[論文レビュー] Cinematic Mindscapes: High-quality Video Reconstruction from Brain Activity
MinD-Video は、fMRI から高品質で意味論的に意味のある動画を再構成する。拡張された Stable Diffusion ビデオジェネレータから fMRI エンコーダを切り離すことで進行的、マルチモーダル、および敵対的ガイダンスを用いる。最先端の意味論的精度と競争力のあるピクセル忠実度を達成し、注意マップによる解釈性を提供する。
Reconstructing human vision from brain activities has been an appealing task that helps to understand our cognitive process. Even though recent research has seen great success in reconstructing static images from non-invasive brain recordings, work on recovering continuous visual experiences in the form of videos is limited. In this work, we propose Mind-Video that learns spatiotemporal information from continuous fMRI data of the cerebral cortex progressively through masked brain modeling, multimodal contrastive learning with spatiotemporal attention, and co-training with an augmented Stable Diffusion model that incorporates network temporal inflation. We show that high-quality videos of arbitrary frame rates can be reconstructed with Mind-Video using adversarial guidance. The recovered videos were evaluated with various semantic and pixel-level metrics. We achieved an average accuracy of 85% in semantic classification tasks and 0.19 in structural similarity index (SSIM), outperforming the previous state-of-the-art by 45%. We also show that our model is biologically plausible and interpretable, reflecting established physiological processes.
研究の動機と目的
- 非侵襲的な脳活動(fMRI)から連続的な視覚体験(動画)を再構成する方法を理解する。
- 品質と柔軟性を向上させるため、fMRI エンコーディングと動画生成を分離した二部モジュールのパイプラインを開発する。
- fMRIの時間分解能のギャップを埋めるため、段階的な学習とマルチモーダル学習、時間的アテンションを活用する。
- Stable Diffusion ベースの動画生成器を、シーンダイナミックなアテンションと敵対的ガイダンスで拡張し、忠実度を高める。
提案手法
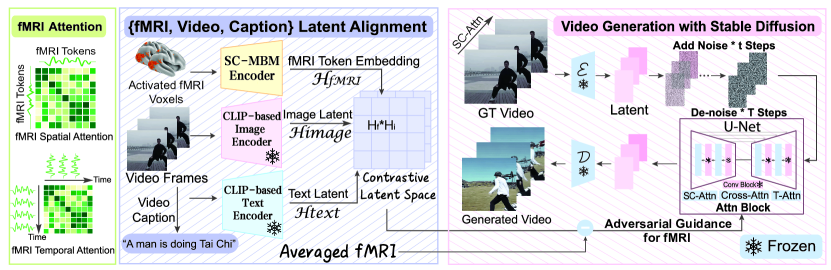
- 二部モジュール パイプライン:拡張された Stable Diffusion ビデオジェネレータから分離して fMRI エンコーダを訓練し、次にそれらを共同訓練する。
- 進行的学習:大規模 MBM の事前訓練を行い、窓状の fMRI に対する時空的アテンションを用いたマルチモーダル対比学習を続ける。
- スライディングウィンドウの fMRI を処理し、血行動的遅延を考慮する時空的アテンション。
- Scene-Dynamic Sparse CA (SC) アテンションを備えた拡張 Stable Diffusion により、前のフレームに基づいてフレームを条件付けつつ、シーン変化を許容。
- fMRI 条件付けサンプリングの品質を高めるためのネガティブ条件付けによる敵対的ガイダンス。
- 解釈可能性を持つ脳データからの学習:注意マップを視覚化してデコーダの戦略を脳ネットワークに対応付ける。

実験結果
リサーチクエスチョン
- RQ1HRF 遅延にもかかわらず、任意のフレームレートで fMRI から連続的な動画コンテンツを再構成できるか?
- RQ2共同訓練された動画ジェネレータと組み合わせた進行的・マルチモーダルな fMRI エンコーディングは、従来手法より意味論的およびピクセルレベルの忠実度を向上させるか?
- RQ3敵対的ガイダンスは条件付けの効果と生成動画の多様性にどのような影響を与えるか?
- RQ4注意マップは、デコードされた視覚コンテンツに寄与する脳領域とネットワークについて何を明らかにするか?
主な発見
- 本手法は動画内容の意味分類精度85%、SSIM 0.19 を達成し、従来の最先端を45%上回る。
- 被験者を跨いで、動きとシーンダイナミクスが正確な高品質な動画を生成する。
- アテンション解析は視覚皮質の優位性を示し、高次認知ネットワークの寄与とともに生物学的妥当性と一致する。
- 段階的学習段階は、局所的な視覚特徴からグローバルな特徴へ移行を反映し、後段の層は抽象的な意味情報に焦点を置く。
- アブレーション研究は、ウィンドウサイズ、マルチモーダル対比学習、そして性能のための敵対的ガイダンスの重要性を示す。
- このフレームワークは、シーン遷移を含む多様なシーンと動作の再構成を可能にしつつ、フレームの一貫性を維持する。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。