[論文レビュー] Chain-of-Thought Prompting of Large Language Models for Discovering and Fixing Software Vulnerabilities
この論文は Vulnerability-Semantics-guided Prompting (VSP) を導入し、チェーンオブソート prompting を用いて LLM がソフトウェアの脆弱性を特定・発見・修正できるようにし、合成データと CVE データセットでベースラインよりも大幅に高い F1 スコアを達成する。
Security vulnerabilities are increasingly prevalent in modern software and they are widely consequential to our society. Various approaches to defending against these vulnerabilities have been proposed, among which those leveraging deep learning (DL) avoid major barriers with other techniques hence attracting more attention in recent years. However, DL-based approaches face critical challenges including the lack of sizable and quality-labeled task-specific datasets and their inability to generalize well to unseen, real-world scenarios. Lately, large language models (LLMs) have demonstrated impressive potential in various domains by overcoming those challenges, especially through chain-of-thought (CoT) prompting. In this paper, we explore how to leverage LLMs and CoT to address three key software vulnerability analysis tasks: identifying a given type of vulnerabilities, discovering vulnerabilities of any type, and patching detected vulnerabilities. We instantiate the general CoT methodology in the context of these tasks through VSP , our unified, vulnerability-semantics-guided prompting approach, and conduct extensive experiments assessing VSP versus five baselines for the three tasks against three LLMs and two datasets. Results show substantial superiority of our CoT-inspired prompting (553.3%, 36.5%, and 30.8% higher F1 accuracy for vulnerability identification, discovery, and patching, respectively, on CVE datasets) over the baselines. Through in-depth case studies analyzing VSP failures, we also reveal current gaps in LLM/CoT for challenging vulnerability cases, while proposing and validating respective improvements.
研究の動機と目的
- LLMs と CoT prompting を活用して、限られたタスク固有データで脆弱性分析への動機づけを行う。
- VSP を提案し、脆弱性セマンティクスをチェーンオブソート推論へマッピングして焦点化された分析を実現。
- 3つのタスク—識別、発見、修正—を、複数の LLM とデータセットを跨いで評価する。
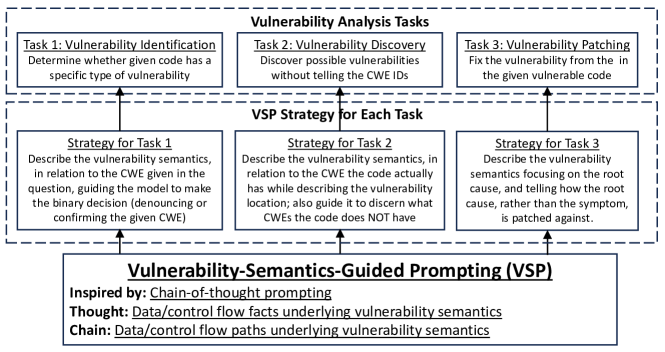
提案手法
- 脆弱性の文言とその文脈データ/制御フロー関係を捉える Vulnerability Semantics を導入する。
- 脆弱性セマンティクス (VSP) を統一戦略として周辺の CoT ベースの Few-shot prompting を実装する。
- 識別(二値)、発見(多クラス)、修正(テキスト⇄テキスト)に対するタスク固有の prompting 方式を VSP 内に提供する。
- C/C++ の5つの CWE を軸にした exemplars を用い、SARD(synthetic)と CVE(real-world)データセットで GPT-3.5、Llama2、Falcon を試験する。
- VSP を Standard Prompting、Standard Few-shot、Naive CoT、Zero-Shot VSP、および Other-Type VSP ベースラインと比較する。

実験結果
リサーチクエスチョン
- RQ1LLMs は脆弱性の識別、発見、修正を脆弱性セマンティクスに導かれて効果的に行えるか。
- RQ2脆弱性セマンティクスによる CoT prompting は、標準 prompting やナイーブ CoT に比べて、様々な LLM やデータセットで性能を向上させるか。
- RQ3これらの prompts は異なる脆弱性タイプ(CWEs)や現実世界の CVE データに対してどの程度移行可能か。
主な発見
| Model | Dataset | Strategy | F1 |
|---|---|---|---|
| GPT-3.5 | SARD | VSP Prompting | 65.29% |
| Llama2 | SARD | VSP Prompting | 60.18% |
| Falcon | SARD | VSP Prompting | 51.25% |
| GPT-3.5 | CVE | VSP Prompting | 58.48% |
| Llama2 | CVE | VSP Prompting | 44.80% |
| Falcon | CVE | VSP Prompting | 36.36% |
- VSP prompting は、モデルとデータセットを通じて脆弱性識別の最良の F1 を達成する(例: GPT-3.5 で SARD の場合 65.29%)。
- CVE データ上では、識別で VSP が 58.48% F1(GPT-3.5)を達成し、標準 prompting を大幅に上回る。
- 脆弱性発見では、VSP は GPT-3.5 で CVE 上の macro-averaged F1 を 36.34%、SARD 上を 55.83%(macro)に向上。
- 脆弱性修正では、VSP は 合成データで 97.65% F1、CVE で 20.00% を GPT-3.5 で達成し、ベースラインを上回る。
- VSP により、未知の日次 CVE 脆弱性を 22 件検出可能(精度 40.00%)だが、ベースラインは 9 件(精度 16.36%)。
- 失敗分析では、文脈不足、CWE の忘却、制御/データフロー分析の不完結が指摘され、ターゲットを絞った改善が提案される。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。