[論文レビュー] ChatSpamDetector: Leveraging Large Language Models for Effective Phishing Email Detection
ChatSpamDetector は Large Language Models を用いて、メールを LLM 互換のプロンプトへ変換することによりフィッシングメールを検出し、意思決定の詳細な合理化を提供する。 diverse phishing dataset で GPT-4 による 99.70% の精度を達成します。
The proliferation of phishing sites and emails poses significant challenges to existing cybersecurity efforts. Despite advances in malicious email filters and email security protocols, problems with oversight and false positives persist. Users often struggle to understand why emails are flagged as potentially fraudulent, risking the possibility of missing important communications or mistakenly trusting deceptive phishing emails. This study introduces ChatSpamDetector, a system that uses large language models (LLMs) to detect phishing emails. By converting email data into a prompt suitable for LLM analysis, the system provides a highly accurate determination of whether an email is phishing or not. Importantly, it offers detailed reasoning for its phishing determinations, assisting users in making informed decisions about how to handle suspicious emails. We conducted an evaluation using a comprehensive phishing email dataset and compared our system to several LLMs and baseline systems. We confirmed that our system using GPT-4 has superior detection capabilities with an accuracy of 99.70%. Advanced contextual interpretation by LLMs enables the identification of various phishing tactics and impersonations, making them a potentially powerful tool in the fight against email-based phishing threats.
研究の動機と目的
- Motivate defenses against phishing emails where conventional filters lack explanations for classifications.
- Propose a system that converts emails into prompts for LLM analysis to detect phishing.
- Enable detailed, rationale-rich reports to help users decide how to handle suspicious emails.
提案手法
- Parse and decode .eml emails to extract headers and body while omitting server-filtering headers.
- Simplify long emails to fit LLM token limits (3,000 tokens) with HTML/text pruning.
- Generate task-specific prompts and use chain-of-thought prompting for structured analysis.
- Use Function Calling to have LLMs return a JSON report with is_phishing, phishing_score, brand_impersonated, rationales, and brief_reason.
- Evaluate multiple LLMs (GPT-4, GPT-3.5, Llama2, Gemini Pro) against baselines on a phishing/ham dataset.
- Compare prompting strategies (Normal vs Simple prompts) and analyze false positives/negatives.]
- research_questions: ["Can LLMs reliably detect phishing emails when prompted with email-derived prompts?", "How do different LLMs (GPT-4, GPT-3.5, Llama2, Gemini Pro) compare in phishing detection performance on current datasets?", "Does providing structured rationales and brand impersonation information improve trust and decision-making for users?", "What is the impact of prompt design (normal vs simple) on precision, recall, and false positives?", "How do system outputs compare to traditional baseline classifiers on modern phishing emails?"]
- key_findings:["GPT-4 with a normal prompt achieved 99.70% accuracy, outperforming other models and baselines.", "Simple prompts reduced false positives but lowered recall for several models; normal prompts improved phishing identification and reduced false positives overall.", "GPT-4 generally provided the strongest performance (accuracy, precision, recall) among evaluated models (GPT-4 > GPT-3.5 > Gemini Pro > Llama2).", "The system achieved high phishing detection while extracting and reporting key indicators from headers and body, including brand impersonation and SE techniques.", "Compared to baselines, ChatSpamDetector substantially outperformed traditional feature-based methods on the same dataset.", "Reported latency and cost varied by model, with GPT-4 averaging ~12.5s per request and GPT-3.5 ~2.5s, and GPT-4 costing more."]
- table_headers:["System","Model","Prompt","TP","FP","TN","FN","Precision","Recall","Accuracy"]
- table_rows:[["ChatSpamDetector","GPT-4","Normal","1,007","3","997","3","99.70%","99.70%","99.70%"],["ChatSpamDetector","GPT-4","Simple","1,001","4","996","9","99.60%","99.11%","99.35%"],["ChatSpamDetector","GPT-3.5","Normal","980","32","968","30","96.84%","97.03%","96.92%"],["ChatSpamDetector","GPT-3.5","Simple","697","6","994","313","99.15%","69.01%","84.13%"],["ChatSpamDetector","Llama2","Normal","950","361","639","60","72.46%","94.06%","79.05%"],["ChatSpamDetector","Llama2","Simple","790","9","991","220","98.87%","78.22%","88.61%"],["ChatSpamDetector","Gemini Pro","Normal","991","21","979","19","97.92%","98.12%","98.01%"],["ChatSpamDetector","Gemini Pro","Simple","977","6","994","33","99.39%","96.73%","98.06%"],["Baseline A","-","-","-","580","374","626","430","60.80%","57.43%","60.00%"],["Baseline B","-","-","-","564","413","587","446","57.73%","55.84%","57.26%"],["Baseline C","-","-","-","923","827","173","87","52.74%","91.39%","54.53%"],["Baseline D","-","-","-","941","208","792","69","81.90%","93.17%","86.22%"]]} }
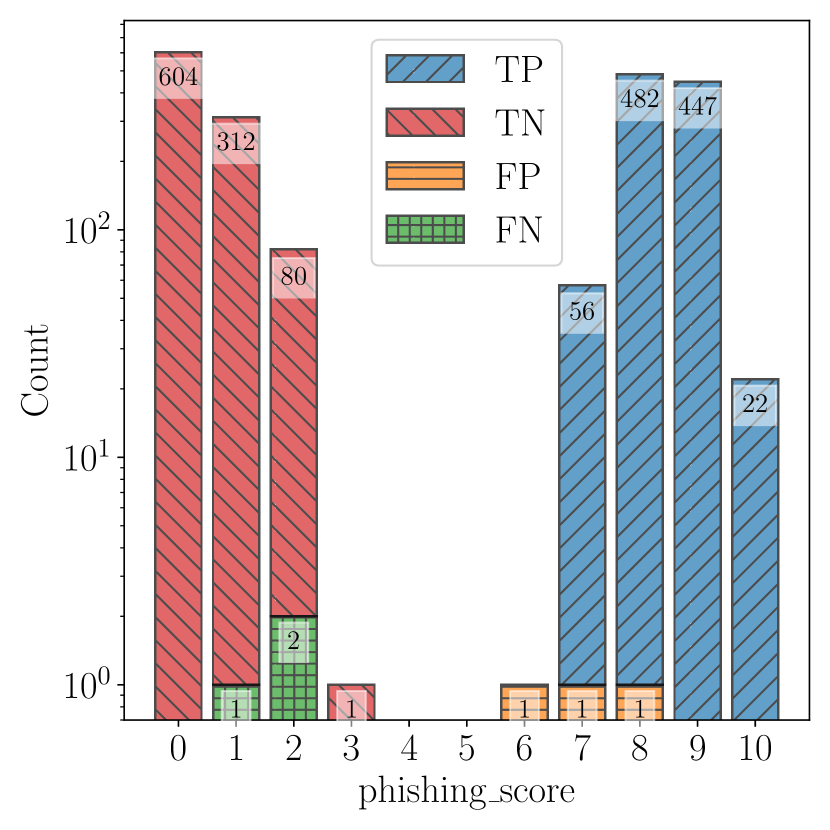
実験結果
リサーチクエスチョン
- RQ1Can LLMs reliably detect phishing emails when prompted with email-derived prompts?
- RQ2How do different LLMs (GPT-4, GPT-3.5, Llama2, Gemini Pro) compare in phishing detection performance on current datasets?
- RQ3Does providing structured rationales and brand impersonation information improve trust and decision-making for users?
- RQ4What is the impact of prompt design (normal vs simple) on precision, recall, and false positives?
- RQ5How do system outputs compare to traditional baseline classifiers on modern phishing emails?
主な発見
| システム | モデル | プロンプト | TP | FP | TN | FN | 適合率 | 再現率 | 正確度 | |
|---|---|---|---|---|---|---|---|---|---|---|
| ChatSpamDetector | GPT-4 | Normal | 1,007 | 3 | 997 | 3 | 99.70% | 99.70% | 99.70% | |
| ChatSpamDetector | GPT-4 | Simple | 1,001 | 4 | 996 | 9 | 99.60% | 99.11% | 99.35% | |
| ChatSpamDetector | GPT-3.5 | Normal | 980 | 32 | 968 | 30 | 96.84% | 97.03% | 96.92% | |
| ChatSpamDetector | GPT-3.5 | Simple | 697 | 6 | 994 | 313 | 99.15% | 69.01% | 84.13% | |
| ChatSpamDetector | Llama2 | Normal | 950 | 361 | 639 | 60 | 72.46% | 94.06% | 79.05% | |
| ChatSpamDetector | Llama2 | Simple | 790 | 9 | 991 | 220 | 98.87% | 78.22% | 88.61% | |
| ChatSpamDetector | Gemini Pro | Normal | 991 | 21 | 979 | 19 | 97.92% | 98.12% | 98.01% | |
| ChatSpamDetector | Gemini Pro | Simple | 977 | 6 | 994 | 33 | 99.39% | 96.73% | 98.06% | |
| Baseline A | - | - | - | 580 | 374 | 626 | 430 | 60.80% | 57.43% | 60.00% |
| Baseline B | - | - | - | 564 | 413 | 587 | 446 | 57.73% | 55.84% | 57.26% |
| Baseline C | - | - | - | 923 | 827 | 173 | 87 | 52.74% | 91.39% | 54.53% |
| Baseline D | - | - | - | 941 | 208 | 792 | 69 | 81.90% | 93.17% | 86.22% |
- GPT-4 with a normal prompt achieved 99.70% accuracy, outperforming other models and baselines.
- Simple prompts reduced false positives but lowered recall for several models; normal prompts improved phishing identification and reduced false positives overall.
- GPT-4 generally provided the strongest performance (accuracy, precision, recall) among evaluated models (GPT-4 > GPT-3.5 > Gemini Pro > Llama2).
- The system achieved high phishing detection while extracting and reporting key indicators from headers and body, including brand impersonation and SE techniques.
- Compared to baselines, ChatSpamDetector substantially outperformed traditional feature-based methods on the same dataset.
- Reported latency and cost varied by model, with GPT-4 averaging ~12.5s per request and GPT-3.5 ~2.5s, and GPT-4 costing more.
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。