[論文レビュー] Cobra: Extending Mamba to Multi-Modal Large Language Model for Efficient Inference
Cobraは線形時間Mamba状態空間モデルと視覚エンコーダを統合することでマルチモーダルLLMを構築し、競争力のある精度を達成しつつTransformerベースのベースラインより3–4倍高速な推論を実現し、より大規模モデルのパラメータのおよそ43%を使用します。
In recent years, the application of multimodal large language models (MLLM) in various fields has achieved remarkable success. However, as the foundation model for many downstream tasks, current MLLMs are composed of the well-known Transformer network, which has a less efficient quadratic computation complexity. To improve the efficiency of such basic models, we propose Cobra, a linear computational complexity MLLM. Specifically, Cobra integrates the efficient Mamba language model into the visual modality. Moreover, we explore and study various modal fusion schemes to create an effective multi-modal Mamba. Extensive experiments demonstrate that (1) Cobra achieves extremely competitive performance with current computationally efficient state-of-the-art methods, e.g., LLaVA-Phi, TinyLLaVA, and MobileVLM v2, and has faster speed due to Cobra's linear sequential modeling. (2) Interestingly, the results of closed-set challenging prediction benchmarks show that Cobra performs well in overcoming visual illusions and spatial relationship judgments. (3) Notably, Cobra even achieves comparable performance to LLaVA with about 43% of the number of parameters. We will make all codes of Cobra open-source and hope that the proposed method can facilitate future research on complexity problems in MLLM. Our project page is available at: https://sites.google.com/view/cobravlm.
研究の動機と目的
- TransformerベースのMLLMの二次開幕的な複雑さによる効率性の制限を動機づける。
- Cobraアーキテクチャを提案し、マルチモーダル処理のための線形時間状態空間モデル(Mamba)を使用する。
- 視覚情報を効果的に統合するモーダルフュージョン方式を検討する。
- Cobraの標準VLMベンチマークでの競争力のある性能と優れた速度を示す。
- 性能を維持しつつパラメータ数の削減の可能性を示す。
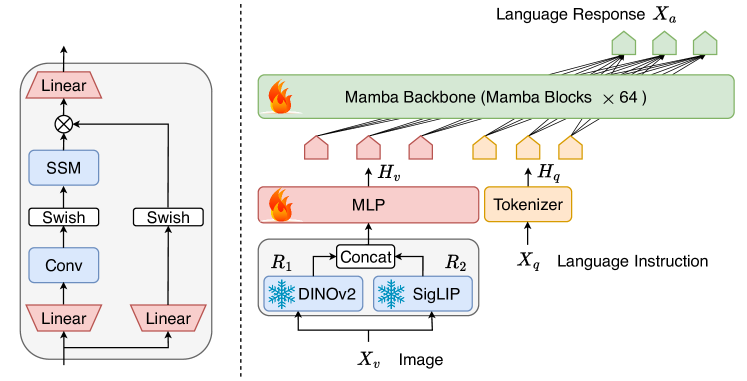
提案手法
- 画像から視覚表現を抽出するための視覚エンコーダースタック(DINOv2 + SigLIP)を使用する。
- 視覚トークンをMambaトークン空間に合わせるためのプロジェクターモジュールを導入する(MLPまたは代替案)。
- 連結された視覚・テキスト埋め込みを自己回帰的に処理するバックボーンとして64ブロックのMambaを採用する。
- 視覚と言語のモダリティをMamba内で統合し、マルチモーダル表現を最適化するさまざまなフュージョン方式を探究する。
- ほぼ1.2Mの画像-テキストサンプルを複数のデータセットで2エポックにわたり全LLMバックボーンとプロジェクターをファインチューニングしてエンドツーエンドで訓練する。
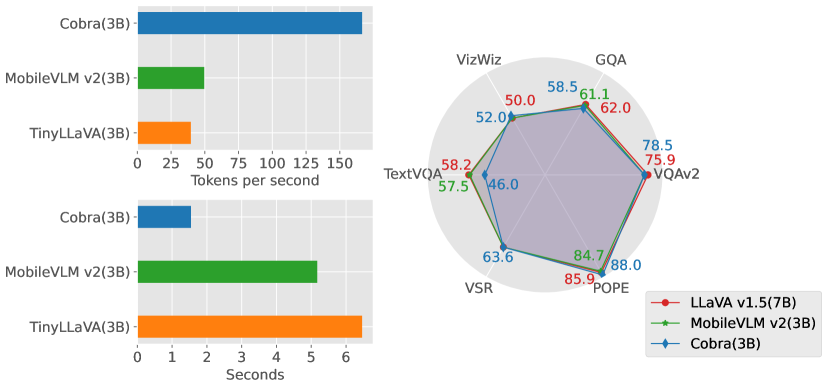
実験結果
リサーチクエスチョン
- RQ1視覚エンコーダと組み合わせた場合、線形時間状態空間モデル(Mamba)はマルチモーダル大規模言語モデルを効果的にサポートできるか。
- RQ2どの視覚エンコーダと投影戦略がCobra内で視覚情報を最も良く保持し、マルチモーダル推論を正確にするか。
- RQ3CobraはオープンエンドVQAおよび閉集合の空間/幻視ベンチマークで、同程度のパラメータ予算のTransformer系と比べてどうか。
- RQ4状態空間バックボーンを採用することで、MLLMの推論速度とメモリ使用量はTransformerベースのベースラインと比べてどの程度改善されるか。
主な発見
| モデル | LLM | VQA_v2 | GQA | VizWiz | VQA_T | VSR | POPE |
|---|---|---|---|---|---|---|---|
| OpenFlamingo | MPT-7B | 52.7 | - | 27.5 | 33.6 | - | - |
| BLIP-2 | Vicuna-13B | - | 41.0 | 19.6 | 42.5 | 50.9 | - |
| MiniGPT-4 | Vicuna-7B | 32.2 | - | - | - | - | - |
| InstructBLIP | Vicuna-7B | - | 49.2 | 34.5 | 50.1 | 54.3 | - |
| InstructBLIP | Vicuna-13B | - | 49.5 | 33.4 | 50.7 | 52.1 | - |
| Shikra | Vicuna-13B | 77.4 | - | - | - | - | - |
| IDEFICS | LLaMA-7B | 50.9 | - | 35.5 | 25.9 | - | - |
| IDEFICS | LLaMA-75B | 60.0 | - | 36.0 | 30.9 | - | - |
| Qwen-VL | Qwen-7B | 78.2 | 59.3 | 35.2 | 63.8 | - | - |
| LLaVA v1.5 | Vicuna-7B | 78.5 | 62.0 | 50.0 | 58.2 | - | 85.9 |
| Prism | LLaMA-7B | 81.0 | 65.3 | 52.8 | 59.7 | 59.6 | 88.1 |
| ShareGPT4V | Vicuna-7B | 80.6 | 57.2 | - | - | - | - |
| MoE-LLaVA | StableLM-1.6B | 76.7 | 60.3 | 36.2 | 50.1 | - | 85.7 |
| MoE-LLaVA | Phi2-2.7B | 77.6 | 61.4 | 43.9 | 51.4 | - | 86.3 |
| Llava-Phi | Phi2-2.7B | 71.4 | - | 35.9 | 48.6 | - | 85.0 |
| MobileVLM v2 | MobileLLaMA-2.7B | - | 61.1 | - | 57.5 | - | 84.7 |
| TinyLLaVA | Phi2-2.7B | 79.9 | 62.0 | - | 59.1 | - | 86.4 |
| Cobra (ours) | Mamba-2.8B | 75.9 | 58.5 | 52.0 | 46.0 | 63.6 | 88.0 |
- Cobraは最先端の効率的な手法(例:LLaVA-Phi、TinyLLaVA、MobileVLM v2)と競争力のある性能を達成し、線形逐次モデリングの利点を享受する。
- Cobraは空間関係判断を含む閉集合タスクでの堅牢性と視覚的幻視の削減において強い丈夫性を示す。
- CobraはLLaVA v1.5 7Bのおよそ43%のパラメータで、いくつかのベンチマークで同等の性能を達成し、効率性の利点を強調する。
- 推論速度はCobraにとって大幅に高速であり(例:同程度の規模でMobileVLM v2およびTinyLLaVAより3倍〜4倍高速)。
- アブレーションにより、DINOv2とSigLIPの組み合わせが結果を改善し、チャット調整済みのMambaモデルをファインチューニングすると指示遵守性能が向上することが示される。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。