え、履歴が長すぎるといくつかのデータセットで収益が減少するか有害となる。

より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。