[論文レビュー] Clinically Accurate Chest X-Ray Report Generation
この論文は、Open-I と MIMIC-CXR 上で Clinically Coherent Reward を用いて最適化された domain-aware, hierarchical chest X-ray report generator を提案し、言語品質と臨床精度の双方を向上させる。
The automatic generation of radiology reports given medical radiographs has significant potential to operationally and improve clinical patient care. A number of prior works have focused on this problem, employing advanced methods from computer vision and natural language generation to produce readable reports. However, these works often fail to account for the particular nuances of the radiology domain, and, in particular, the critical importance of clinical accuracy in the resulting generated reports. In this work, we present a domain-aware automatic chest X-ray radiology report generation system which first predicts what topics will be discussed in the report, then conditionally generates sentences corresponding to these topics. The resulting system is fine-tuned using reinforcement learning, considering both readability and clinical accuracy, as assessed by the proposed Clinically Coherent Reward. We verify this system on two datasets, Open-I and MIMIC-CXR, and demonstrate that our model offers marked improvements on both language generation metrics and CheXpert assessed accuracy over a variety of competitive baselines.
研究の動機と目的
- fluent radiology reports の臨床精度と gap を埋める
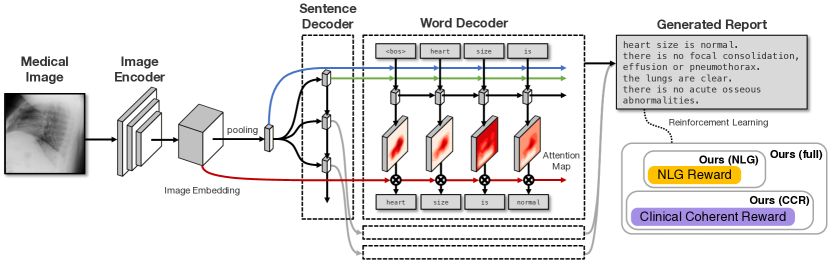
- 階層的 CNN-RNN-RNN ジェネレーターを提案し、トピック駆動の文デコーダで文を作成する
- CheXpert ラベルに基づく Clinically Coherent Reward で疾病状態の言及を真値と整合させる
- 読みやすさと臨床忠実度のバランスを取るように強化学習でモデルを微調整する
- 2 つの公開データセット(Open-I と MIMIC-CXR)を強力な baselines と比較して評価する
提案手法
- 階層的生成: 画像エンコードは CNN、文レベルのトピック生成は LSTM、語彙レベルのデコーディングは attention を用いる
- 各文を文レベルの LSTM から導出されるトピックベクトルで条件付けするトピックガイド付き文生成
- 視覚的セレンティルと画像特徴への注目機構を備えた語デコーダーで各文を生成
- 連結目標を用いた強化学習: CIDEr に基づく NLG 報酬と CheXpert ラベルから導出される Clinically Coherent Reward (CCR) を組み合わせた報酬
- Clinically Coherent Reward は ground-truth と生成レポートを確率的マッピング p(+|l) および p(-|l) の下で比較することにより疾病状態の一貫性をモデル化する(稀な疾患に適した仮定を前提)
- 評価は SCST-型ポリシー勾配を用いて期待報酬を最適化する。ground-truth との整合性が言語の流暢さと臨床精度の両方を推進

実験結果
リサーチクエスチョン
- RQ1階層的な画像→テキストモデルは、流暢さと臨床的正確さの両方を満たす放射線報告を生成できるか?
- RQ2Clinically Coherent Reward の組み込みは CheXpert に基づく疾病状態の整合を向上させつつ、可読性を損なわないか?
- RQ3提案法は大規模胸部X線データセット上で最先端の放射線報告生成ベースラインと比較してどうか?
- RQ4NLG 報酬と CCR 報酬を組み合わせることと、一方だけを最適化することの影響は何か?
主な発見
| Model | CIDEr | ROUGE | BLEU-1 | BLEU-2 | BLEU-3 | BLEU-4 | Accuracy |
|---|---|---|---|---|---|---|---|
| MIMIC-CXR Noise-RNN | 0.716 | 0.272 | 0.269 | 0.172 | 0.113 | 0.074 | 0.803 |
| MIMIC-CXR 1-NN | 0.755 | 0.244 | 0.305 | 0.171 | 0.098 | 0.057 | 0.818 |
| MIMIC-CXR S&T | 0.886 | 0.300 | 0.307 | 0.201 | 0.137 | 0.093 | 0.837 |
| MIMIC-CXR SA&T | 0.967 | 0.288 | 0.318 | 0.205 | 0.137 | 0.093 | 0.849 |
| MIMIC-CXR TieNet | 1.004 | 0.296 | 0.332 | 0.212 | 0.142 | 0.095 | 0.848 |
| MIMIC-CXR Ours (NLG) | 1.153 | 0.307 | 0.352 | 0.223 | 0.153 | 0.104 | 0.834 |
| MIMIC-CXR Ours (CCR) | 0.956 | 0.284 | 0.294 | 0.190 | 0.134 | 0.094 | 0.868 |
| MIMIC-CXR Ours (full) | 1.046 | 0.306 | 0.313 | 0.206 | 0.146 | 0.103 | 0.867 |
| Open-I Noise-RNN | 0.747 | 0.291 | 0.233 | 0.130 | 0.087 | 0.061 | 0.914 |
| Open-I 1-NN | 0.728 | 0.201 | 0.232 | 0.116 | 0.051 | 0.018 | 0.911 |
| Open-I S&T | 0.926 | 0.306 | 0.265 | 0.157 | 0.105 | 0.073 | 0.915 |
| Open-I SA&T | 1.276 | 0.313 | 0.328 | 0.195 | 0.123 | 0.080 | 0.908 |
| Open-I TieNet | 1.334 | 0.311 | 0.330 | 0.194 | 0.124 | 0.081 | 0.902 |
| Open-I Ours (NLG) | 1.490 | 0.359 | 0.369 | 0.246 | 0.171 | 0.115 | 0.916 |
| Open-I Ours (CCR) | 0.707 | 0.244 | 0.162 | 0.084 | 0.055 | 0.036 | 0.917 |
| Open-I Ours (full) | 1.424 | 0.354 | 0.359 | 0.237 | 0.164 | 0.113 | 0.918 |
- 全体モデルは臨床的疾病注釈精度(CheXpert 一致)を最も高く達成しつつ、NLG 指標も堅実に維持している
- NLG に特化した Variante は CIDEr などの言語指標を向上させるが、臨床的正確性の改善は限定的
- CCR のみの Variante は臨床的精度/PPV を高める一方で recall が低下する可能性があり、共同目的の重要性を示唆
- MIMIC-CXR と Open-I の両方で、提案手法は 1-NN、Show & Tell、ShowAtten,& Tell、TieNet を含むベースラインを上回り、言語と臨床指標の両方で優れる
- 後処理で完全に重複する文を削除すると、NLG 指標への影響を最小限に抑えつつ読みやすさが向上する
- アブレーションから、NLG 報酬と CCR 報酬を組み合わせると、言語品質と臨床整合の両方で最も良い総合成績となることが分かる
- Open-I はデータ量が少なく病態の有病率が低いため、MIMIC-CXR と比べてモデルの性能と評価ダイナミクスに影響する
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。