[論文レビュー] ChatPose: Chatting about 3D Human Pose
PoseGPT は、SMPL ポーズを別個のトークンとして埋め込み、テキストまたは画像から 3D 人間ポーズを生成・推論するマルチモーダル LLM フレームワークであり、推測ポーズ生成と推論ベースのポーズ推定ベンチマークを導入します。
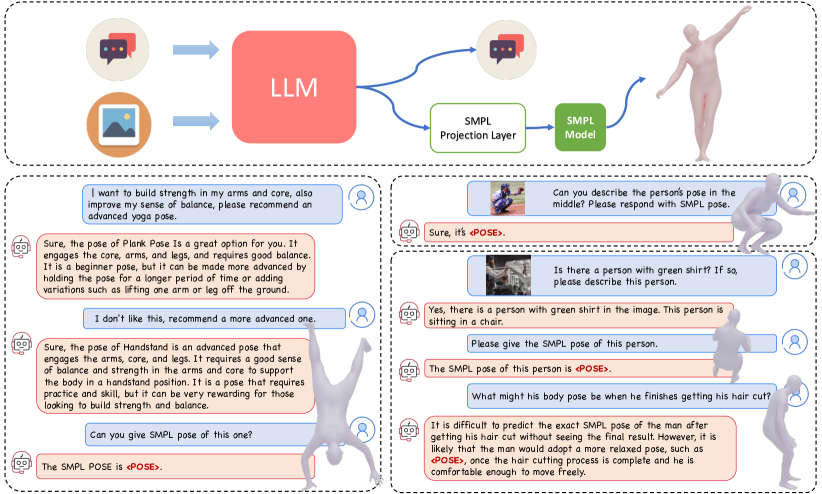
We introduce ChatPose, a framework employing Large Language Models (LLMs) to understand and reason about 3D human poses from images or textual descriptions. Our work is motivated by the human ability to intuitively understand postures from a single image or a brief description, a process that intertwines image interpretation, world knowledge, and an understanding of body language. Traditional human pose estimation and generation methods often operate in isolation, lacking semantic understanding and reasoning abilities. ChatPose addresses these limitations by embedding SMPL poses as distinct signal tokens within a multimodal LLM, enabling the direct generation of 3D body poses from both textual and visual inputs. Leveraging the powerful capabilities of multimodal LLMs, ChatPose unifies classical 3D human pose and generation tasks while offering user interactions. Additionally, ChatPose empowers LLMs to apply their extensive world knowledge in reasoning about human poses, leading to two advanced tasks: speculative pose generation and reasoning about pose estimation. These tasks involve reasoning about humans to generate 3D poses from subtle text queries, possibly accompanied by images. We establish benchmarks for these tasks, moving beyond traditional 3D pose generation and estimation methods. Our results show that ChatPose outperforms existing multimodal LLMs and task-specific methods on these newly proposed tasks. Furthermore, ChatPose's ability to understand and generate 3D human poses based on complex reasoning opens new directions in human pose analysis.
研究の動機と目的
- 統一されたモデルで画像/テキストの理解と 3D 人間ポーズの bridg ing を動機づける。
- チャット型のマルチモーダル LLM を介して SMPL ポーズの生成と推定を可能にする。
- 推測ポーズ生成と推論ベースのポーズ推定を新しいタスクとして導入する。
提案手法
- SMPL ポーズを<POSE>トークンとしてマルチモーダル LLM に埋め込み、言語埋め込みをMLP投影層を介して SMPL ポーズパラメータへマッピングする。
- 訓練中はビジョンエンコーダを凍結し、LoRAで LLM をファインチューニングする一方、SMPL 投影層のみ訓練する。
- テキストtoポーズ、画像toポーズ、マルチモーダル指示追従データで訓練し、ポーズ生成とポーズ推論を可能にする。
実験結果
リサーチクエスチョン
- RQ1マルチモーダル LLM はテキストまたは画像から 3D 人間ポーズ(SMPL)を理解・生成できるか?
- RQ2世界と場の知識を活用して推測ポーズ生成と推論ベースのポーズ推定をモデルは実行できるか?
- RQ3PoseGPT はポーズ生成とポーズ推定において、タスク特化型および他のマルチモーダル基準と比較してどうか、推論ベースのタスクを含めて?
主な発見
| Method | MPJPE 3DPW (mm) | PA-MPJPE 3DPW (mm) | MPJRE 3DPW | MPJPE H36M (mm) | PA-MPJPE H36M (mm) | MPJRE H36M |
|---|---|---|---|---|---|---|
| PoseGPT (ours) | 163.6 | 81.9 | 10.4 | 126.0 | 82.4 | 10.4 |
- PoseGPT はテキストまたは画像から SMPL ポーズを生成でき、対話駆動のポーズ推論を可能にする。
- 推測ポーズ生成では PoseGPT は PoseScript を上回り、古典的ポーズ生成ベースラインと競合的な結果を達成する。
- 推論ベースのポーズ推定では PoseGPT は他のマルチモーダル LLM やタスク特化法を上回るが、標準的なポーズ推定指標では古典的ポーズ推定器が依然として強力。
- モデルは遮蔽に対するロバスト性を示し、テキストポーズ記述よりもポーズ埋め込みを使用することが有益である。
- より大きい LLM バックボーン(13B 対 7B)を使用すると PoseGPT の性能が向上する。
- このアプローチは、3D ポーズ文脈で推論能力を評価する二つの新しいベンチマーク(SPG と RPE)を可能にする。
![Figure 2 : Method and Training Overview. Our model is composed of a multi-modal LLM (with vision encoder, vision projection layer and LLM), a SMPL projection layer, and the parametric human body model, i.e. SMPL [ 29 ] . The multi-modal LLM processes text and image inputs (if provided) to generate t](https://ar5iv.labs.arxiv.org/html/2311.18836/assets/x2.png)
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。