[論文レビュー] Chain-of-Symbol Prompting Elicits Planning in Large Langauge Models
本論文は Chain-of-Symbol (CoS) prompting を提案し、空間関係を凝縮した象徴表現を用いて LLM の計画を促進する。CoT を3つの空間タスクと空間QAベンチマークで上回り、入力トークン数を削減する。
In this paper, we take the initiative to investigate the performance of LLMs on complex planning tasks that require LLMs to understand a virtual spatial environment simulated via natural language and act correspondingly in text. We propose a benchmark named Natural Language Planning and Action (Natala) composed of a set of novel tasks: Brick World, NLVR-based Manipulations, and Natural Language Navigation. We found that current popular LLMs such as ChatGPT still lack abilities in complex planning. This arises a question -- do the LLMs have a good understanding of the environments described in natural language, or maybe other alternatives such as symbolic representations are neater and hence better to be understood by LLMs? To this end, we propose a novel method called CoS (Chain-of-Symbol Prompting) that represents the complex environments with condensed symbolic spatial representations during the chained intermediate thinking steps. CoS is easy to use and does not need additional training on LLMs. Extensive experiments indicate that CoS clearly surpasses the performance of the Chain-of-Thought (CoT) Prompting in all three planning tasks with even fewer tokens used in the inputs compared with CoT on ChatGPT and InstructGPT. The performance gain is strong, by up to 60.8% accuracy (from 31.8% to 92.6%) on Brick World for ChatGPT. CoS also reduces the number of tokens in the prompt obviously, by up to 65.8% of the tokens (from 407 to 139) for the intermediate steps from demonstrations on Brick World. Code and data available at: https://github.com/hanxuhu/chain-of-symbol-planning
研究の動機と目的
- 自然言語で記述された複雑な空間理解と計画タスクに対して LLM を評価する。
- 象徴的表現が空間タスクの中間ステップ(CoT)より優れているかを検証する。
- トレーニングを必要としない CoS prompting を提案・検証し、プロンプト長を削減する。
- モデル・言語・象徴選択に対する CoS の頑健性を分析する。
提案手法
- 自然言語の中間ステップを凝縮された空間関係の象徴に置換する Chain-of-Symbol (CoS) prompting を提案する。
- CoT デモを自動生成し、誤りを修正し、空間関係を象徴に置換しつつ非本質的な文章を削除して CoS に変換する。
- CoS デモを用いた few-shot prompting を用いて、3つの空間計画タスクで LLM を誘導する。
- Zero-shot CoT、few-shot CoT、few-shot CoS のベースラインを用いて、ChatGPT (gpt-3.5-turbo) および Text-Davinci-003 との適合性と性能を評価する。
- 計画タスクの正解率、適合率、再現率(いくつかのタスクでは LCS ベースの類似度)を測定し、空間 QA の正解率を評価する。
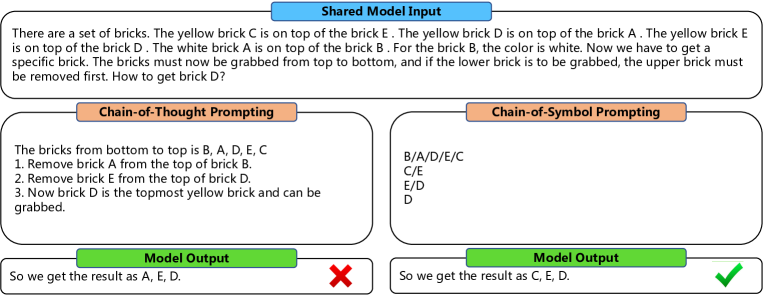
実験結果
リサーチクエスチョン
- RQ1空間関係の象徴表現は、自然言語の CoT と比較してテキスト記述環境での LLM 計画を改善するか。
- RQ2CoS プロンプトは異なるタスク、言語、モデルタイプにまたがって一般化するか。
- RQ3CoS は CoT と比較してトークン効率と推論コストをどう改善するか。
- RQ4象徴選択やタスクの複雑さに対して CoS の利点は頑健か。
主な発見
- CoS は Brick World、NLVR ベース Manipulation、Natural Language Navigation の各タスクで CoT を一様に上回る。
- Brick World 1D Shuffle Label の 1D シナリオで、CoS は正解率 92.6% を達成し、ベースライン CoT の 31.8% から 60.8 ポイントの改善を達成。
- CoS は中間ステップのトークンを大幅に削減(Brick World 1D では 407 トークン → 139 トークン 等)。
- CoS は言語を超えて頑健性を保ち、異なる象徴でも、コンマを効果的な選択として示した上で中国語での性能向上が見られた。
- SPARTUN では、GPT-3.5-Turbo および GPT-4 に対して CoS が CoT より高い正解率と少ない中間トークンを示した。
- CoS は CoT と比較していくつかの試行で出力のばらつき(標準偏差)が小さいことを示した。

より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。