QUICK REVIEW
[論文レビュー] Challenges and Applications of Large Language Models
Jean Kaddour, Joshua Harris|arXiv (Cornell University)|Jul 19, 2023
Topic Modeling被引用数 172
ひとこと要約
大規模言語モデルを横断する多様な分野への適用における未解決の問題(設計・挙動・科学)と現在の成果を系統的に概説し、制約とトレードオフを強調する調査
ABSTRACT
Large Language Models (LLMs) went from non-existent to ubiquitous in the machine learning discourse within a few years. Due to the fast pace of the field, it is difficult to identify the remaining challenges and already fruitful application areas. In this paper, we aim to establish a systematic set of open problems and application successes so that ML researchers can comprehend the field's current state more quickly and become productive.
研究の動機と目的
- LLMの設計、挙動、科学的進展における未解決の課題を特定する。
- 成功した適用分野を整理し、課題がそれらをどのように制約するかを整理する。
- LLMの研究と導入の進展を加速させるための機械学習研究者への指針を提供する。
提案手法
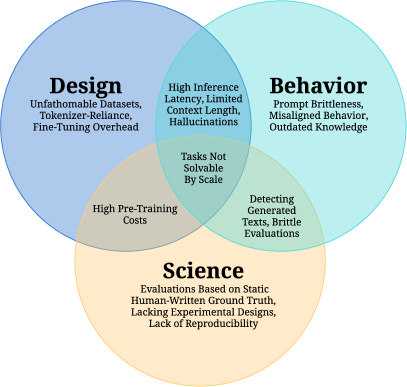
- 課題を design、behavior、science の三つの大きなカテゴリに分類する。
- 各課題に対処する文献と報告された手法を検討する。
- 今後の研究を導くために、適用分野と関連する制約を要約する。
実験結果
リサーチクエスチョン
- RQ1設計、挙動、科学の領域で、巨大言語モデルに関して未解決の課題は何か?
- RQ2LLMは現在どこで適用されており、これらの課題がこれらの適用にどのような制約を課しているか?
- RQ3データ、トークナイズ、訓練、ファインチューニング、評価の実践は、LLMの性能と信頼性にどのように影響するか?
主な発見
- 事前訓練用データセットは膨大でほとんど理解不能であり、ほぼ重複データやベンチマークの汚染がモデルの挙動と評価に影響を与える。
- トークナイザーとトークナイザー–モデルの結合は、言語的および資源の不平等を生み出し、特に多言語および資源の少ない言語に影響が出る。
- 事前訓練コストは非常に高く、データ効率を改善するためのスケーリング則、計算最適化戦略、そして代替的な訓練目的に対する関心を高めている。
- LLMのファインチューニングは、メモリとストレージ要件のために実践的な障壁に直面しており、アダプター、プレフィックス・チューニング、プロンプト・チューニングなど、パラメータ効率の良いファインチューニング手法の探求を促している。
- MLM、prefix LM、span denoising、MoD などのさまざまな事前訓練目的とデータ構成戦略は、データ効率と下流の転移に影響を与え、トレードオフについての研究が進行中である。
- 本論文は、チャットボット、計算生物学、プログラミング、創造的作業、知識作業、法、医療、推論、ロボティクス、社会科学、合成データ生成など、幅広い応用分野を調査している。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。