[論文レビュー] ClinicalGPT: Large Language Models Finetuned with Diverse Medical Data and Comprehensive Evaluation
ClinicalGPTは、多様な実世界の医療データでファインチューニングされた医療ドメインの大規模言語モデルであり、医療会話、診察、診断、QAタスク全般で評価され、いくつかのベースラインを上回っています。
Large language models have exhibited exceptional performance on various Natural Language Processing (NLP) tasks, leveraging techniques such as the pre-training, and instruction fine-tuning. Despite these advances, their effectiveness in medical applications is limited, due to challenges such as factual inaccuracies, reasoning abilities, and lack grounding in real-world experience. In this study, we present ClinicalGPT, a language model explicitly designed and optimized for clinical scenarios. By incorporating extensive and diverse real-world data, such as medical records, domain-specific knowledge, and multi-round dialogue consultations in the training process, ClinicalGPT is better prepared to handle multiple clinical task. Furthermore, we introduce a comprehensive evaluation framework that includes medical knowledge question-answering, medical exams, patient consultations, and diagnostic analysis of medical records. Our results demonstrate that ClinicalGPT significantly outperforms other models in these tasks, highlighting the effectiveness of our approach in adapting large language models to the critical domain of healthcare.
研究の動機と目的
- 医療専門のLLMが必要とされる理由を、一般モデルの事実性と根拠付けの課題から動機づける。
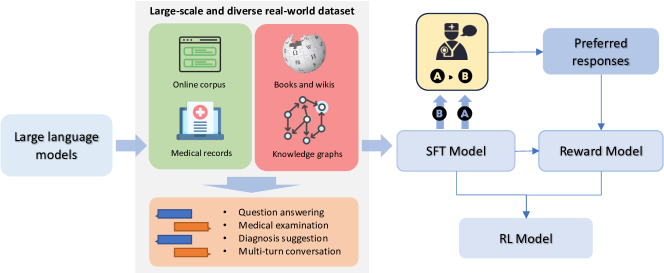
- ターゲットのファインチューニングのために、実世界の医療データ(記録、KG知識、試験、対話)を広範に集める。
- 会話、試験、診断、QAタスクにわたる総合的な評価フレームワークを確立する。
- パラメータ効率的なファインチューニング(LoRA)とRLHFベースの最適化を示して臨床パフォーマンスを向上させる。
提案手法
- ドメインデータと知識グラフ由来のQAペアを用いた教師あり命令調整でBLOOM-7Bをファインチューニングする。
- 人間の評価結果から報酬モデルを構築して強化学習を導く。
- 医療の正確性と有用性に出力を合わせつつ、大きな方策変更を抑制するKLペナルティを用いてProximal Policy Optimizationを用いた強化学習を適用する。
- パラメータ効率的適応のためのLoRAとZero-2メモリ最適化を用いてスケーラブルな訓練を実現する。
- 多様な医療データセット(cMedQA2、cMedQA-KG、MD-EHR、MEDQA-MCMLE、MedDialog)を組み込み、医療記録をテキスト生成タスクに変換する。
実験結果
リサーチクエスチョン
- RQ1ClinicalGPTは医療会話タスクでOpenモデルと比べてどう評価されるか?
- RQ2ドメイン特化データと報酬ガイド付きファインチューニングが医療知識QA、試験の正確性、診断推論を改善できるか?
- RQ3パラメータ効率的ファインチューニングとRLHFが臨床の信頼性と安全性に与える影響は?
主な発見
- 医療会話で、CLinicalGPTはBLEU-1 13.9、BLEU-2 3.7、BLEU-3 2.0、BLEU-4 1.2、GLEU 0.9、ROUGE-1 27.9、ROUGE-2 6.5、ROUGE-L 21.3を達成。
- 医療検査(診断タスク)を病気群ごとに評価した表では、ClinicalGPTは報告表の平均正確度が37.6%、病気群全体の平均は80.9%に達し、ChatGLM-6B、LLAMA-7B、BLOOM-7Bといった他モデルをTable 6で上回る。
- BLOOM-7B、LLAMA-7B、ChatGLM-6Bに対する医療QA評価で、ClinicalGPTはそれぞれ比較の勝利率が89.7%、85.0%、67.2%となる(BLOOM-7B、LLAMA-7B、ChatGLM-6Bに対する勝利)。
- 診断における病種別の平均性能は、Digestiveが90.1%、Urinaryが89.9%と strongestで、カテゴリーの中でRheumatic immuneが47.4%と最高。
- このフレームワークと結果は、ドメインデータでのLLMファインチューニングと医療タスクにPPOを用いたRLHFの活用で大きな成果が得られることを示唆。
- ClinicalGPTは複数の評価指標でベースラインモデルを上回り、多様な医療データとターゲットを絞った評価の価値を浮き彫りにしている。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。