[論文レビュー] Check Your Facts and Try Again: Improving Large Language Models with External Knowledge and Automated Feedback
この論文は LLM-Augmenter を提案する。固定された LLM を外部知識で拡張し、自動フィードバックによる反復的なプロンプト改良、および幻覚を低減しつつ流暢さを維持する学習可能な方針を組み合わせたプラグアンドプレイ型のシステムである。情報探索的対話とオープンドメインの Wiki QA に対する有効性を検証する。
Large language models (LLMs), such as ChatGPT, are able to generate human-like, fluent responses for many downstream tasks, e.g., task-oriented dialog and question answering. However, applying LLMs to real-world, mission-critical applications remains challenging mainly due to their tendency to generate hallucinations and their inability to use external knowledge. This paper proposes a LLM-Augmenter system, which augments a black-box LLM with a set of plug-and-play modules. Our system makes the LLM generate responses grounded in external knowledge, e.g., stored in task-specific databases. It also iteratively revises LLM prompts to improve model responses using feedback generated by utility functions, e.g., the factuality score of a LLM-generated response. The effectiveness of LLM-Augmenter is empirically validated on two types of scenarios, task-oriented dialog and open-domain question answering. LLM-Augmenter significantly reduces ChatGPT's hallucinations without sacrificing the fluency and informativeness of its responses. We make the source code and models publicly available.
研究の動機と目的
- 大規模言語モデルをミッションクリティカルなタスクに展開する際の幻覚と知識ギャップの削減を動機付ける。
- 外部知識で LLM の応答を grounding するプラグアンドプレー型アーキテクチャ(LLM-Augmenter)を提案する。
- 自動フィードバックによる反復的なプロンプト改良を有効化し、応答品質を向上させる。
- 固定された LLM を完全なファインチューニングなしで動作させるポリシーとモジュールの訓練戦略を探求する。
提案手法
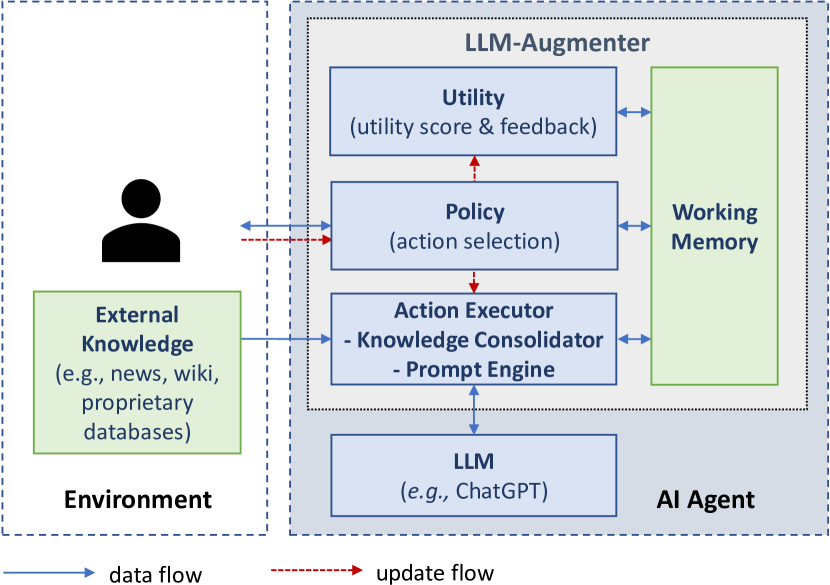
- 外部知識と自動フィードバックを組み込む固定 LLM のプラグアンドプレイモジュールとしての LLM-Augmenter を導入する。
- 人間-システムの会話をマルコフ決定過程としてモデル化し、モジュール間の相互作用を導く。
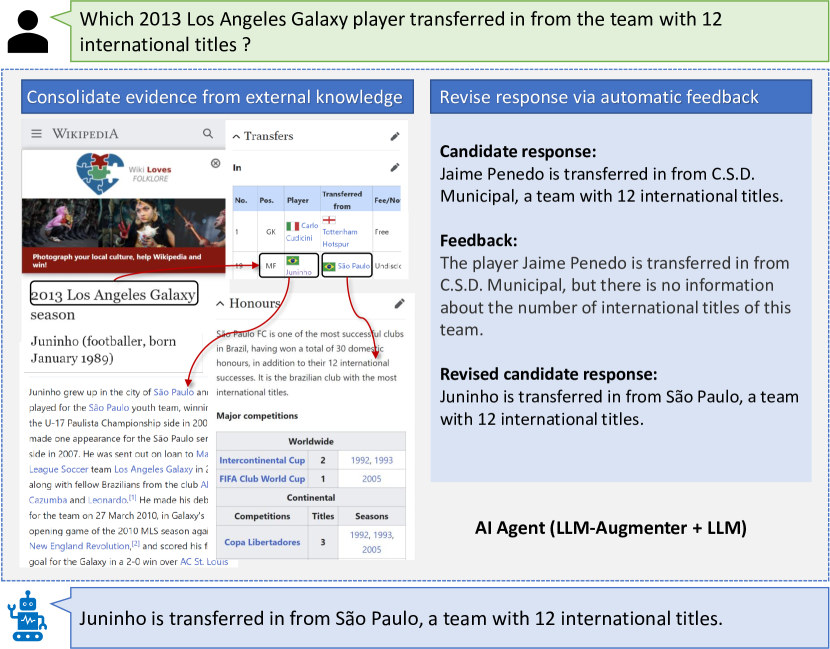
- 外部証拠を取得・連結する Knowledge Consolidator と grounding のための Evidence Chainer を実装する。
- Evidence とフィードバックを組み込んだ prompts を生成する Prompt Engine を用いる。
- プロンプト改良を導くスコアとフィードバックを生成する Utility モジュールを開発する。
- REINFORCE によってポリシー (pi) を訓練し、 grounding と有用性に基づく報酬を最大化する。
実験結果
リサーチクエスチョン
- RQ1外部知識 grounding は、流暢さを損なうことなく固定 LLM の幻覚を減らすことができるか。
- RQ2自動フィードバックと反復的なプロンプト改良は、回答の事実 grounding と有用性を向上させるか。
- RQ3知識源の使用を決定する訓練可能なポリシーはどの程度効果的か。
- RQ4知識統合とフィードバックがオープンディメンション Wiki QA と対話タスクに及ぼす影響はどの程度か。
主な発見
| モデル | 知識統合 | フィードバック | P↑ | R↑ | F1↑ |
|---|---|---|---|---|---|
| ChatGPT | - | - | 0.48 | 1.52 | 0.59 |
| LLM-Augmenter | DPR | ✗ | 2.08 | 4.31 | 2.38 |
| LLM-Augmenter | CORE | ✗ | 8.93 | 33.87 | 11.80 |
| LLM-Augmenter | CORE | ✓ | 8.93 | 33.87 | 11.80 |
- LLM-Augmenter は News Chat や Customer Service タスクにおいて、ChatGPT 単独と比較して grounding を大幅に改善し幻覚を減少させる。
- 黄金知識を用いると大きな性能向上が得られ、タスク特有の外部知識が grounding の価値を強調する。
- 自動フィードバックと証拠統合を組み合わせると、KF1 などの指標がベースラインより substantial に改善される。
- 知識統合を伴う訓練可能なポリシーは、知識なしの統合子や self-ask の variante より grounding が向上し、常に知識を使用する場合よりも効率が高い。
- Wiki QA では CORE ベースの統合とフィードバックが、 raw DPR evidence および closed-book ChatGPT に比べ recall と F1 を有意に改善する。
- 人間の評価により、LLM-Augmenter は Customer Service シナリオで ChatGPT 単独より有用性が高く、人間らしさも高い。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。