[論文レビュー] ChatGPT Asks, BLIP-2 Answers: Automatic Questioning Towards Enriched Visual Descriptions
本論文は ChatCaptioner を提案する。ChatGPT が BLIP-2 に質問を投げて画像キャプションを充実させる自動質問システムで、BLIP-2 単独よりも情報性の高い記述と検出される物体数を得られ、ヒトによる評価で検証された。
Asking insightful questions is crucial for acquiring knowledge and expanding our understanding of the world. However, the importance of questioning has been largely overlooked in AI research, where models have been primarily developed to answer questions. With the recent advancements of large language models (LLMs) like ChatGPT, we discover their capability to ask high-quality questions when provided with a suitable prompt. This discovery presents a new opportunity to develop an automatic questioning system. In this paper, we introduce ChatCaptioner, a novel automatic-questioning method deployed in image captioning. Here, ChatGPT is prompted to ask a series of informative questions about images to BLIP-2, a strong vision question-answering model. By keeping acquiring new visual information from BLIP-2's answers, ChatCaptioner is able to generate more enriched image descriptions. We conduct human-subject evaluations on common image caption datasets such as COCO, Conceptual Caption, and WikiArt, and compare ChatCaptioner with BLIP-2 as well as ground truth. Our results demonstrate that ChatCaptioner's captions are significantly more informative, receiving three times as many votes from human evaluators for providing the most image information. Besides, ChatCaptioner identifies 53% more objects within the image than BLIP-2 alone measured by WordNet synset matching. Code is available at https://github.com/Vision-CAIR/ChatCaptioner
研究の動機と目的
- 自動的に指示に従う大規模言語モデルが、画像キャプションを改善する有益な質問を生成できることを示す。
- ChatGPT と BLIP-2 の間に自動的な質問生成ループを統合し、より多くの画像情報を抽出する。
- 充実したキャプションがより有益で、ベースラインのキャプションモデルより多くの物体をカバーするかを評価する。
- 複数のデータセットで人間の研究を通じて質問の質とキャプションの正確さを評価する。
提案手法
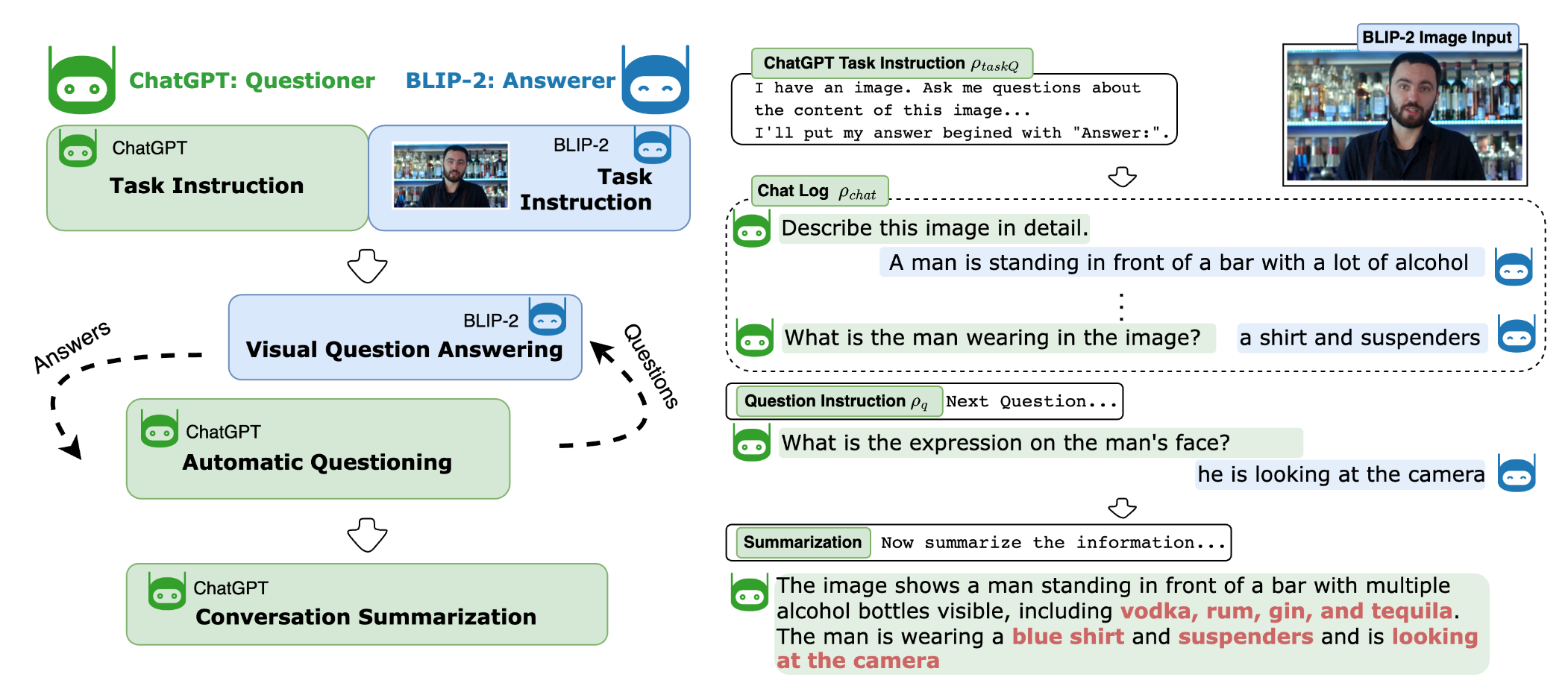
- 画像について1つの有益な質問を順に生成させるために ChatGPT にプロンプトを与え、前の Q&A を踏まえる(三部構成のプロンプト: タスク指示、チャットログ、各質問の指示)。
- BLIP-2 を視覚的質問応答の回答者として使用し、回答を捏造しないよう不確実性のプロンプトを付ける。
- 回答パターンに従って作成された虚偽の回答は破棄し、対話の一貫性を保つ。
- ChatGPT との対話を要約して最終の充実した画像キャプションを作成する。
- BLIP-2 およびグラウンドトゥルースのキャプションと人間評価を用いてキャプションを比較し、WordNet の synset マッチングを用いて物体カバー率を分析する。

実験結果
リサーチクエスチョン
- RQ1ChatGPT は静的キャプションよりも多様で有益な質問を生成し、BLIP-2 からより多くの視覚情報を抽出できるか。
- RQ2ChatCaptioner のキャプションは BLIP-2 単独よりも豊かな画像記述を提供し、より多くの物体を識別するか。
- RQ3不確実性プロンプトがBLIP-2の回答品質と全体のキャプションの正確性に与える影響は何か。
- RQ4画像やデータセットを跨いで、自動質問機構が生成する質問はどの程度多様か。
- RQ5人間の評価者は、ChatCaptioner のキャプションをベースラインと比較して情報量と正確さをどのように評価するか。
主な発見
- ChatCaptioner のキャプションは著しく情報量が多く、最も画像情報を提供したとして人の投票を3倍獲得した。
- ChatCaptioner は WordNet の同義語セットの照合で、BLIP-2 単独より画像内の物体を53%多く識別する。
- 不確実性プロンプトは、答えられないまたは曖昧な質問における不確実性に対処することで BLIP-2 の誤回答を減らす。
- 自動的な質問は多様で、画像の高レベル・物体レベル・数値・文脈的側面を網羅している。
- ChatGPT と InstructGPT は強力で重複しない質問生成を示す一方、小型モデルは反復や質問能力の低さを示す。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。