[論文レビュー] ChatUniTest: A Framework for LLM-Based Test Generation
ChatUniTest は adaptive focal context generation および修復メカニズムを備えた Generation-Validation-Repair フレームワークを使用し、ChatGPT を介して高品質なユニットテストを生成します。EvoSuite、AthenaTest、A3Test を複数のカバレッジおよび正確さの指標で上回ります。
Unit testing is an essential yet frequently arduous task. Various automated unit test generation tools have been introduced to mitigate this challenge. Notably, methods based on large language models (LLMs) have garnered considerable attention and exhibited promising results in recent years. Nevertheless, LLM-based tools encounter limitations in generating accurate unit tests. This paper presents ChatUniTest, an LLM-based automated unit test generation framework. ChatUniTest incorporates an adaptive focal context mechanism to encompass valuable context in prompts and adheres to a generation-validation-repair mechanism to rectify errors in generated unit tests. Subsequently, we have developed ChatUniTest Core, a common library that implements core workflow, complemented by the ChatUniTest Toolchain, a suite of seamlessly integrated tools enhancing the capabilities of ChatUniTest. Our effectiveness evaluation reveals that ChatUniTest outperforms TestSpark and EvoSuite in half of the evaluated projects, achieving the highest overall line coverage. Furthermore, insights from our user study affirm that ChatUniTest delivers substantial value to various stakeholders in the software testing domain. ChatUniTest is available at https://github.com/ZJU-ACES-ISE/ChatUniTest, and the demo video is available at https://www.youtube.com/watch?v=GmfxQUqm2ZQ.
研究の動機と目的
- 自動化されたユニットテスト生成を動機づけ、開発者の負担を減らし、テストの可読性と正確さを向上させる。
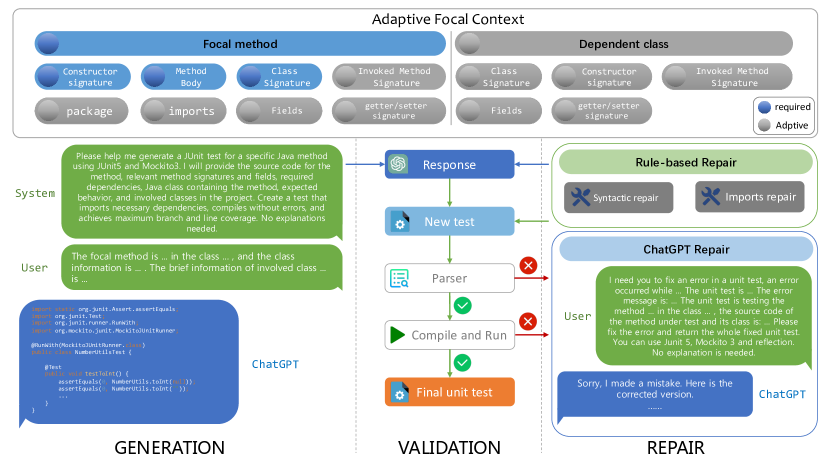
- プロンプトトークン制限を尊重する adaptive な focal context 生成を備えた ChatGPT ベースのフレームワーク(Generation-Validation-Repair)を提案する。
- 生成されたテストの構文/コンパイル/ランタイムの正確性を改善するための検証および修復コンポーネント(ルールベースおよび ChatGPT ベース)を導入する。
- ChatUniTest を EvoSuite、AthenaTest、A3Test と複数の Java プロジェクトおよび Defects4J データセットで実証的に評価する。
提案手法
- AST を解析してクラスとメソッドのコンテキストを収集することで Java プロジェクトを前処理する。
- 最大プロンプトトークン制限の範囲内で adaptive focal context を生成し、ChatGPT へのプロンプトを形成する。
- Java パーサーとテスト実行器を用いて ChatGPT が生成したテストを抽出・解析・検証する。
- ルールベースのコンポーネントで構文/コンパイルエラーを修復する。複雑なエラーには ChatGPT ベースの修復を呼び出す。
- 構文的正確性、コンパイル、実行時の成功、アサーションの使用、モックを評価し、基準と比較してカバレッジを評価する。
実験結果
リサーチクエスチョン
- RQ1RQ1: 生成されたユニットテストの構文、コンパイル、実行、正確性の品質はどの程度か?
- RQ2RQ2: カバレッジと正確さの観点で ChatUniTest の性能は EvoSuite、AthenaTest、A3Test とどのように比較されるか?
- RQ3RQ3: ChatUniTest の各コンポーネント(生成、ルールベース修復、ChatGPT ベース修復)の全体品質への寄与はどれくらいか?
- RQ4RQ4: ChatUniTest でユニットテストを生成する際の実用的コスト(トークン使用量)はどの程度か?
主な発見
| Projects | Branch Coverage (EvoSuite) | Branch Coverage (ChatUniTest) | Line Coverage (EvoSuite) | Line Coverage (ChatUniTest) |
|---|---|---|---|---|
| Lang | 84.92% | 94.70% | 84.71% | 91.94% |
| Cli | 90.90% | 96.36% | 90.93% | 93.52% |
| Csv | 75.87% | 84.09% | 70.28% | 86.61% |
| Gson | 59.23% | 83.88% | 61.53% | 86.80% |
| Chart | 87.67% | 88.27% | 85.90% | 84.03% |
| Ecommerce | 100% | 100% | 89.58% | 96.35% |
| Datafaker | 91.12% | 89.76% | 58.55% | 86.07% |
| Flink-k8s-opr | 89.72% | 78.76% | 87.14% | 83.02% |
| Binance-conn | 98.72% | 97.17% | 87.59% | 97.87% |
| Event-ruler | 87.78% | 93.14% | 84.02% | 87.40% |
| Average | 86.59% | 90.61% | 80.02% | 89.36% |
- ChatUniTest は 97,878 回の成功試行のうち、合格率 30.86%、正しいテスト 29.98% を達成。
- 10 の Java プロジェクトで、ChatUniTest は一般に EvoSuite よりブランチカバレッジとラインカバレッジで優れており、平均ブランチ 90.61%、ライン 89.36% 。
- Defects4J での AthenaTest および A3Test との比較では、ChatUniTest が焦点メソッドカバレッジと正しいテストの割合で多くのケースで高い値を示した。
- Adaptive focal context generation によりプロンプトがトークン制限内に収まり、切り捨てを減らしてより完全な回答を得られる。
- ルールベースの修復は構文・インポート関連のエラーを大きく減少させる。ChatGPT ベースの修復は合格テストと正しいテストの得点を大幅に増加させ、より困難なエラーに対応している。

より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。