[論文レビュー] Cognitive Constraint Simulation and the Geometry of Human Authorship: A First-Principles Theory of AI Text Detection
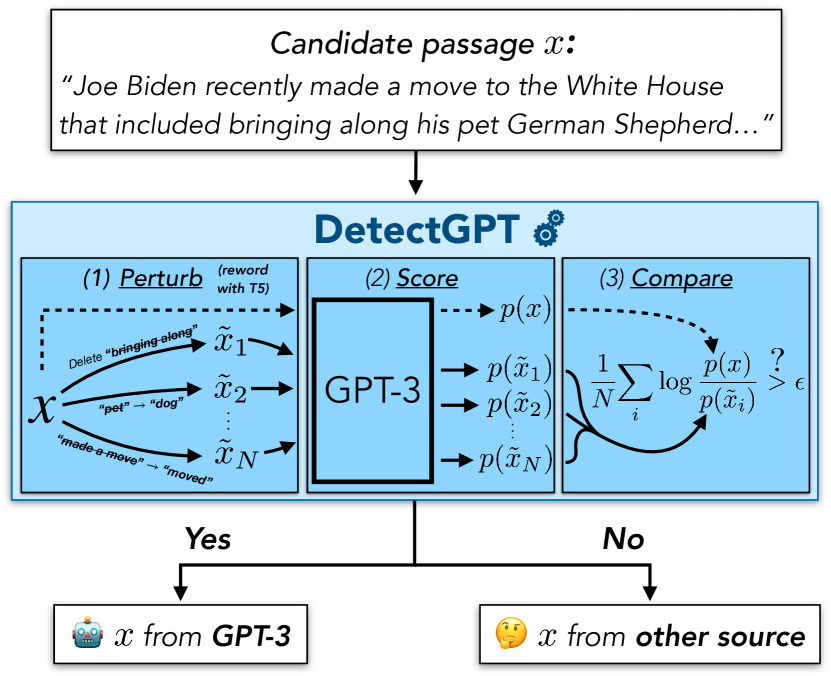
DetectGPTは、モデルの対数確率の局所的な曲率を用いて、現実の/生成済みサンプルで訓練することなく、モデル生成テキストと人間作成テキストを区別するゼロショットのテキスト検出手法を導入します。
The increasing fluency and widespread usage of large language models (LLMs) highlight the desirability of corresponding tools aiding detection of LLM-generated text. In this paper, we identify a property of the structure of an LLM's probability function that is useful for such detection. Specifically, we demonstrate that text sampled from an LLM tends to occupy negative curvature regions of the model's log probability function. Leveraging this observation, we then define a new curvature-based criterion for judging if a passage is generated from a given LLM. This approach, which we call DetectGPT, does not require training a separate classifier, collecting a dataset of real or generated passages, or explicitly watermarking generated text. It uses only log probabilities computed by the model of interest and random perturbations of the passage from another generic pre-trained language model (e.g., T5). We find DetectGPT is more discriminative than existing zero-shot methods for model sample detection, notably improving detection of fake news articles generated by 20B parameter GPT-NeoX from 0.81 AUROC for the strongest zero-shot baseline to 0.95 AUROC for DetectGPT. See https://ericmitchell.ai/detectgpt for code, data, and other project information.
研究の動機と目的
- ゼロショット検出を用いて、特定の言語モデルによって生成されたパッセージかどうかを識別する。
- 機械生成テキストがモデルの log-probability 関数の負の曲率領域を占有するかどうかを調査する。
- 実データ/生成データのラベル付けやテキスト透かしを必要としない、実用的な検出器を開発する。
- 複数のデータセットとモデルサイズにわたり手法を検証し、既存のゼロショットベースラインと比較する。
提案手法
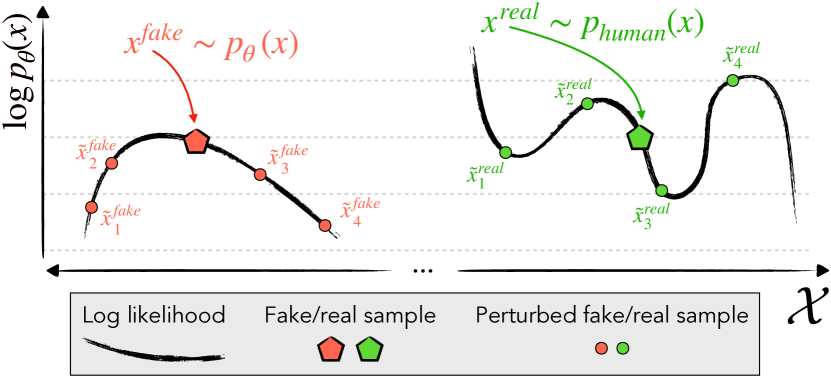
- モデル生成テキストは log p(x) の負の曲率領域に存在すると仮説する。
- Define perturbation discrepancy d(x,p,q) = log p(x) - E_{ ilde{x}~q(.|x)} log p( ilde{x}).
- 曲率を近似するために、Hutchinson のトレース推定量と有限差分を用いて log p(x) のヘシアンの -trace を推定する。
- データ流形上の近くの文章を生成するために、マスク充填 perturbation モデル(例: T5)を使用する。
- 正規化された perturbation discrepancy を計算し、閾値を設けて x が p により生成されたかを判断する。
- ソースモデル p_theta と q からの摂動を用いて x をスコア付けするアルゴリズム DetectGPT を提供し、閾値 epsilon を設定する。
実験結果
リサーチクエスチョン
- RQ1特定のLLM によって生成されたテキストは、人間が書いたテキストよりもモデルの log-probability の負の曲率領域を占有するか?
- RQ2局所的な曲率情報を用いるゼロショット検出器は、グローバルな log-probabilities に依存する既存のゼロショット手法を上回ることができるか?
- RQ3Paraphrasing、異なる perturbation モデル、およびクロスモデルスコアリングのシナリオに対して DetectGPT はどれくらい頑健か?
- RQ4モデル/ perturbation の容量、摂動の量、データドメインが検出性能に与える影響は何か?
主な発見
- DetectGPT は、複数のモデル(1.5B から 20B パラメータ)とドメインにおいて、ゼロショットベースラインより一貫して AUROC を向上させる。
- 負の曲率に関連する perturbation discrepancy は、経験的テストにおいてモデル生成テキストと人間作成テキストを信頼性高く分離する。
- より大きなマスク充填 perturbation モデル(例: T5 系)とより多くの摺动を使用すると、約100摂動で収束するまで検出が改善される。
- 機械生成テキストの paraphrase/修正や異なるデコード戦略下でも検出は強固であり、ゼロショット検出器は一般に教師ありよりドメイン汎用性が高い。
- クロスモデルスコアリングは、同じモデルでスコア付けされたときに DetectGPT が最も効果的であることを示すが、代理スコアラーでも有用性を提供する。
- DetectGPT は、論文に記載されているように、いくつかの設定で最も強力なゼロショットベースラインより約 0.1 の AUROC 改善を達成する。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。