[論文レビュー] ChatHaruhi: Reviving Anime Character in Reality via Large Language Model
この論文は、メモリを拡張したプロンプトとキャラクター対話コーパスを用いて、LLM が特定のキャラクターをロールプレイできるようにする ChatHaruhi を提示し、32 人物分の54K対話データセットを公開する。
Role-playing chatbots built on large language models have drawn interest, but better techniques are needed to enable mimicking specific fictional characters. We propose an algorithm that controls language models via an improved prompt and memories of the character extracted from scripts. We construct ChatHaruhi, a dataset covering 32 Chinese / English TV / anime characters with over 54k simulated dialogues. Both automatic and human evaluations show our approach improves role-playing ability over baselines. Code and data are available at https://github.com/LC1332/Chat-Haruhi-Suzumiya .
研究の動機と目的
- 架空のキャラクターのロールプレイを改善する動機付け: LLMの記憶、一貫性、および幻覚問題に対処すること。
- システムプロンプト、キャラクター memories、対話 memories を用いて役柄内の応答を導くアルゴリズムを提案する。
- 32人のキャラクターを跨ぐデータセット ChatHaruhi-54K を構築し、ペルソナベースのチャットボットを訓練・評価する。
- 大規模モデル(ChatGPT/Claude)と小規模モデル(7B)の両方がファインチューニングとデータ生成により役柄内対話を行えるようにする。
提案手法
- 知識/背景、性格、言語習慣という3要素のキャラクター表現を定義する。
- 脚本の元の対話を抽出し、各キャラクターのメモリ銀行Dに保存する。
- 文の埋め込みでメモリ銀行Uを検索し、与えられたユーザ問い合わせqに対して最も関連の対話メモリを取り出す。
- 原典の台詞の再利用とコスプレ感を強調するシステムプロンプトsRを用いて出力を導く。
- 約1200トークン程度に制限した対話履歴Hを維持し、首尾一貫した応答を保証する。
- Alpaca風のプロンプトで追加の役柄内対話を自動生成しDを作成して微調整データを拡張する(ChatHaruhi-54K へ導く)。
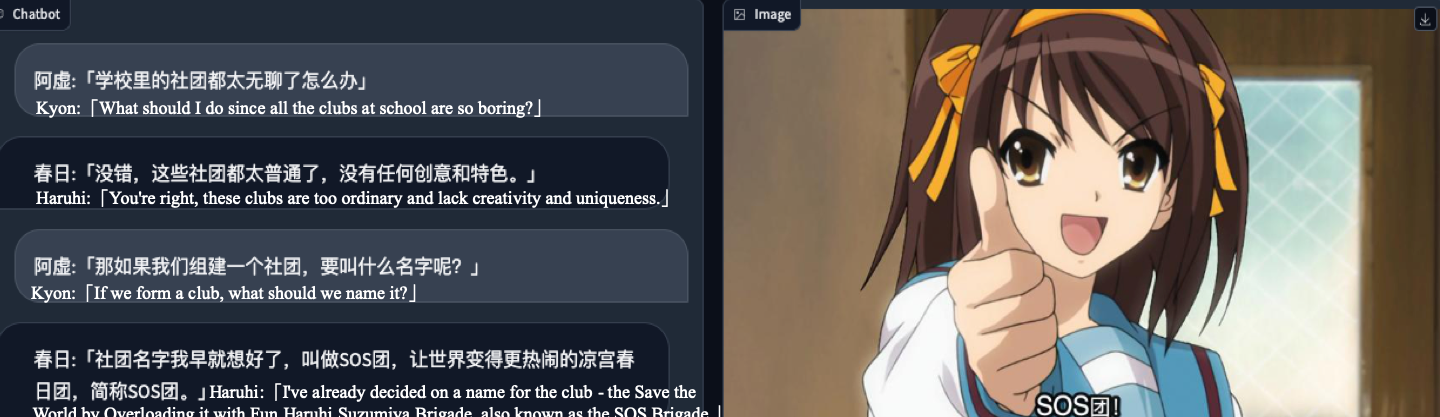
実験結果
リサーチクエスチョン
- RQ1メモリを拡張したプロンプティングシステムは、同じベースモデルに対して従来のプロンプトを大幅に超えるキャラクターのロールプレイ能力を改善できるのか?
- RQ2元の脚本メモリと生成対話を組み合わせると、言語を跨いだより忠実で一貫したキャラクター表現を生み出せるのか?
- RQ3メモリ取得とプロンプト設計がキャラクターの設定と語彙スタイルへの整合性に与える影響は?
- RQ4ChatHaruhi-54K データで微調整したローカルの7Bモデルは、より大きなモデルと同程度に役柄内挙動を再現できるのか?
主な発見
- ChatHaruhi パイプラインは、同じベースモデルを用いた場合のベースラインよりもキャラ内整合性と応答品質を向上させる。
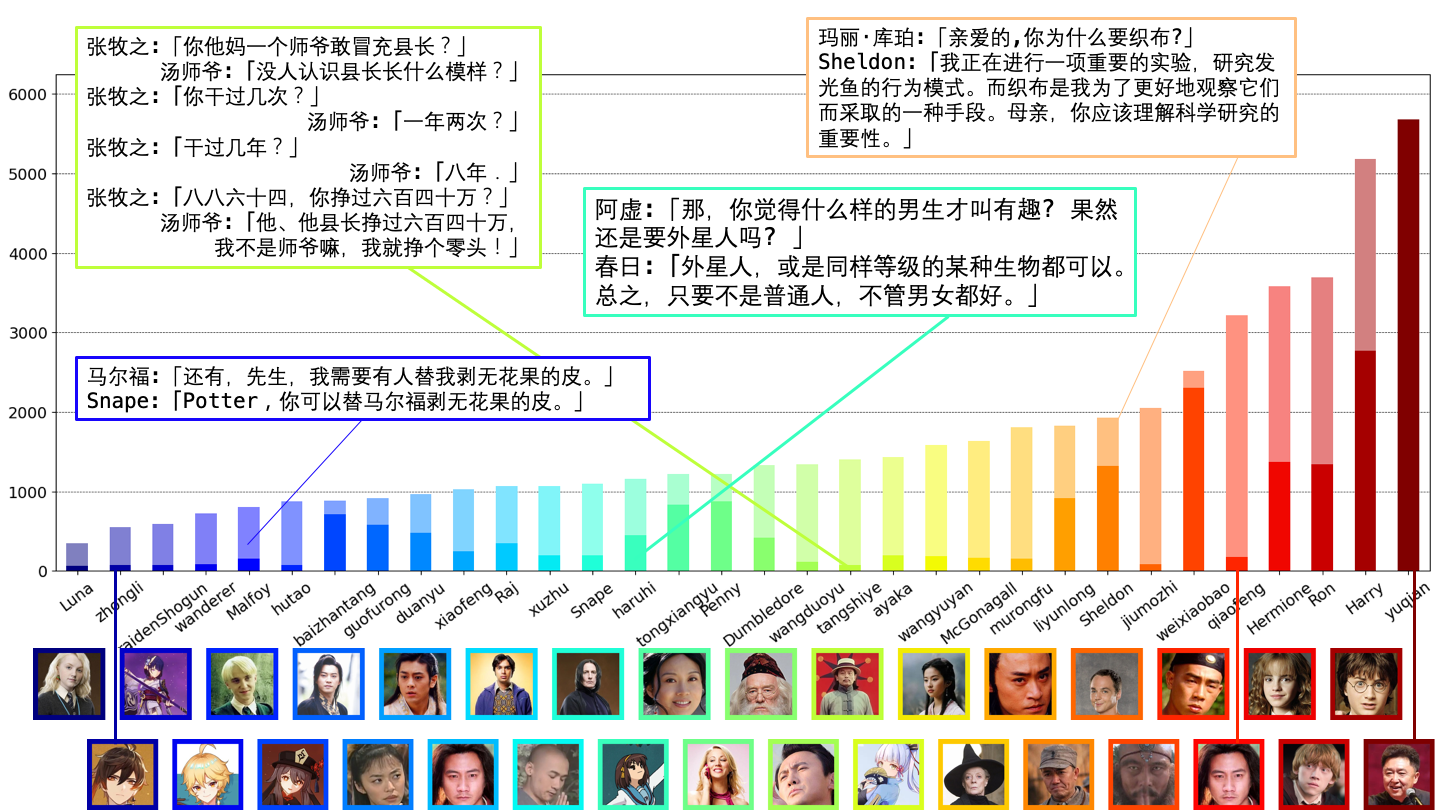
- 著者らは ChatHaruhi-54K を、元の対話 22,752 とシミュレート対話 31,974、合計 54,726 を32キャラクターで構築した。
- 評価には自動的な類似性ベースの指標と、計画された人間の整合性/品質評価の両方を含む。
- ChatHaruhi データで 7B モデルをファインチューニングした場合、22,752 データと 54K データでそれぞれ訓練されたモデル(A/B)を得て、評価が報告されている。
- このシステムは ChatGPT/Claude の利用またはローカルでのファインチューニング済み 7B の利用をサポートし、柔軟なデプロイを可能にする。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。