[論文レビュー] ChatGPT: Beginning of an End of Manual Linguistic Data Annotation? Use Case of Automatic Genre Identification
本論文は、自動ジャンル識別におけるゼロショットの ChatGPT を評価し、英語とスロベニア語の両方で微調整済みの X-GENRE モデルと比較する。未見データで ChatGPT が微調整済みモデルを上回る可能性と、プロンプトの言語が性能に影響を与えることを示している。
ChatGPT has shown strong capabilities in natural language generation tasks, which naturally leads researchers to explore where its abilities end. In this paper, we examine whether ChatGPT can be used for zero-shot text classification, more specifically, automatic genre identification. We compare ChatGPT with a multilingual XLM-RoBERTa language model that was fine-tuned on datasets, manually annotated with genres. The models are compared on test sets in two languages: English and Slovenian. Results show that ChatGPT outperforms the fine-tuned model when applied to the dataset which was not seen before by either of the models. Even when applied on Slovenian language as an under-resourced language, ChatGPT's performance is no worse than when applied to English. However, if the model is fully prompted in Slovenian, the performance drops significantly, showing the current limitations of ChatGPT usage on smaller languages. The presented results lead us to questioning whether this is the beginning of an end of laborious manual annotation campaigns even for smaller languages, such as Slovenian.
研究の動機と目的
- 英語とスロベニア語における自動ジャンル識別のための ChatGPT のゼロショット性能を評価する。
- 多言語ジャンルデータセットで訓練された微調整済みの X-GENRE 分類器と ChatGPT を比較する。
- プロンプト言語が ChatGPT の分類性能に与える影響を調査する。
- ChatGPT と X-GENRE の結果の一致度と補完性を分析する。
- NLP 研究における手動アノテーションの取り組みに対する影響を論じる。
提案手法
- EN-GINCO (英語) と GINCO (スロベニア語) データセットを用い、各々 100 のテスト事例を X-GENRE スキーマでラベル付けする。
- CORE、FTD、GINCO データセットの約1,700 件の手動アノテーション済みテキストで X-GENRE (XLM-RoBERTa) を微調整し、X-GENRE ラベルへマッピングする。
- 3 つのシナリオで ChatGPT にプロンプトを与える:英語テキストを英語プロンプト、スロベニア語テキストを英語プロンプト、スロベニア語テキストをスロベニア語プロンプト。
- 出力から ChatGPT の予測と説明を抽出し、X-GENRE スキーマの正解ラベルと比較して評価する。
- X-GENRE との比較で micro F1、macro F1、そして accuracy を比較し、意見の相違を分析して補完的な強みを評価する。
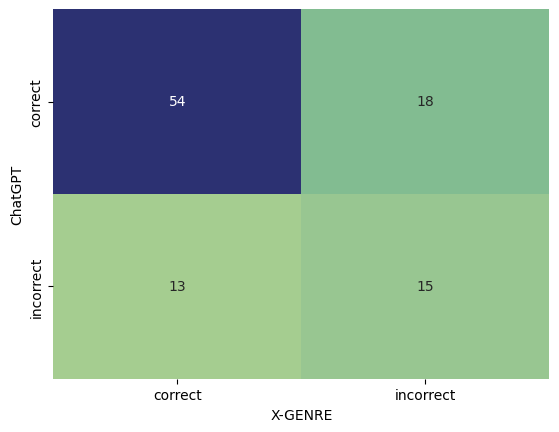
実験結果
リサーチクエスチョン
- RQ1未見データに対して、ChatGPT が微調整済みの多言語分類器と同等のゼロショットジャンル識別を実現できるか?
- RQ2英語とスロベニア語のテキスト、および異なる言語でプロンプトされた場合の ChatGPT の性能はどう異なるか?
- RQ3プロンプト言語が ChatGPT のジャンル分類精度に与える影響は何か?
- RQ4ChatGPT と X-GENRE は、組み合わせて性能を向上させる可能性がある補完的な予測を生み出すか?
主な発見
| Test set | Prompt language | Model | Micro F1 | Macro F1 | Accuracy |
|---|---|---|---|---|---|
| EN-GINCO | EN | ChatGPT | 0.74 | 0.66 | 0.72 |
| EN-GINCO | EN | X-GENRE | 0.67 | 0.61 | 0.67 |
| GINCO | SL | ChatGPT | 0.68 | 0.56 | 0.68 |
| GINCO | SL | X-GENRE | 0.91 | 0.91 | 0.91 |
| GINCO | EN | ChatGPT | 0.75 | 0.64 | 0.75 |
| GINCO | EN | X-GENRE | 0.91 | 0.91 | 0.91 |
- ChatGPT は英語のプロンプトで EN-GINCO の英語テストセットにおいて X-GENRE を上回る(micro F1 0.74、macro F1 0.66、accuracy 0.72 対 0.67/0.61/0.67)。
- スロベニア語データ(GINCO)では、スロベニア語テキストでスロベニア語プロンプトを用いた場合、X-GENRE が ChatGPT を大きく上回る(micro F1 0.91、macro F1 0.91、accuracy 0.91;ChatGPT 0.68/0.56/0.68)。
- ChatGPT のスロベニア語テキストに対する性能は、英語プロンプトの場合、英語テキストと同程度だが、スロベニア語プロンプト時には性能が低下する。
- ChatGPT の予測は X-GENRE と大部分で補完的で、主要な誤りが異なるため、特定の使用ケースでアンサンブルによる利得を示唆する。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。